Az Apache Spark egy adatelemző eszköz, amely felhasználható a HDFS, S3 vagy más memória adatforrásokból származó adatok feldolgozására. Ebben a bejegyzésben telepítjük az Apache Sparkot egy Ubuntu 17-re.10 gép.
Ubuntu verzió
Ehhez az útmutatóhoz az Ubuntu 17-es verzióját fogjuk használni.10 (GNU / Linux 4.13.0-38-általános x86_64).
Az Apache Spark a Hadoop Big Data ökoszisztémájának része. Próbálja meg telepíteni az Apache Hadoop alkalmazást, és készítsen vele egy minta alkalmazást.
Meglévő csomagok frissítése
A Spark telepítésének megkezdéséhez frissítenünk kell gépünket a rendelkezésre álló legújabb szoftvercsomagokkal. Megtehetjük ezt:
sudo apt-get update && sudo apt-get -y dist-upgradeMivel a Spark Java alapú, telepítenünk kell a gépünkre. Bármely Java verziót használhatunk a Java 6 felett. Itt a Java 8-at fogjuk használni:
sudo apt-get -y telepítse az openjdk-8-jdk-headless fájltSpark fájlok letöltése
Az összes szükséges csomag már létezik gépünkön. Készen állunk a szükséges Spark TAR fájlok letöltésére, hogy megkezdhessük a beállításukat és futtassunk egy minta programot a Sparkkal is.
Ebben az útmutatóban telepítjük Spark v2.3.0 elérhető itt:
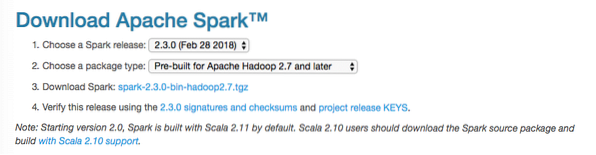
Spark letöltési oldal
Töltse le a megfelelő fájlokat ezzel a paranccsal:
wget http: // www-us.apache.org / dist / spark / spark-2.3.0 / szikra-2.3.0-bin-hadoop2.7.tgzA hálózati sebességtől függően ez akár néhány percet is igénybe vehet, mivel a fájl nagy méretű:
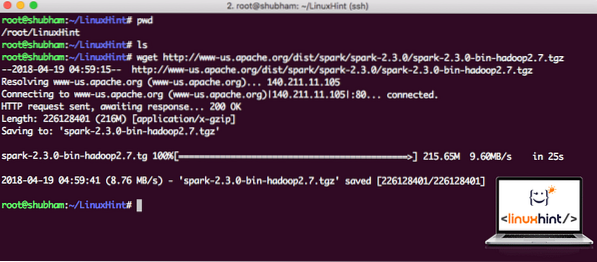
Az Apache Spark letöltése
Most, hogy letöltöttük a TAR fájlt, kibonthatjuk az aktuális könyvtárból:
tar xvzf spark-2.3.0-bin-hadoop2.7.tgzEnnek befejezése néhány másodpercet vesz igénybe az archívum nagy fájlmérete miatt:
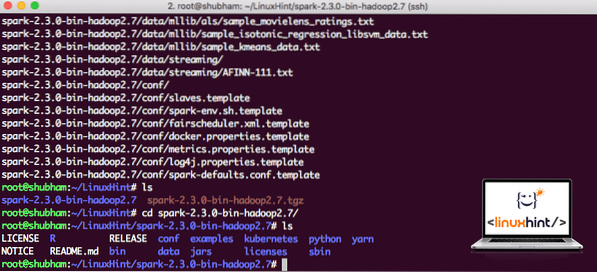
Archiválatlan fájlok a Sparkban
Az Apache Spark jövőbeni frissítésével kapcsolatban problémákat okozhat a Path frissítések miatt. Ezek a kérdések elkerülhetők, ha egy softlinket hozunk létre a Sparkhoz. Futtassa ezt a parancsot egy softlink létrehozásához:
ln -s szikra-2.3.0-bin-hadoop2.7 szikraSzikra hozzáadása az útvonalhoz
A Spark szkriptek végrehajtásához most hozzáadjuk az útvonalhoz. Ehhez nyissa meg a bashrc fájlt:
vi ~ /.bashrcAdja hozzá ezeket a sorokat a .bashrc fájlt, hogy az elérési út tartalmazhassa a Spark futtatható fájl elérési útját:
SPARK_HOME = / LinuxHint / sparkexport PATH = $ SPARK_HOME / bin: $ PATH
A fájl a következőképpen néz ki:
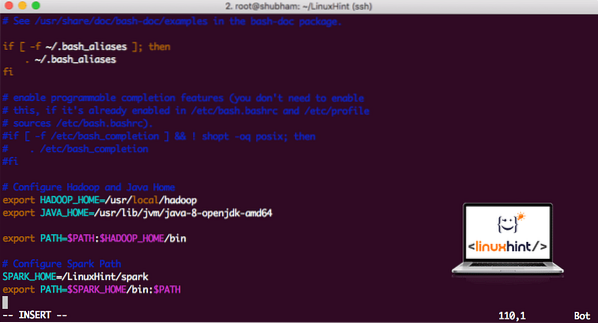
Spark hozzáadása a PATH-hoz
A változások aktiválásához futtassa a következő parancsot a bashrc fájlhoz:
forrás ~ /.bashrcSpark Shell elindítása
Most, amikor éppen a szikra könyvtáron kívül vagyunk, futtassa a következő parancsot az apark shell megnyitásához:
./ szikra / kuka / szikrakagylóMeglátjuk, hogy a Spark héj most nyitva van:
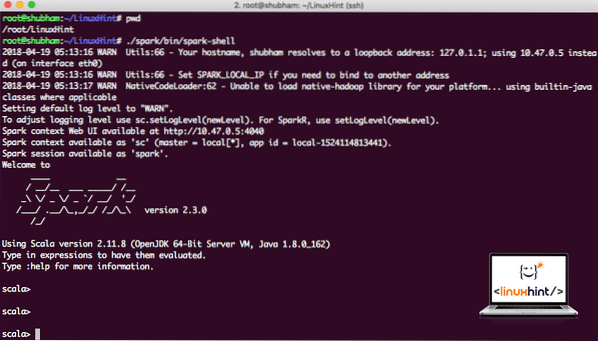
Spark héj elindítása
A konzolon láthatjuk, hogy a Spark egy webkonzolt is megnyitott a 404-es porton. Látogassunk el rá:
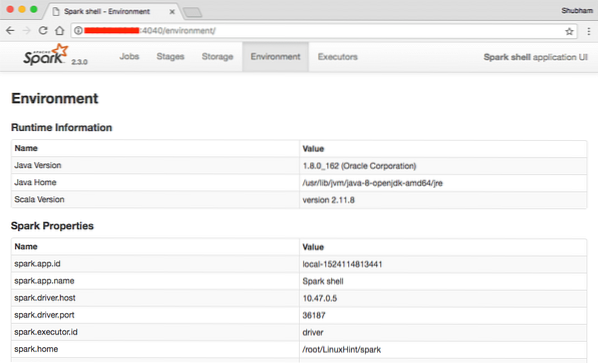
Apache Spark webkonzol
Habár magát a konzolt fogjuk működtetni, a webes környezet fontos szempont, ahova érdemes figyelni, amikor nehéz Spark-feladatokat hajt végre, hogy tudja, mi történik az egyes végrehajtott Spark-munkákban.
Egy egyszerű paranccsal ellenőrizze a Spark shell verzióját:
sc.változatIlyeneket kapunk vissza:
res0: Karakterlánc = 2.3.0Minta Spark alkalmazás készítése a Scala segítségével
Most elkészítünk egy Word Counter alkalmazást az Apache Spark alkalmazással. Ehhez először töltsön be egy szöveges fájlt a Spark Context-be a Spark shell-ben:
scala> var Data = sc.textFile ("/ root / LinuxHint / spark / README.md ")Adatok: org.apache.szikra.rdd.RDD [String] = / root / LinuxHint / spark / README.md MapPartitionsRDD [1] at textFile: 24
scala>
Most a fájlban található szöveget tokekre kell bontani, amelyeket a Spark kezelhet:
scala> var tokenek = Adatok.flatMap (s => s.hasított(" "))tokenek: org.apache.szikra.rdd.RDD [String] = MapPartitionsRDD [2] a flatMap-on: 25
scala>
Most inicializálja az egyes szavak számát 1-re:
scala> var tokenek_1 = tokenek.térkép (s => (s, 1))tokenek_1: org.apache.szikra.rdd.RDD [(String, Int)] = MapPartitionsRDD [3] a térképen: 25
scala>
Végül számítsa ki a fájl egyes szavainak gyakoriságát:
var sum_each = tokenek_1.reducByKey ((a, b) => a + b)Ideje megnézni a program kimenetét. Gyűjtse össze a tokeneket és azok számát:
scala> sum_each.gyűjt()res1: Array [(String, Int)] = Array ((csomag, 1), (For, 3), (Programs, 1), (feldolgozás.,1), (Mert, 1), (The, 1), (oldal] (http: // szikra).apache.org / dokumentáció.html).,1), (klaszter.,1), (annak, 1), ([run, 1), (mint, 1), (API-k, 1), (have, 1), (Try, 1), (computation, 1), (through, 1 ), (több, 1), (Ez, 2), (grafikon, 1), (Kaptár, 2), (tárolás, 1), (["Specifikálás, 1), (Cél, 2), (" fonal " , 1), (Egyszer, 1), (["Hasznos, 1), (előnyben részesítendő, 1), (SparkPi, 2), (motor, 1), (verzió, 1), (fájl, 1), (dokumentáció ,, 1), (feldolgozás ,, 1), (the, 24), (are, 1), (rendszerek).,1), (paraméterek, 1), (nem, 1), (különböző, 1), (hivatkozás, 2), (Interaktív, 2), (R ,, 1), (adott.,1), (if, 4), (build, 4), (mikor, 1), (be, 2), (Tesztek, 1), (Apache, 1), (thread, 1), (programok ,, 1 ), (beleértve a 4-et), (./ bin / run-example, 2), (Spark.,1), (csomag.,1), (1000).count (), 1), (Verziók, 1), (HDFS, 1), (D…
scala>
Kiváló! Futtathattunk egy egyszerű Word Counter példát a Scala programozási nyelv használatával, a rendszerben már meglévő szöveges fájllal.
Következtetés
Ebben a leckében megvizsgáltuk, hogyan telepíthetjük és elkezdhetjük az Apache Spark használatát az Ubuntu 17-en.10 gépet, és futtasson rajta egy minta alkalmazást is.
További Ubuntu-alapú bejegyzéseket itt olvashat.


