Ebben a leckében meglátjuk, hogy mi az Apache Kafka, és hogyan működik a legelterjedtebb használati eseteivel együtt. Az Apache Kafka-t eredetileg a LinkedIn-ben fejlesztették 2010-ben, és 2012-ben költöztek el legfelsõbb Apache-projektvé. Három fő összetevője van:
- Kiadó-előfizető: Ez az összetevő felelős az adatok hatékony kezeléséért és továbbításáért a Kafka Node-okon és a fogyasztói alkalmazásokon keresztül, amelyek sokat skáláznak (például szó szerint).
- Connect API: A Connect API a leghasznosabb szolgáltatás a Kafka számára, és lehetővé teszi a Kafka integrálását számos külső adatforrással és adatelnyelővel.
- Kafka-patakok: A Kafka adatfolyamok használatával fontolóra vehetjük a bejövő adatok nagymértékű, valós idejű feldolgozását.
Sokkal több Kafka-fogalmat fogunk tanulmányozni a következő szakaszokban. Menjünk előre.
Apache Kafka fogalmak
Mielőtt elmélyülnénk, alaposan át kell gondolnunk az Apache Kafka néhány fogalmát. Itt vannak azok a kifejezések, amelyeket nagyon röviden tudnunk kell:
-
- Termelő: Ez egy olyan alkalmazás, amely üzenetet küld a Kafkának
- Fogyasztó: Ez egy olyan alkalmazás, amely a Kafka adatait használja fel
- Üzenet: A Producer alkalmazás által a Kafka-n keresztül a Consumer alkalmazáshoz küldött adatok
- Kapcsolat: A Kafka TCP kapcsolatot létesít a Kafka fürt és az alkalmazások között
- Téma: A téma egy kategória, amelyhez az elküldött adatokat megcímkézik és eljuttatják az érdeklődő fogyasztói alkalmazásokhoz
- Téma particionálása: Mivel egyetlen téma rengeteg adatot képes egyszerre megszerezni, hogy a Kafka vízszintesen skálázható legyen, minden téma partíciókra oszlik, és minden partíció a fürt bármely csomópont-gépén élhet. Próbáljuk meg bemutatni:
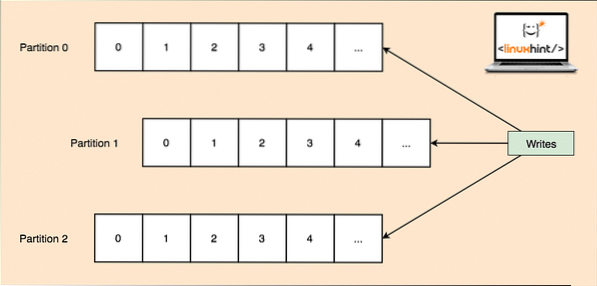
Témapartíciók
- Replikák: Amint azt fentebb tanulmányoztuk, hogy egy téma partíciókra van felosztva, minden üzenetrekordot a fürt több csomópontján replikálnak, hogy fenntartsák az egyes rekordok sorrendjét és adatait arra az esetre, ha az egyik csomópont meghalna.
- Fogyasztói csoportok: Több, ugyanazon téma iránt érdeklődő fogyasztó egy csoportban tartható, amelyet Fogyasztói csoportnak neveznek
- Eltolás: A Kafka skálázható, mivel a fogyasztók tárolják azt az üzenetet, amelyet utoljára letöltöttek "offset" értékként. Ez azt jelenti, hogy ugyanezen témakör esetében az A fogyasztó kompenzációjának értéke 5 lehet, ami azt jelenti, hogy neki a következő hatodik csomagot kell feldolgoznia, a B fogyasztó esetében pedig az offset értéke 7 lehet, ami azt jelenti, hogy a következő csomagot kell feldolgoznia. Ez teljesen kiküszöbölte a témától való függést az egyes fogyasztókra vonatkozó metaadatok tárolásához.
- Csomópont: A csomópont egyetlen kiszolgáló gép az Apache Kafka-fürtben.
- Fürt: A fürt az i csomópontok csoportja.e., szerverek egy csoportja.
A témakör, a topikpartíciók és az ofszet koncepciója szemléltető ábrával is egyértelművé tehető:
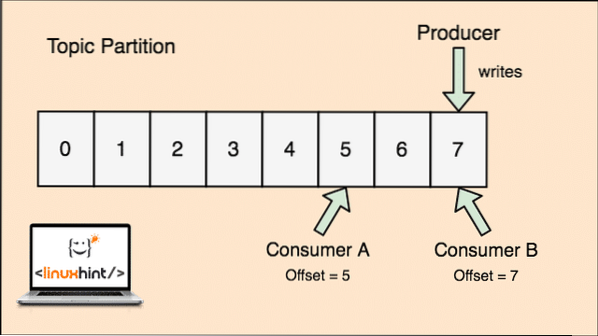
Témafelosztás és fogyasztói kompenzáció Apache Kafkában
Apache Kafka mint közzététel-feliratkozás üzenetkezelő rendszer
A Kafka alkalmazásával a Producer alkalmazások olyan üzeneteket tesznek közzé, amelyek egy Kafka csomóponthoz érkeznek, és nem közvetlenül a fogyasztóhoz. Ebből a Kafka csomópontból az üzeneteket a Consumer alkalmazások fogyasztják.
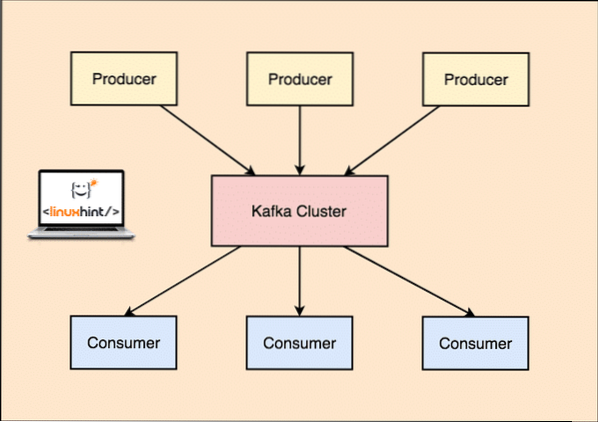
Kafka Producer és Consumer
Mivel egyetlen téma rengeteg adatot képes egyszerre megszerezni, hogy a Kafka vízszintesen skálázható legyen, az egyes témák partíciók és minden partíció a fürt bármely csomópont-gépén élhet.
A Kafka Broker ismét nem vezet nyilvántartást arról, hogy melyik fogyasztó hány adatcsomagot fogyasztott el. Ez a a fogyasztók felelőssége az általa felhasznált adatok nyomon követése. Annak okán, hogy a Kafka nem tartja nyilván az egyes fogyasztói alkalmazások nyugtázását és üzeneteit, sokkal több fogyasztót tud kezelni, elhanyagolható mértékben befolyásolva az áteresztőképességet. A gyártásban sok alkalmazás még a kötegelt fogyasztók mintáját követi, ami azt jelenti, hogy a fogyasztó az összes üzenetet egy sorban, rendszeres időközönként elfogyasztja.
Telepítés
Az Apache Kafka használatának megkezdéséhez telepíteni kell a gépre. Ehhez olvassa el az Apache Kafka telepítése az Ubuntun című cikket.
Felhasználási eset: Webhely-használat követése
A Kafka kiváló eszköz, amelyet akkor kell használni, ha nyomon kell követnünk a tevékenységet egy weboldalon. A nyomonkövetési adatok magukban foglalják, és nem korlátozódnak azokra az oldalmegtekintésekre, keresésekre, feltöltésekre vagy a felhasználók által végrehajtott egyéb műveletekre. Amikor egy felhasználó webhelyen tartózkodik, a felhasználó tetszőleges számú műveletet hajthat végre, amikor szörfözik a webhelyen.
Például, amikor egy új felhasználó regisztrál egy webhelyre, akkor a tevékenység nyomon követhető, hogy az új felhasználó milyen sorrendben tárja fel a webhely jellemzőit, ha a felhasználó szükség szerint beállítja a profilját, vagy inkább közvetlenül áttér a weboldal. Amikor a felhasználó rákattint egy gombra, a gomb metaadatait összegyűjti egy adatcsomagba, és elküldi a Kafka-fürtbe, ahonnan az alkalmazás elemzési szolgáltatása összegyűjtheti ezeket az adatokat, és hasznos betekintést nyújthat a kapcsolódó adatokra. Ha a feladatokat lépésekre szeretnénk osztani, akkor a folyamat így fog kinézni:
- A felhasználó regisztrál egy weboldalon, és belép az irányítópultba. A felhasználó megpróbál azonnal elérni egy funkciót egy gombnyomással.
- A webalkalmazás ezzel a metaadattal létrehoz egy üzenetet a „kattintás” témakör partíciójára.
- Az üzenet a véglegesítési naplóhoz csatolódik, és az eltolás növekszik
- A fogyasztó most kihúzhatja az üzenetet a Kafka Broker-től, és valós időben megmutathatja a weboldal használatát, és megmutathatja a múltbeli adatokat, ha az eltolást visszaállítja egy lehetséges múltbeli értékre
Felhasználási eset: Üzenetsor
Az Apache Kafka kiváló eszköz, amely az üzenetközvetítő eszközök, például a RabbitMQ helyettesítésére szolgál. Az aszinkron üzenetküldés segít az alkalmazások szétválasztásában, és rendkívül skálázható rendszert hoz létre.
A mikroszolgáltatások koncepciójához hasonlóan egy nagy alkalmazás felépítése helyett több részre is fel tudjuk osztani az alkalmazást, és mindegyik résznek nagyon sajátos felelőssége van. Így a különböző részek teljesen független programozási nyelveken is írhatók! A Kafka beépített particionálási, replikációs és hibatűrő rendszerrel rendelkezik, amely nagyszerű üzenetközvetítő rendszerként jó.
A közelmúltban a Kafka egy nagyon jó naplógyűjtési megoldásnak is tekinthető, amely képes kezelni a naplófájl-gyűjtő szerver közvetítőt, és ezeket a fájlokat egy központi rendszerhez juttatja. A Kafka segítségével bármilyen esemény előidézhető, amelyről tudni szeretné az alkalmazás bármely más részéről.
A Kafka használata a LinkedIn-en
Érdekes megemlíteni, hogy az Apache Kafkát korábban úgy tekintették és használták, hogy az adatvezetékeket konzisztenssé tehetik, és amelyek révén az adatok bekerülhetnek a Hadoopba. A Kafka kiválóan dolgozott, amikor több adatforrás és rendeltetési hely volt jelen, és a forrás és a cél egyes kombinációihoz nem volt lehetséges különálló folyamatot biztosítani. Jay Kreps, a LinkedIn Kafka építésze, jól leírja ezt az ismerős problémát egy blogbejegyzésben:
Saját részvételem ebben az ügyben 2008 körül kezdődött, miután kiszállítottuk a kulcsértékű üzletünket. A következő projektem az volt, hogy megpróbáltam elindítani egy működő Hadoop telepítést, és áthelyezni néhány ajánlási folyamatunkat. Kevés tapasztalattal rendelkezünk ezen a területen, természetesen néhány hetet különítettünk el az adatok be- és kiszállítására, a fennmaradó időnket pedig divatos előrejelző algoritmusok megvalósítására. Így kezdődött egy hosszú szlogen.
Apache Kafka és Flume
Ha elmozdul, hogy összehasonlítsa ezt a kettőt a funkcióik alapján, rengeteg közös tulajdonságot talál. Itt van néhány közülük:
- Javasoljuk a Kafka használatát, ha több alkalmazás használja az adatokat a Flume helyett, amely kifejezetten a Hadoop-hoz való integrálásra készült, és csak HDFS-be és HBase-be történő adatok felvételére használható. A Flume a HDFS műveletekre van optimalizálva.
- A Kafka esetében hátrány, hogy kódolni kell a gyártókat és a fogyasztói alkalmazásokat, míg a Flume-ban sok beépített forrás és mosogató van. Ez azt jelenti, hogy ha a meglévő igények megegyeznek a Flume funkcióival, javasoljuk, hogy időt takarítson meg a Flume használatával.
- A Flume interceptorok segítségével repülés közbeni adatokat is felhasználhat. Fontos lehet az adatok maszkolása és szűrése szempontjából, míg a Kafkának külső adatfolyam-feldolgozó rendszerre van szüksége.
- Lehetséges, hogy a Kafka a Flume-ot fogyasztóként használja, amikor adatokat kell bevinni a HDFS-be és a HBase-be. Ez azt jelenti, hogy Kafka és Flume nagyon jól integrálódik.
- A Kakfa és a Flume nulla adatvesztést garantál a helyes konfigurációval, amelyet szintén könnyű elérni. Mégis, hangsúlyozandó, hogy a Flume nem replikálja az eseményeket, ami azt jelenti, hogy ha az egyik Flume csomópont meghibásodik, akkor elveszítjük az eseményekhez való hozzáférést, amíg a lemezt helyre nem állítjuk
Következtetés
Ebben a leckében számos fogalmat néztünk meg Apache Kafkáról. További Kafka-alapú bejegyzéseket itt olvashat.


