Az R lefordítása és futtatása a parancssorból
Az R programok futtatásának két módja: egy széles körben használt és legelőnyösebb R szkript, a második pedig az R CMD BATCH, ez nem általánosan használt parancs. Hívhatjuk őket közvetlenül a parancssorból vagy bármely más jobütemezőből.
Elképzelhető, hogy ezeket a parancsokat az IDE-be épített héjból hívhatja meg, és manapság az RStudio IDE olyan eszközöket tartalmaz, amelyek továbbfejlesztik vagy kezelik az R szkriptet és az R CMD BATCH funkciókat.
Az R (belül) forrás () függvény jó alternatíva a parancssor használatához. Ez a függvény meghívhat egy szkriptet is, de a funkció használatához az R környezetben kell lennie.
R Nyelvi beépített adatkészletek
Az R-vel beépített adatkészletek felsorolásához használja a data () parancsot, majd keresse meg a kívánt elemet, és használja az adatkészlet nevét az data () függvényben. Hasonló adatok (függvénynév).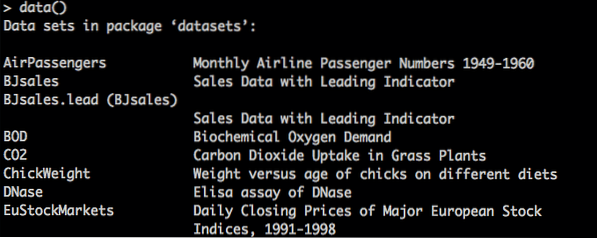
Adathalmazok megjelenítése R-ben
A kérdőjel (?) segítségével segítséget lehet kérni az adatkészletekhez.
Minden ellenőrzéséhez használja az összefoglalót ().
A Plot () egy olyan függvény is, amelyet grafikonok ábrázolására használnak.
Hozzunk létre egy teszt szkriptet, és futtassuk. Teremt p1.R fájlt, és mentse el a saját könyvtárba a következő tartalommal:
Kódpélda:
# Egyszerű hello world kód R betűvel ("Hello World!") print (" LinuxHint ") print (5 + 6) 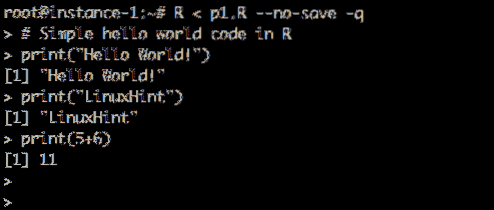
A Hello World futása
R Adatkeretek
Az adatok táblákba való tárolásához az R nevű a nevű struktúrát használjuk Adatkeret. Egyforma hosszúságú vektorok felsorolására szolgál. Például a következő változó nm egy adatkeret, amely három x, y, z vektort tartalmaz:
x = c (2, 3, 5) y = c ("aa", "bb", "cc") z = c (IGAZ, HAMIS, IGAZ) # nm egy adatkeret nm = adat.keret (n, s, b) Van egy úgynevezett fogalom BeépítettAdatkeretek R-ben is. mtcars az egyik ilyen beépített adatkeret az R-ben, amelyet példaként fogunk használni a jobb megértésünk érdekében. Lásd az alábbi kódot:
> mtcars mpg cyl disp hp drat wt… Mazda RX4 21.0 6 160 110 3.90 2.62… busz RX4 Wag 21.0 6 160 110 3.90 2.88… Datsun 710 22.8 4 108 93 3.85 2.32…
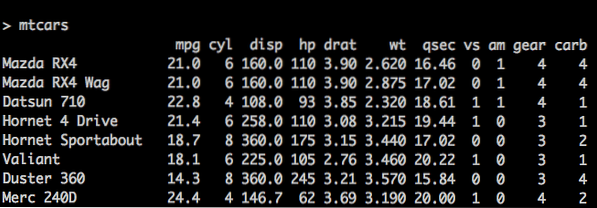
mtcars bulitin adatkeret
A fejléc az oszlopneveket tartalmazó táblázat felső sora. Az adatsorokat minden vízszintes vonal adományozza; minden sor a sor nevével kezdődik, majd a tényleges adatok következnek. A sor adattagját cellának nevezzük.
A sor- és oszlopkoordinátákat egyetlen szögletes zárójelben lévő „[]” operátorba írnánk be, hogy adatokat kapjunk egy cellában. A koordináták elválasztásához vesszőt használunk. A sorrend elengedhetetlen. A koordináta sorral, majd vesszővel kezdődik, majd az oszloppal végződik. A cella értéke 2nd sor és 1utca oszlop a következőképpen van megadva:
> mtcars [2, 2] [1] 6
A koordináták helyett használhatunk sor- és oszlopnevet is:
> mtcars ["Bus RX4", "mpg"] [1] 6
a nrow függvény segítségével meg lehet találni az adatkeret sorainak számát.
> nrow (mtcars) # adatsor száma [1] 32
Az ncol függvény segítségével meg lehet keresni az oszlopok számát egy adatkeretben.
> ncol (mtcars) # oszlopok száma [1] 11
R Programozási hurkok
Bizonyos feltételek mellett ciklusokat használunk, amikor automatizálni akarjuk a kód egy részét, vagy meg akarjuk ismételni az utasítások sorozatát.
Az R hurokhoz
Ha egyszerre több információt akarunk kinyomtatni ezekről az évekről.
nyomtatás (beillesztés ("Az év van", 2000)) "Az év 2000" nyomtatás (beillesztés ("Az év van", 2001)) "Az év 2001" nyomtatás (beillesztés ("Az év van", 2002) ) "Az év 2002" nyomtatás (beillesztés ("Az év van", 2003)) "Az év 2003" nyomtatás (beillesztés ("Az év van", 2004)) "Az év 2004" nyomtatás (beillesztés (" Az év ", 2005))" Az év 2005 " Ahelyett, hogy újra és újra megismételnénk állításunkat, ha használjuk mert hurok sokkal könnyebb lesz nekünk. Mint ez:
for (év c-ben (2000,2001,2002,2003,2004,2005)) print (beillesztés ("Az év", év)) "" Az év 2000 "" Az év 2001 "" Az év 2002 "" Az év 2003 "" Az év 2004 "" Az év 2005 " Míg hurok R-ben
while (kifejezés) utasítás
Ha a kifejezés eredménye IGAZ, akkor a hurok törzse kerül beírásra. A cikluson belüli utasítások végrehajtásra kerülnek, és az áramlás visszatér, hogy újra értékelje a kifejezést. A hurok addig ismételgeti magát, amíg a kifejezés FALSE értékre nem válik, ebben az esetben a hurok kilép.
Példa a while hurokra:
# i kezdetben inicializálva van 0 i = 0, míg (i<5) print (i) i=i+1 Output: 0 1 2 3 4
A fenti while ciklusban a kifejezés az én<5amely igaz, mivel 0 értéke kisebb, mint 5. Ezért a hurok teste végrehajtásra kerül, és én kimenet és növekmény. Fontos a növekmény én a hurok belsejében, tehát valamikor valahogy teljesíteni fogja a feltételt. A következő ciklusban a én értéke 1, és a hurok folytatódik. -Ig megismétli magát én egyenlő 5-vel, ha az 5. feltétel<5 reached loop will give FALSE and the while loop will exit.
R Funkciók
A funkció direktív függvényt használunk (). Pontosabban, ezek az osztály R objektumai funkció.
f <- function() ##some piece of instructions
Nevezetesen, a függvényeket át lehet adni más függvényeknek, mivel argumentumokat és függvényeket be lehet ágyazni, hogy meghatározhassunk egy függvényt egy másik függvény belsejében.
A függvények opcionálisan tartalmazhatnak megnevezett argumentumokat, amelyek alapértelmezett értékekkel rendelkeznek. Ha nem akar alapértelmezett értéket, akkor annak értékét NULL értékre állíthatja.
Néhány tény az R Function argumentumokkal kapcsolatban:
- A függvénydefinícióban elfogadott érvek a formális érvek
- A formális függvény visszaadhat egy függvény összes formális argumentumát
- Az R-ben nem minden függvényhívás használja az összes formális argumentumot
- Lehet, hogy a függvény argumentumok alapértelmezett értékekkel rendelkeznek, vagy hiányozhatnak
# Funkció meghatározása: f <- function (x, y = 1, z = 2, s= NULL)
Logisztikai regressziós modell készítése beépített adatsorral
A glm () függvényt használjuk R-ben a logisztikai regresszió illesztésére. A glm () függvény hasonló az lm () -hez, de a glm () rendelkezik néhány további paraméterrel. Formátuma így néz ki:
glm (X ~ Z1 + Z2 + Z3, family = binomiális (link = ”logit”), data = mydata)
X függ Z1, Z2 és Z3 értékeitől. Ami azt jelenti, hogy Z1, Z2 és Z3 független változók, és X az függő függvény. A függvény extra paramétercsaládot tartalmaz, és binomiális értéke van (link = „logit”), ami azt jelenti, hogy a link függvény logit, a regressziós modell valószínűségi eloszlása pedig binomiális.
Tegyük fel, hogy van egy példánk a hallgatóra, ahol két vizsgaeredmény alapján felvételt kap. Az adatkészlet a következő elemeket tartalmazza:
- eredmény _1- 1. eredmény
- eredmény _2- Eredmény -2 pontszám
- beengedett- 1, ha beengedik, vagy 0, ha nem engedik be
Ebben a példában két értékünk van: 1, ha egy hallgató felvételt kapott, és 0, ha nem kapott felvételt. Generálnunk kell egy modellt annak előrejelzésére, hogy a hallgató felvételt kapott-e vagy sem,. Egy adott probléma esetén a felvett függő változónak, a vizsga_1 és a vizsga_2 független változónak számít. Ehhez a modellhez megadjuk az R kódunkat
> Modell_1<-glm(admitted ~ result_1 +result_2, family = binomial("logit"), data=data) Tegyük fel, hogy két eredményünk van a hallgatóról. Eredmény-1 65% és eredmény-2 90%, most megjósoljuk, hogy a hallgató felvételt kap-e vagy sem azért, hogy megbecsülje annak valószínűségét, hogy a hallgató felvételt kap-e, az R kódunk az alábbiak szerint alakul:
> in_frame<-data.frame(result_1=65,result_2=90) >megjósolni (Model_1, in_frame, type = "response") Kimenet: 0.9894302
A fenti kimenet megmutatja a 0 és 1 közötti valószínűséget. Ha akkor kevesebb, mint 0.5 azt jelenti, hogy a hallgató nem kapott felvételt. Ebben az állapotban HAMIS lesz. Ha nagyobb, mint 0.Az 5. cikk szerint a feltétel IGAZnak minősül, ami azt jelenti, hogy a hallgató felvételt nyert. A round () függvényt kell használnunk a 0 és 1 közötti valószínűség előrejelzésére.
Ennek R kódja az alábbiak szerint látható:
> kerek (előrejelzés (Model_1, in_frame, type = "response")) [/ code] Kimenet: 1
A hallgató felvételt kap, mivel a kimenet 1. Sőt, más megfigyelésekre is megjósolhatjuk ugyanúgy.
Logisztikai regressziós modell (pontozás) használata új adatokkal
Szükség esetén a modellt fájlba menthetjük. A vonatmodellünk R kódja így fog kinézni:
a modell <- glm(my_formula, family=binomial(link='logit'),data=model_set)
Ez a modell a következőkkel menthető el:
mentés (file = "fájlnév", the_file)
A fájlt mentése után használhatja az R kód békéjének használatával:
betöltés (fájl = "fájlnév")
A modell új adatokra történő alkalmazásához használhatja a kód ezen sorát:
model_set $ pred <- predict(the_model, newdata=model_set, type="response")
JEGYZET: A model_set nem rendelhető egyetlen változóhoz sem. A modell betöltéséhez a load () függvényt fogjuk használni. Az új megfigyelések semmit sem változtatnak a modellen. A modell ugyanaz marad. A régi modell segítségével előrejelzéseket készítünk az új adatokról, hogy semmit ne változtassunk a modellen.
Következtetés
Remélem, látta, hogyan működik az R programozás alapvető módon, és hogyan kezdhet el gyorsan cselekedni gépi tanulással és statisztikai kódolással az R segítségével.

