A Python tartalmaz egy nevű modult urllib az egységes erőforrás-keresővel (URL) kapcsolatos feladatok kezeléséhez. Ez a modul alapértelmezés szerint a Python 3-ba van telepítve, és a különböző protokollok URL-jeit a urlopen () funkció. Az Urllib számos célra felhasználható, például a webhely tartalmának olvasására, HTTP és HTTPS kérések készítésére, kérés fejlécek küldésére és válasz fejlécek lekérésére. A urllib modul sok más modult tartalmaz az URL-ek kezeléséhez, mint pl urllib.kérés, urllib.elemzés, és urllib.hiba, többek között. Ez az oktatóanyag megmutatja, hogyan kell használni az Urllib modult a Pythonban.
1. példa: URL-ek megnyitása és olvasása az urllib segítségével.kérés
A urllib.kérés modul tartalmazza az URL-ek megnyitásához és olvasásához szükséges osztályokat és módszereket. A következő szkript bemutatja, hogyan kell használni urllib.kérés modul az URL megnyitásához és az URL tartalmának elolvasásához. Itt a urlopen () metódust használnak az URL megnyitására,https: // www.linuxhint.com /.”Ha az URL érvényes, akkor az URL tartalma a megnevezett objektumváltozóban lesz tárolva válasz. A olvas() módszere válasz objektumot használjuk az URL tartalmának elolvasására.
#!/ usr / bin / env python3# Az urllib import kérési modulja
import urllib.kérés
# Nyissa meg az URL-t az urlopen () használatával történő olvasáshoz
válasz = urllib.kérés.urlopen ('https: // www.linuxhint.com / ')
# Nyomtassa ki az URL válaszadatait
print ("Az URL kimenete: \ n \ n", válasz.olvas())
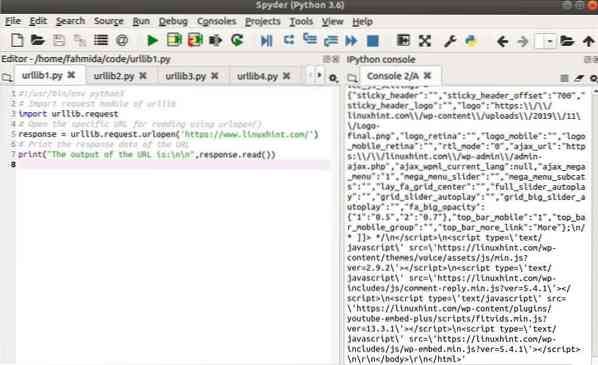
Kimenet
A következő kimenet jelenik meg a szkript futtatása után.
2. példa: Az URL-ek elemzése és kivonása az urllib segítségével.elemzés
A urllib.elemzés modul elsősorban az URL különböző összetevőinek szétválasztására vagy összekapcsolására szolgál. A következő szkript bemutatja a urllib.elemzés modul. A négy funkciója urllib.elemzés használt következő szkript tartalmazza urlparse, urlunparse, urlsplit, és urlunsplit. A urlparse modul úgy működik, mint urlsplit, és a urlunparse modul úgy működik, mint urlunsplit. E funkciók között csak egy különbség van; vagyis, urlparse és urlunparse tartalmaz egy 'paraméter nevű extra paramétertparams'a hasításhoz és a csatlakozási funkcióhoz. Itt az URL-t 'https: // linuxhint.com / play_sound_python / 'az URL felosztásához és csatlakozásához használatos.
#!/ usr / bin / env python3# Importálja az urllib elemző modulját
import urllib.elemzés
# URL elemzése az urlparse () használatával
urlParse = urllib.elemzés.urlparse ('https: // linuxhint.com / play_sound_python / ')
print ("\ nAz URL kimenete elemzés után: \ n", urlParse)
# URL-hez való csatlakozás az urlunparse () használatával
urlUnparse = urllib.elemzés.urlunparse (urlParse)
print ("\ nAz elemző URL csatlakozási kimenete: \ n", urlUnparse)
# URL elemzése az urlsplit () használatával
urlSplit = urllib.elemzés.urlsplit ('https: // linuxhint.com / play_sound_python / ')
print ("\ nAz URL kimenete felosztás után: \ n", urlSplit)
# Csatlakozás URL-hez az urlunsplit () használatával
urlUnsplit = urllib.elemzés.urlunsplit (urlSplit)
print ("\ nAz URL felosztásának kimenete: \ n", urlUnsplit)
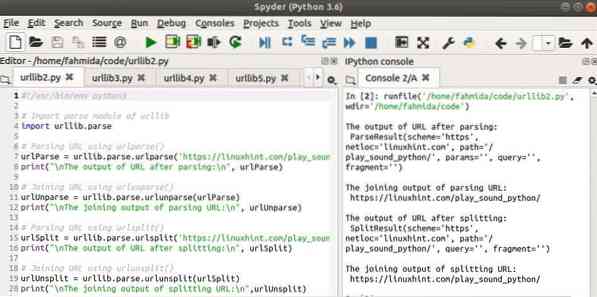
Kimenet
A következő négy kimenet jelenik meg a szkript futtatása után.
3. példa: A HTML válaszfejlécének olvasása urllib-el.kérés
A következő szkript bemutatja, hogyan lehet az URL válasz fejlécének különböző részeit lekérni a információ () módszer. A urllib.kérés az URL megnyitásához használt modul, 'https: // linuxhint.com / python_pause_user_input /,'és ennek az URL-nek a fejléc-információja a info () módszer. A szkript következő része megmutatja, hogyan kell külön elolvasni a fejléc egyes részeit. Itt a szerver, Dátum, és Tartalom típus az értékeket külön nyomtatják.
#!/ usr / bin / env python3# Az urllib import kérési modulja
import urllib.kérés
# Nyissa meg az URL-t olvasásra
urlResponse = urllib.kérés.urlopen ('https: // linuxhint.com / python_pause_user_input / ')
# Az URL válasz fejléc kimenetének olvasása
nyomtatás (urlResponse.info ())
# A fejléc információinak külön olvasása
print ('Válaszkiszolgáló =', urlResponse.információ () ["Szerver"])
print ('A válasz dátuma =', urlResponse.információ () ["Dátum"])
print ('A válasz tartalom típusa =', urlResponse.info () ["Tartalomtípus"])
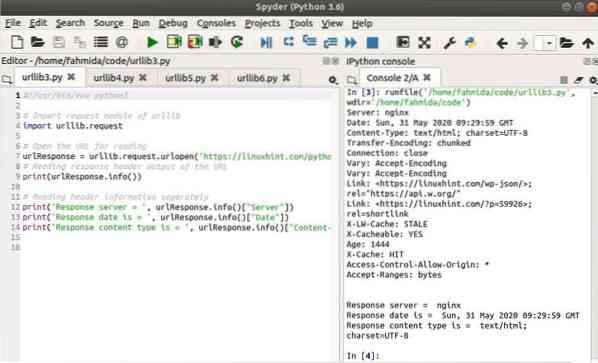
Kimenet
A következő kimenet jelenik meg a szkript futtatása után.
4. példa: Az URL-válaszok soronkénti olvasása
Helyi URL-címet használunk a következő szkriptben. Itt egy tesztelő HTML fájl teszt.html a helyszínen jön létre, var /www / html. A fájl tartalma soronként olvasható a mert hurok. A szalag() módszerrel ezt követően eltávolítják a teret az egyes vonalak mindkét oldaláról. A parancsfájl teszteléséhez a helyi szerver bármely HTML-fájlját felhasználhatja. A tartalom teszt.html Az ebben a példában használt fájl az alábbiakban található.
teszt.html:
Tesztelő oldal
#!/ usr / bin / env python3
# Urllib importálása.kérelem modul
import urllib.kérés
# Nyisson meg egy helyi URL-t olvasásra
válasz = urllib.kérés.urlopen ('http: // localhost / test.html ')
# Olvassa el az URL-t a válaszból
print ('URL:', válasz.geturl ()
# Olvassa el soronként a válasz szövegét
nyomtatás ("\ nOldaltartalom:")
válaszként a vonalon:
nyomtatás (sor.szalag())
Kimenet
A következő kimenet jelenik meg a szkript futtatása után.

5. példa: Kivételek kezelése urllib-kel.hiba.URLError
A következő szkript bemutatja a URLError a Pythonban a urllib.hiba modul. Bármely URL-cím a felhasználó inputjaként vehető figyelembe. Ha a cím nem létezik, akkor egy URLError kivétel felmerül, és a hiba oka kinyomtatódik. Ha az URL értéke érvénytelen formátumú, akkor a ValueError fel lesz emelve, és az egyedi hiba kinyomtatódik.
#!/ usr / bin / env python3# Importálja a szükséges modulokat
import urllib.kérés
import urllib.hiba
# próbáld meg letiltani az URL megnyitását olvasásra
próbáld ki:
url = input ("Írjon be bármilyen URL-címet:")
válasz = urllib.kérés.urlopen (url)
nyomtatás (válasz.olvas())
# Fogja el azt az URL-hibát, amely bármely URL megnyitásakor keletkezik
az urllib kivételével.hiba.URLError as e:
nyomtatás ("URL Error:", pl.ok)
# Érje el az érvénytelen URL hibát
kivéve ValueError:
print ("Írjon be érvényes URL-címet")
Kimenet
A szkriptet a következő képernyőképen háromszor hajtják végre. Az első iterációban az URL-címet érvénytelen formátumban adják meg, ami ValueError-t generál. A második iterációban megadott URL-cím nem létezik, ami URLE hibát generál. Érvényes URL-címet adunk meg a harmadik iterációban, és így kinyomtatjuk az URL tartalmát.

6. példa: Kivételek kezelése urllib-kel.hiba.HTTPError
A következő szkript bemutatja a HTTPError a Pythonban a urllib.hiba modul. An HTMLError akkor generál, ha a megadott URL-cím nem létezik.
#!/ usr / bin / env python3# Importálja a szükséges modulokat
import urllib.kérés
import urllib.hiba
# Adjon meg minden érvényes URL-t
url = input ("Írjon be bármilyen URL-címet:")
# Kérés küldése az URL-re
kérés = urllib.kérés.Kérelem (URL)
próbáld ki:
# Próbálja megnyitni az URL-t
urllib.kérés.urlopen (kérés)
nyomtatás ("URL létezik")
kivéve urllib.hiba.HTTPError as e:
# Nyomtassa ki a hibakódot és a hiba okát
print ("Hibakód:% d \ nHiba oka:% s"% (pl.kód, pl.ok))
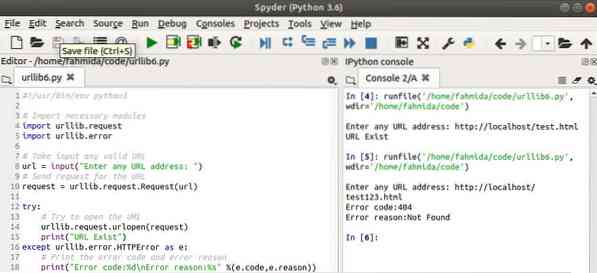
Kimenet
Itt a szkriptet kétszer hajtják végre. Az első bevitt URL-cím létezik, és a modul kinyomtatott egy üzenetet. A bemenetként vett második URL-cím nem létezik, és a modul létrehozta a címet HTTPError.
Következtetés
Ez az oktatóanyag a urllib modul segítségével különféle példák segítségével segíthet az olvasóknak megismerni ennek a modulnak a Python-ban található funkcióit.


