Adattudomány
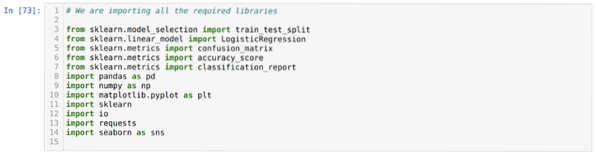
Logisztikai regresszió a Pythonban
A logisztikai regresszió gépi tanulási osztályozási algoritmus. A logisztikai regresszió is hasonló a lineáris regresszióhoz. De a fő különbség a logi...
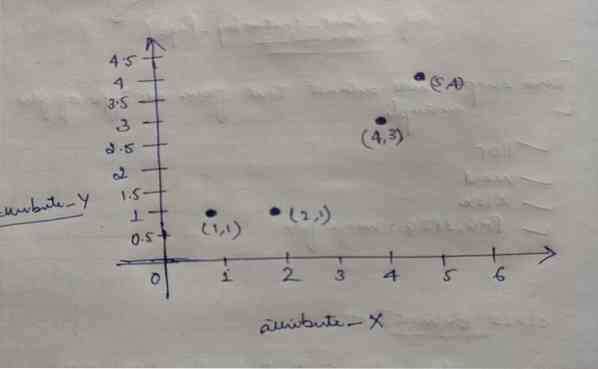
K-klaszterezés
A blog kódja és az adatkészlet a következő https: // github linken érhető el.com / shekharpandey89 / k-mean A K-Means klaszter felügyelet nélküli gépi...

Pivot tábla létrehozása a Pandas Pythonban
A panda pythonjában a Pivot tábla összegez, számlál vagy összesít függvényeket tartalmaz, amelyek egy adattáblából származnak. Az összesítő függvények...
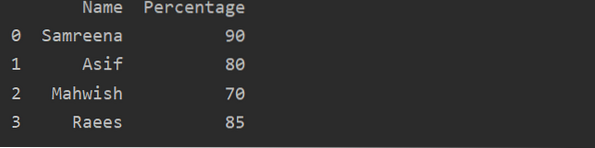
Hogyan lehet Pandas DataFrame-et létrehozni a Pythonban?
A Pandas DataFrame egy 2D-s (kétdimenziós) megjegyzésekkel ellátott adatstruktúra, amelyben az adatok táblázatos formában, különböző sorokkal és oszlo...
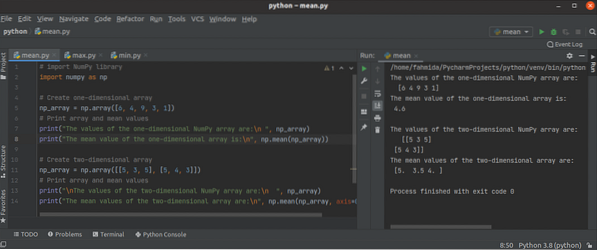
A Python NumPy mean (), min () és max () függvények használata?
A Python NumPy könyvtár számos összesítő vagy statisztikai funkcióval rendelkezik a különböző típusú feladatok elvégzéséhez az egydimenziós vagy többd...
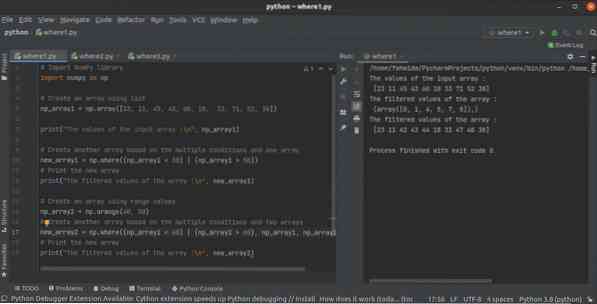
A python NumPy where () függvény használata több feltétellel
A NumPy könyvtárnak számos funkciója van a tömb létrehozására a pythonban. ahol a () függvény az egyik, hogy egy másik NumPy tömbből tömböt hozzon lét...
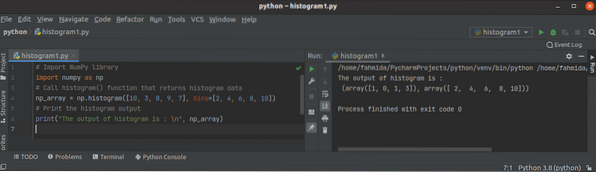
Python NumPy hisztogram () oktatóanyag
A hisztogram az intervallumok frekvenciákhoz való hozzárendelése. Az adott változó valószínűségi sűrűségfüggvényének közelítésére szolgál. Ez oszlopdi...
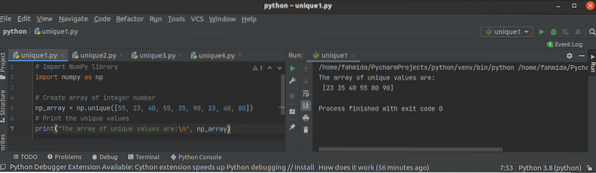
A Python NumPy egyedi () függvény használata
A NumPy könyvtárat a pythonban egy vagy több dimenziós tömb létrehozásához használják, és számos funkciója van a tömbhöz. Az egyedi () függvény a köny...
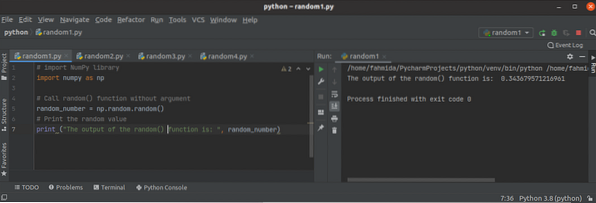
A Python NumPy véletlenszerű függvény használata?
Amikor a szám értéke megváltozik a szkript minden végrehajtásakor, akkor ezt a számot véletlenszerű számnak hívjuk. A véletlenszerű számokat elsősorba...


