Pandák .read_csv
Már tárgyaltam a Python könyvtár pandák történetének és felhasználásának egy részéről. A pandákat abból a célból tervezték, hogy hatékony pénzügyi elemzési és manipulációs könyvtárra van szükség a Python számára. Az adatok elemzésre és manipulációra való betöltése érdekében a pandák két módszert kínálnak, DataReader és read_csv. Itt ismertettem az elsőt. Ez az oktatóanyag témája.
.read_csv
Számos ingyenes online adattár található online, amelyek különböző területeken tartalmaznak információkat. Ezen források egy részét belefoglaltam az alábbi referencia szakaszba. Mivel bemutattam a beépített API-kat a pénzügyi adatok ideális lekérdezéséhez, egy másik adatforrást fogok használni ebben az oktatóanyagban.
Adat.A gov hatalmas mennyiségű ingyenes adatot kínál az éghajlatváltozástól az U-ig.S. gyártási statisztikák. Két adatkészletet töltöttem le, hogy felhasználhassam ezt az oktatóanyagot. Az első a floridai Bay megye átlagos napi maximális hőmérséklete. Ezeket az adatokat letöltötték az U-ról.S. Climate Resilience Toolkit az 1950-től napjainkig terjedő időszakra.
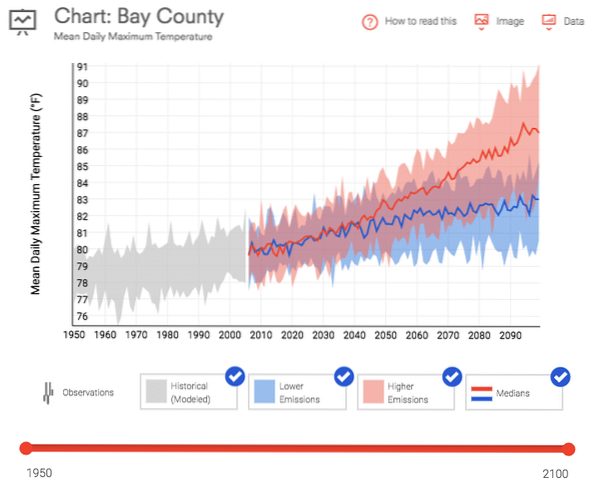
A második az áruáramlás-felmérés, amely 5 éven keresztül méri az országba irányuló behozatal módját és mennyiségét.

Ezen adatsorok mindkét linkjét az alábbi referencia szakasz tartalmazza. A .read_csv metódus, amint az a névből is kitűnik, betölti ezeket az információkat egy CSV fájlból, és példányosítja a DataFrame abból az adatkészletből.
Használat
Bármikor, amikor külső könyvtárat használ, el kell mondania a Pythonnak, hogy importálni kell. Az alábbiakban látható a kódsor, amely a pandás könyvtárat importálja.
import pandák, mint pdA .read_csv módszer alatt van. Ez példázza és feltölti a DataFrame df a CSV fájlban található információkkal.
df = pd.read_csv ('12005-éves-hist-obsz-tasmax.csv ')Néhány további sor hozzáadásával megvizsgálhatjuk az újonnan létrehozott DataFrame első és utolsó 5 sorát.
df = pd.read_csv ('12005-éves-hist-obsz-tasmax.csv ')nyomtatás (df.fej (5))
nyomtatás (df.farok (5))

A kód betöltött egy oszlopot egy évre, a napi átlagos hőmérsékletet Celsiusban (tasmax), és elkészített egy 1 alapú indexelési sémát, amely az egyes adatsorokra növekszik. Fontos megjegyezni azt is, hogy a fejlécek a fájlból kerülnek feltöltésre. A fent bemutatott módszer alapvető használatával arra lehet következtetni, hogy a fejlécek a CSV-fájl első sorában találhatók. Ezt úgy lehet megváltoztatni, hogy egy másik paraméterkészletet adunk át a módszernek.
Paraméterek
Megadtam a linket a pandákra .read_csv dokumentáció az alábbi hivatkozásokban. Számos paraméter használható az adatok olvasási és formázási módjának megváltoztatására DataFrame.

A paraméterhez szép számmal vannak paraméterek .read_csv módszer. A legtöbbre nincs szükség, mert a legtöbb letöltött adatkészlet szabványos formátumú lesz. Ez az oszlopok az első sorban és egy vessző elválasztó.
Van néhány paraméter, amelyeket kiemelek az oktatóanyagban, mert hasznosak lehetnek. Átfogóbb felmérés készíthető a dokumentáció oldaláról.
index_col
index_col olyan paraméter, amely az indexet tartó oszlop megjelölésére használható. Egyes fájlok tartalmazhatnak indexet, mások pedig nem. Első adatsorunkban hagytam, hogy a python indexet hozzon létre. Ez a szabvány .read_csv viselkedés.
Második adatsorunkban egy index szerepel. Az alábbi kód betölti a DataFrame a CSV fájlban szereplő adatokkal, de növekményes egész alapú index létrehozása helyett az adatkészletben szereplő SHPMT_ID oszlopot használja.
df = pd.read_csv ('cfs_2012_pumf_csv.txt ', index_col =' SHIPMT_ID ')nyomtatás (df.fej (5))
nyomtatás (df.farok (5))
Míg ez az adatkészlet ugyanazt a sémát használja az indexhez, más adatkészleteknél hasznosabb index lehet.
üregek, átugrók, usecols
Nagy adathalmazokkal csak az adatok szakaszait szeretné betölteni. A nrows, skiprows, és usecols A paraméterek lehetővé teszik a fájlban lévő adatok szeletelését.
df = pd.read_csv ('cfs_2012_pumf_csv.txt ', index_col =' SHIPMT_ID ', nrows = 50)nyomtatás (df.fej (5))
nyomtatás (df.farok (5))
A nrows paraméter, amelynek egész értéke 50, a .a farokhívás most 50-ig tér vissza. A fájl többi adatát nem importálja.
nyomtatás (df.fej (5))
nyomtatás (df.farok (5))
A skiprows paraméter, a mi .fej A col nem mutatja a 1001 kezdő indexet az adatokban. Mivel kihagytuk a fejléc sort, az új adatok elveszítették a fejlécet és az indexet a fájladatok alapján. Bizonyos esetekben jobb lehet az adatok szeletelése a DataFrame nem pedig az adatok betöltése előtt.

A usecols egy hasznos paraméter, amely lehetővé teszi az adatok csak oszloponkénti importálását. Át lehet adni egy nulladik indexet vagy egy oszlopneveket tartalmazó karakterlánc-listát. Az alábbi kód segítségével importáltam az első négy oszlopot az újba DataFrame.
df = pd.read_csv ('cfs_2012_pumf_csv.txt ',index_col = 'SHIPMT_ID',
számok = 50, usecols = [0,1,2,3])
nyomtatás (df.fej (5))
nyomtatás (df.farok (5))
Újunktól .fej hívás, mi DataFrame most már csak az adatkészlet első négy oszlopát tartalmazza.
motor
Egy utolsó paraméter, amely szerintem jól jönne néhány adatkészletben, a motor paraméter. Használhatja a C alapú motort vagy a Python alapú kódot. A C motor természetesen gyorsabb lesz. Ez fontos, ha nagy adatkészleteket importál. A Python elemzés előnyei a funkciókban gazdagabb készlet. Ez az előny kevesebbet jelenthet, ha nagyméretű adatot tölt be a memóriába.
df = pd.read_csv ('cfs_2012_pumf_csv.txt ',index_col = 'SHIPMT_ID', motor = 'c')
nyomtatás (df.fej (5))
nyomtatás (df.farok (5))
Utánkövetés
Számos más paraméter is kiterjesztheti a .read_csv módszer. Megtalálhatók a docs oldalon, amelyre az alábbiakban hivatkoztam. .read_csv egy hasznos módszer az adatkészletek pandákba történő betöltésére az adatok elemzéséhez. Mivel az interneten számos ingyenes adatkészlet nem rendelkezik API-val, ez a pénzügyi adatokon kívüli alkalmazások számára lesz a leghasznosabb, ahol robusztus API-k vannak az adatok pandákba történő importálásához.
Hivatkozások
https: // pandák.pydata.org / pandas-docs / stabil / generált / pandák.read_csv.html
https: // www.adat.kormány /
https: // eszköztár.éghajlat.kormány / # klíma-felfedező
https: // www.népszámlálás.gov / econ / cfs / pums.html


