1. rész: Egyetlen csomópont beállítása
Ma a dokumentumok vagy adatok elektronikus tárolása egy tárolóeszközön egyszerre gyors és egyszerű, és viszonylag olcsó is. Használatban van egy fájlnév hivatkozás, amely leírja a dokumentumot. Alternatív megoldásként az adatokat olyan adatbázis-kezelő rendszerben (DBMS) tárolják, mint a PostgreSQL, a MariaDB vagy a MongoDB, hogy csak néhány lehetőséget említsünk. Számos adathordozó van lokálisan vagy távolról csatlakoztatva a számítógéphez, például USB-meghajtó, belső vagy külső merevlemez, Hálózati csatolt tároló (NAS), Felhőtároló vagy GPU / Flash-alapú, mint egy Nvidia V100-ban [10].
Ezzel szemben a fordított folyamat, a megfelelő dokumentumok megtalálása egy dokumentumgyűjteményben, meglehetősen összetett. Leginkább a fájlformátum hibamentes felderítését, a dokumentum indexelését és a kulcsfogalmak kibontását igényli (dokumentum besorolás). Itt jön be az Apache Solr keretrendszer. Praktikus felületet kínál az említett lépések elvégzéséhez - dokumentumindex felépítése, keresési lekérdezések elfogadása, a tényleges keresés végrehajtása és a keresési eredmények visszaadása. Az Apache Solr tehát az adatbázis vagy dokumentumtároló hatékony kutatásának alapját képezi.
Ebben a cikkben megtudhatja, hogyan működik az Apache Solr, hogyan állíthat be egyetlen csomópontot, indexelheti a dokumentumokat, kereshet és lekérheti az eredményt.
A nyomonkövetési cikkek erre építenek, és ezekben más, konkrétabb felhasználási eseteket is megvitatunk, például a PostgreSQL DBMS integrálását adatforrásként vagy a terheléselosztás több csomóponton keresztül.
Az Apache Solr projektről
Az Apache Solr egy keresőmotoros keretrendszer, amely a nagy teljesítményű Lucene keresési indexszerveren alapszik [2]. Java nyelven írva az Apache Software Foundation (ASF) égisze alatt működik [6]. Az Apache 2 licenc alatt szabadon elérhető.
A „Dokumentumok és adatok újbóli keresése” témakör nagyon fontos szerepet játszik a szoftvervilágban, és sok fejlesztő intenzíven foglalkozik vele. Az Awesomeopensource [4] weboldal több mint 150 nyílt forráskódú keresőmotort tartalmaz. 2021 elején az ElasticSearch [8] és az Apache Solr / Lucene a két legfontosabb kutya, amikor nagyobb adathalmazokat kell keresni. A keresőmotor fejlesztése sok tudást igényel, Frank ezt a Python-alapú AdvaS Advanced Search [3] könyvtárral teszi meg 2002 óta.
Az Apache Solr beállítása:
Az Apache Solr telepítése és működtetése nem bonyolult, egyszerűen csak egy sor lépést kell végrehajtania. Hagyjon körülbelül 1 órát az első adatkérdezés eredményére. Ezenkívül az Apache Solr nemcsak hobbi projekt, hanem professzionális környezetben is használható. Ezért a választott operációs rendszer környezetet hosszú távú használatra tervezték.
A cikk alapkörnyezetéül a Debian GNU / Linux 11-et használjuk, amely a (2021 elején) megjelenő Debian kiadás, és várhatóan 2021 közepén lesz elérhető. Ehhez az oktatóanyaghoz azt várjuk, hogy már telepítette - akár natív rendszerként - egy virtuális gépbe, mint például a VirtualBox, vagy egy AWS-tárolóba.
Az alapkomponenseken kívül a következő szoftvercsomagokra van szükség a rendszerre:
- Becsavar
- Default-java
- Libcommons-cli-java
- Libxerces2-java
- Libtika-java (könyvtár az Apache Tika projektből [11])
Ezek a csomagok a Debian GNU / Linux standard elemei. Ha még nincs telepítve, akkor egyszerre utólag telepítheti őket rendszergazdai jogokkal rendelkező felhasználóként, például root vagy sudo segítségével, az alábbiak szerint:
# apt-get install curl alapértelmezett -java libcommons-cli-java libxerces2-java libtika-javaA környezet előkészítése után a 2. lépés az Apache Solr telepítése. Mostantól az Apache Solr nem érhető el normál Debian csomagként. Ezért szükséges az Apache Solr 8 letöltése.8 a projekt honlapjának letöltési szakaszából [9]. Az alábbi wget paranccsal tárolhatja a rendszer / tmp könyvtárában:
$ wget -O / tmp https: // letöltések.apache.org / lucene / solr / 8.8.0 / solr-8.8.0.tgzAz -O kapcsoló lerövidíti az -output-dokumentumot, és a wget tárolja a lekért tar-t.gz fájl az adott könyvtárban. Az archívum mérete nagyjából 190 millió. Ezután csomagolja ki az archívumot a / opt könyvtárba a tar segítségével. Ennek eredményeként két alkönyvtárat talál - / opt / solr és / opt / solr-8.8.0, míg az / opt / solr szimbolikus linkként van beállítva az utóbbihoz. Az Apache Solr egy telepítő szkriptet tartalmaz, amelyet a következő lépésben hajt végre: a következő:
# / opt / solr-8.8.0 / bin / install_solr_service.SHEnnek eredményeként létrejön a Linux felhasználói Solr futtatása a Solr szolgáltatásban, valamint a / var / solr alatt található saját könyvtár létrehozza a Solr szolgáltatást, hozzáadva a megfelelő csomópontokkal, és elindítja a Solr szolgáltatást a 8983-as porton. Ezek az alapértelmezett értékek. Ha nem vagy elégedett velük, módosíthatod őket a telepítés során, vagy akár késleltetheti is, mivel a telepítési parancsfájl elfogadja a megfelelő kapcsolókat a beállítások beállításához. Javasoljuk, hogy olvassa el az Apache Solr dokumentációját ezekről a paraméterekről.
A Solr szoftver a következő könyvtárakba szerveződik:
- kuka
tartalmazza a Solr bináris fájlokat és fájlokat a Solr szolgáltatásként történő futtatásához - közreműködés
külső Solr könyvtárak, például adatimportálók és a Lucene könyvtárak - ker
belső Solr könyvtárak - docs
link az online elérhető Solr dokumentációhoz - példa
példa adatkészletek vagy több felhasználási eset / forgatókönyv - engedélyek
szoftverlicencek a Solr különféle komponenseihez - szerver
szerver konfigurációs fájlok, például szerver / stb a szolgáltatásokhoz és portokhoz
Ezekről a könyvtárakról részletesebben az Apache Solr dokumentációjában olvashat [12].
Az Apache Solr kezelése:
Az Apache Solr szolgáltatásként fut a háttérben. Kétféleképpen indíthatja el, vagy a systemctl (első sor) használatával rendszergazdai jogosultsággal rendelkező felhasználóként, vagy közvetlenül a Solr könyvtárból (második sor). Az alábbiakban felsoroljuk mindkét terminálparancsot:
# systemctl start solr$ solr / bin / solr start
Az Apache Solr leállítása hasonlóan történik:
# systemctl stop solr$ solr / bin / solr stop
Ugyanez vonatkozik az Apache Solr szolgáltatás újraindítására:
# systemctl restart solr$ solr / bin / solr újraindítás
Ezenkívül az Apache Solr folyamat állapota a következőképpen jeleníthető meg:
# systemctl status solr$ solr / bin / solr állapot
A kimenet felsorolja az elindított szolgáltatásfájlt, mind a megfelelő időbélyegzőt, mind a naplóüzeneteket. Az alábbi ábra azt mutatja, hogy az Apache Solr szolgáltatást a 8983-as porton indították el a 632-es folyamattal. A folyamat sikeresen fut 38 percig.
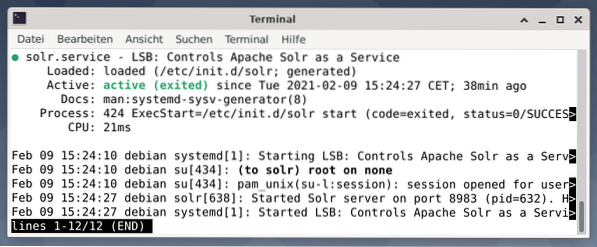
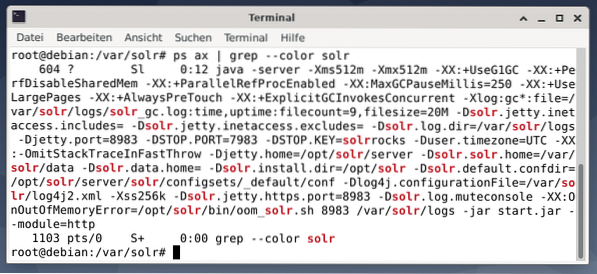
Annak ellenőrzésére, hogy az Apache Solr folyamat aktív-e, ellenőrizheti a ps paranccsal együtt a grep-lel is. Ez korlátozza a ps kimenetet az összes Apache Solr folyamatra, amely jelenleg aktív.
# ps ax | grep --color solrAz alábbi ábra ezt egyetlen eljárással szemlélteti. Megjelenik a Java hívása, amelyet a paraméterek listája kísér, például a memóriahasználati (512M) portok a 8983-as lekérdezésekhez, a 7983 a leállítási kérésekhez és a kapcsolat típusa (http).
Felhasználók hozzáadása:
Az Apache Solr folyamatok egy adott felhasználóval, akinek a neve Solr. Ez a felhasználó hasznos a Solr folyamatok kezelésében, az adatok feltöltésében és a kérések küldésében. A telepítés után a felhasználói solr-nak nincs jelszava, és várhatóan lesz belépője a továbblépéshez. Állítson be egy jelszót a felhasználói solrhoz hasonlóan, mint a root root, ez a következőképpen jelenik meg:
# passwd solrSolr adminisztráció:
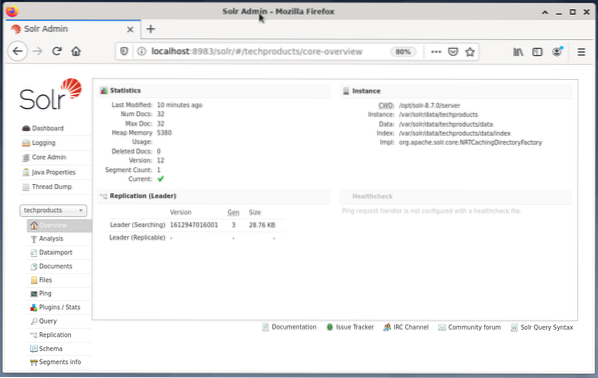
Az Apache Solr kezelése a Solr irányítópult segítségével történik. Ez elérhető a webböngészőn keresztül a http: // localhost: 8983 / solr címen. Az alábbi ábra a fő nézetet mutatja.
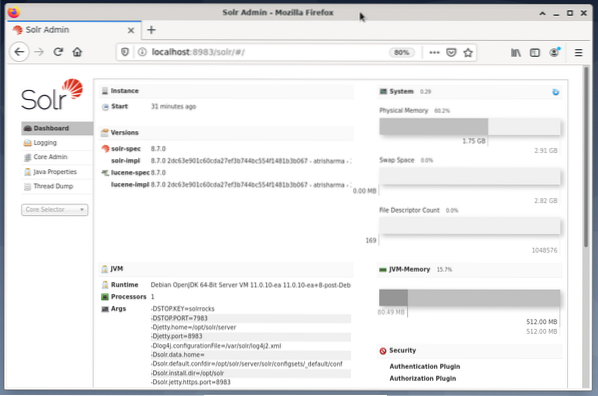
A bal oldalon látható a főmenü, amely a naplózás, a Solr-magok adminisztrációja, a Java-beállítások és az állapotinformációk alszakaszaihoz vezet. Válassza ki a kívánt magot a menü alatti jelölőnégyzet segítségével. A menü jobb oldalán a megfelelő információk jelennek meg. Az Irányítópult menüpont az Apache Solr folyamat további részleteit, valamint az aktuális terhelést és memóriahasználatot mutatja be.
Kérjük, vegye figyelembe, hogy az Irányítópult tartalma a Solr magok számától és az indexelt dokumentumoktól függően változik. A változtatások mind a menüpontokat, mind a jobb oldalon látható megfelelő információkat befolyásolják.
A keresőmotorok működésének megértése:
Egyszerűen szólva a keresőmotorok elemzik a dokumentumokat, kategorizálják őket, és lehetővé teszik, hogy a kategóriák alapján végezzen keresést. Alapvetően a folyamat három szakaszból áll, amelyeket feltérképezésnek, indexelésnek és rangsorolásnak neveznek [13].
Csúszó az első szakasz, és leírja az új és frissített tartalmak gyűjtésének folyamatát. A keresőmotor robotokat használ, amelyek más néven pókok vagy bejárók, ezért a feltérképezés kifejezés a rendelkezésre álló dokumentumok áttekintéséhez.
A második szakasz neve indexelés. A korábban összegyűjtött tartalmat kereshetővé teszi az eredeti dokumentumok átalakítása a kereső által érthető formátumba. A kulcsszavakat és fogalmakat kibontják és (masszív) adatbázisokban tárolják.
A harmadik szakasz neve rangsor és leírja a keresési eredmények rendezésének folyamatát azok relevanciája szerint egy keresési lekérdezéssel. Gyakori, hogy az eredményeket csökkenő sorrendben jelenítsük meg, hogy az első legyen a kereső lekérdezésének leginkább releváns eredmény.
Az Apache Solr a korábban leírt háromlépcsős folyamathoz hasonlóan működik. A népszerű Google keresőmotorhoz hasonlóan az Apache Solr is használja a különböző forrásokból származó dokumentumok összegyűjtésének, tárolásának és indexelésének sorrendjét, és elérhetővé / kereshetővé teszi őket közel valós időben.
Az Apache Solr különböző módszerekkel használja a dokumentumok indexelését, beleértve a következőket [14]:
- Indexkérés-kezelő használata, amikor a dokumentumokat közvetlenül a Solr-ba tölti fel. Ezeknek a dokumentumoknak JSON, XML / XSLT vagy CSV formátumban kell lenniük.
- Az Extracting Request Handler (Solr Cell) használata. A dokumentumoknak PDF vagy Office formátumban kell lenniük, amelyeket az Apache Tika támogat.
- A Data Import Handler használatával, amely adatokat továbbít egy adatbázisból, és oszlopnevek segítségével katalogizálja azokat. Az Adatimportál-kezelő e-mailekből, RSS-hírcsatornákból, XML-adatokból, adatbázisokból és egyszerű szöveges fájlokból nyeri az adatokat forrásként.
Lekérdezéskezelőt használ az Apache Solr, amikor keresési kérelmet küld. A lekérdezéskezelő az adott lekérdezést az indexkezelő ugyanazon koncepciója alapján elemzi, hogy megfeleljen a lekérdezésnek és a korábban indexelt dokumentumoknak. A mérkőzéseket megfelelőségük vagy relevanciájuk szerint rangsorolják. Az alábbiakban a lekérdezés rövid példáját mutatjuk be.
Dokumentumok feltöltése:
Az egyszerűség kedvéért egy minta adatkészletet használunk a következő példához, amelyet az Apache Solr már biztosított. A dokumentumok feltöltése felhasználói szolrként történik. Az 1. lépés egy mag létrehozása a techproducts névvel (számos techikai cikkhez).
$ solr / bin / solr -c techtermékek létrehozása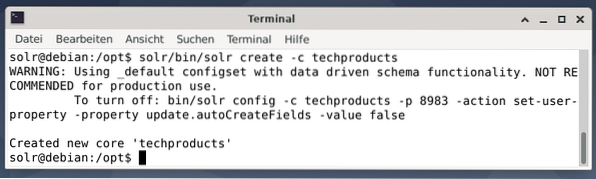
Minden rendben van, ha megjelenik az „Új alapvető technológiai termékek létrehozása” üzenet. A 2. lépés hozzáadja az adatokat (XML-adatok a példázott dokumentumokról) a korábban létrehozott alapvető technológiai termékekhez. Használatban van az -c (a mag neve) paraméterezésű eszközbejegyzés és a feltöltendő dokumentumok.
$ solr / bin / post -c techproducts solr / példa / exampledocs / *.xmlEz az alább látható kimenetet eredményezi, és tartalmazza a teljes hívást, valamint az indexelt 14 dokumentumot.
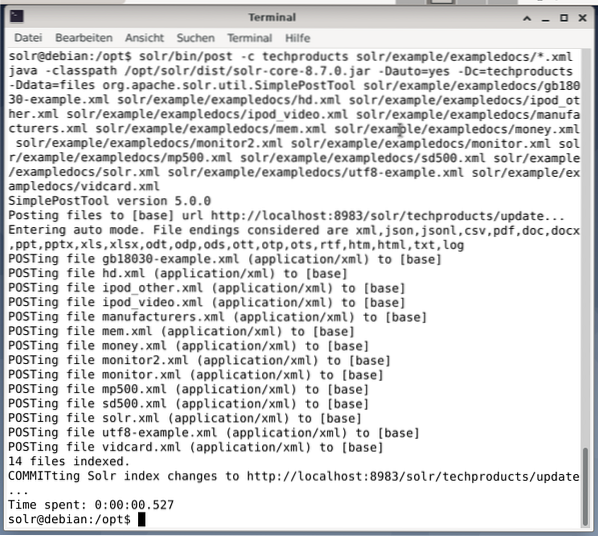
Ezenkívül az Irányítópult mutatja a változásokat. A bal oldali legördülő menüben egy új, techproducts nevű bejegyzés látható, a jobb oldalon pedig megváltozott a megfelelő dokumentumok száma. Sajnos a nyers adatkészletek részletes áttekintése nem lehetséges.
Abban az esetben, ha a magot / gyűjteményt el kell távolítani, használja a következő parancsot:
$ solr / bin / solr delete -c techtermékekAdatok lekérdezése:
Az Apache Solr két felületet kínál az adatok lekérdezéséhez: a webalapú irányítópulton és a parancssoron keresztül. Az alábbiakban mindkét módszert elmagyarázzuk.
Lekérdezések küldése a Solr műszerfalon keresztül az alábbiak szerint történik:
- Válassza ki a csomópont technikai termékeit a legördülő menüből.
- Válassza a Lekérdezés bejegyzést a legördülő menü alatti menüből.
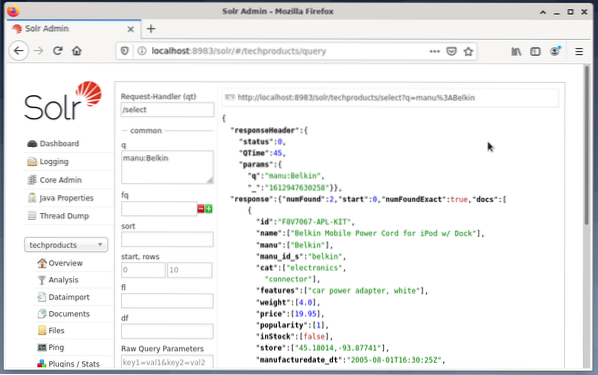
A beviteli mezők a jobb oldalon jelennek meg a lekérdezés megfogalmazásához, például a kérelemkezelő (qt), a lekérdezés (q) és a rendezési sorrend (rendezés). - Válassza a Lekérdezés mezőt, és változtassa meg a bejegyzés tartalmát „*: *” értékről „manu: Belkin” értékre. Ez korlátozza a keresést az „összes mező, minden bejegyzéssel”, a „Belkin nevű adatkészletekre a manuális mezőben” kifejezésre. Ebben az esetben a manu név rövidíti a gyártót a példa adatkészletben.
- Ezután nyomja meg az Execute Query gombot. Az eredmény egy kinyomtatott HTTP-kérelem a tetején, és a keresési lekérdezés eredménye JSON-formátumban alább.
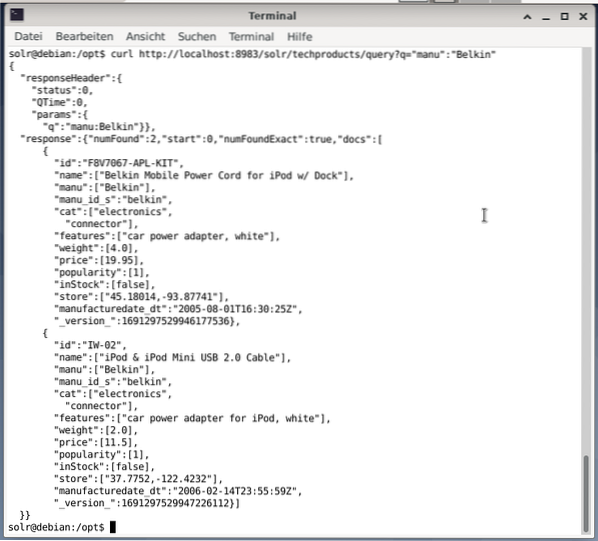
A parancssor ugyanazt a lekérdezést fogadja el, mint az Irányítópulton. A különbség az, hogy ismernie kell a lekérdezési mezők nevét. Ahhoz, hogy ugyanazt a lekérdezést küldhesse, mint fent, a következő parancsot kell futtatnia a terminálban:
$ göndörhttp: // localhost: 8983 / solr / techproducts / query?q = ”manu”: ”Belkin
A kimenet JSON formátumban van, az alábbiak szerint. Az eredmény egy válasz fejlécből és a tényleges válaszból áll. A válasz két adatsorból áll.
Csomagolás:
Gratulálunk! Az első szakaszt sikerrel érted el. Az alapvető infrastruktúra be van állítva, és megtanulta a dokumentumok feltöltését és lekérdezését.
A következő lépés a lekérdezés finomításának, összetettebb lekérdezések megfogalmazásának és az Apache Solr lekérdezési oldal által biztosított különféle webes űrlapok megértésének módját tárgyalja. Ezenkívül megvitatjuk a keresési eredmények utólagos feldolgozását különböző kimeneti formátumok, például XML, CSV és JSON használatával.
A szerzőkről:
Jacqui Kabeta környezetvédő, lelkes kutató, oktató és mentor. Több afrikai országban dolgozott az informatikai iparban és a civil szervezetek környezetében.
Frank Hofmann informatikai fejlesztő, oktató és szerző, és inkább Berlinből, Genfből és Fokvárosból dolgozik. A Debian Csomagkezelő Könyv társszerzője a dpmb oldalon érhető el.org
- [1] Apache Solr, https: // lucén.apache.org / solr /
- [2] Lucene Search Library, https: // lucene.apache.org /
- [3] AdvaS Advanced Search, https: // pypi.org / project / AdvaS-Advanced-Search /
- [4] A legjobb 165 keresőmotor nyílt forráskódú projektje, https: // awesomeopensource.com / projektek / keresőmotor
- [5] ElasticSearch, https: // www.rugalmas.co / de / elasticsearch /
- [6] Apache Software Foundation (ASF), https: // www.apache.org /
- [7] FESS, https: // fess.codelibek.org / index.html
- [8] ElasticSearch, https: // www.rugalmas.kód/
- [9] Apache Solr, Letöltés szakasz, https: // lucene.apache.org / solr / letöltések.htm
- [10] Nvidia V100, https: // www.nvidia.hu / hu-us / data-center / v100 /
- [11] Apache Tika, https: // tika.apache.org /
- [12] Apache Solr könyvtár elrendezése, https: // lucene.apache.org / solr / guide / 8_8 / installation-solr.html # könyvtár-elrendezés
- [13] Hogyan működnek a keresőmotorok: Feltérképezés, indexelés és rangsorolás. A SEO kezdők útmutatója https: // moz.com / kezdőknek szóló útmutató a SEO-hoz / hogyan működnek a keresőmotorok
- [14] Kezdő lépések az Apache Solr alkalmazással, https: // sematext.com / guides / solr / #: ~: text = Solr% 20works% 20by% 20gathering% 2C% 20storing,% 20huge% 20volumes% 20of% 20data


