Mi az Apache Solr
Az Apache Solr az egyik legnépszerűbb NoSQL adatbázis, amely felhasználható adatok valós idejű tárolására és lekérdezésére. Apache Lucene-n alapul, és Java nyelven íródott. Csakúgy, mint az Elasticsearch, az REST API-k révén támogatja az adatbázis-lekérdezéseket. Ez azt jelenti, hogy használhatunk egyszerű HTTP hívásokat, és használhatunk HTTP módszereket, például GET, POST, PUT, DELETE stb. az adatokhoz való hozzáféréshez. Lehetőséget nyújt továbbá adatok XML vagy JSON formájában történő megszerzésére is a REST API-k segítségével.
Építészet: Apache Solr
Mielőtt elkezdenénk dolgozni az Apache Solr programmal, meg kell értenünk az Apache Solr összetevőit. Vessünk egy pillantást néhány összetevőjére:
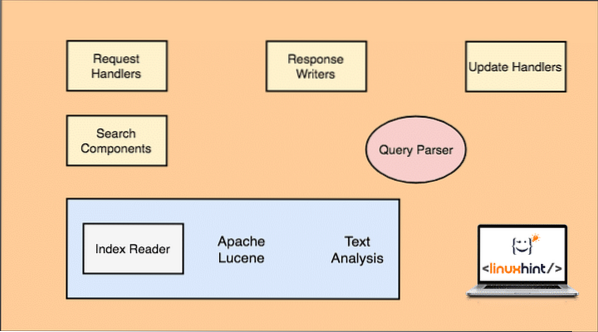
Apache Solr építészet
Ne feledje, hogy a fenti ábra csak a Solr főbb összetevőit mutatja. Értsük meg itt is a funkcionalitásukat:
- Kérelemkezelők: Az ügyfél által a Solrhoz intézett kéréseket egy kéréskezelő kezeli. A kérés bármi lehet, kezdve az új rekord hozzáadásától az index frissítéséig a Solr-ban. A kezelők a kérés típusát a kérés leképezéséhez használt HTTP módszerből azonosítják.
- Search Component: Ez az egyik legfontosabb komponens, amelyről a Solr ismert. A Search Component gondoskodik a kereséssel kapcsolatos műveletek végrehajtásáról, mint pl. Fuzziness, helyesírás-ellenőrzés, kifejezéslekérdezések stb.
- Lekérdező elemző: Ez az a komponens, amely valóban elemzi azt a lekérdezést, amelyet az ügyfél átad a kéréskezelőnek, és több részre bontja a lekérdezést, amelyek az alapul szolgáló motor számára érthetők
- Válaszíró: Ez az összetevő felelős a motornak továbbított lekérdezések kimeneti formátumának kezeléséért. A Response Writer lehetővé teszi számunkra, hogy kimenetet nyújtsunk különböző formátumokban, például XML, JSON stb.
- Analyzer / Tokenizer: A Lucene Engine megérti a lekérdezéseket több token formájában. Solr elemzi a lekérdezést, több tokenre bontja és továbbítja a Lucene Engine-nek.
- Frissítési kérelem processzor: Ha egy lekérdezés fut, és olyan műveleteket hajt végre, mint egy index és a hozzá kapcsolódó adatok frissítése, az Update Request Processor összetevő felelős az indexben lévő adatok kezeléséért és módosításáért.
Az Apache Solr használatának megkezdése
Az Apache Solr használatának megkezdéséhez telepíteni kell a gépre. Ehhez olvassa el az Apache Solr telepítése az Ubuntun című cikket.
Győződjön meg róla, hogy aktív Solr telepítéssel rendelkezik, ha szeretné kipróbálni a lecke későbbi példáit, és az admin oldal elérhető a localhoston:
Apache Solr Honlap
Adatok beszúrása
Először is vegyünk egy Solr-gyűjteményt, amelyet hívunk linux_hint_collection. Nem szükséges kifejezetten meghatározni ezt a gyűjteményt, mivel amikor behelyezzük az első objektumot, a gyűjtemény automatikusan elkészül. Próbáljuk ki az első REST API hívást, hogy új objektumot illesszünk be a megnevezett gyűjteménybe linux_hint_collection.
Adatok beszúrása
curl -X POST -H 'Tartalomtípus: alkalmazás / JSON'"http: // localhost: 8983 / solr / linux_hint_collection / update / json / docs" --data-bináris "
"id": "iduye",
"name": "Shubham"
'
Íme, amit ezzel a paranccsal kapunk vissza:

Parancs adatok beillesztésére a Solr-ba
Az adatok beilleszthetők a korábban megtekintett Solr honlap segítségével is. Próbálja ki ezt itt, hogy a dolgok világosak legyenek:
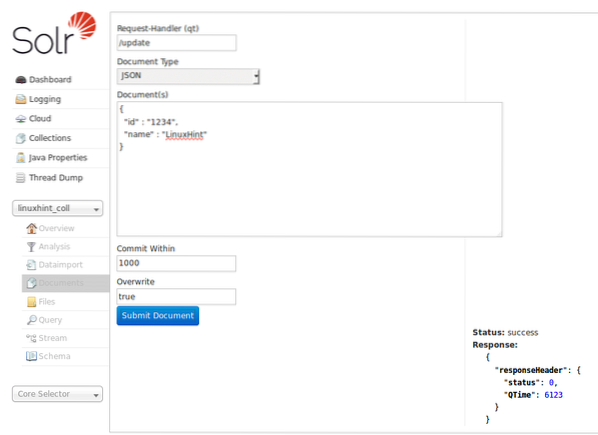
Adatok beszúrása a Solr honlapján keresztül
Mivel a Solr kiválóan képes interakcióba lépni a HTTP RESTful API-kkal, mostantól kezdve ugyanazokkal az API-kkal fogjuk bemutatni a DB interakciót, és nem sokat foglalkozunk majd az adatok beszúrásával a Solr weboldalon.
Az összes gyűjtemény felsorolása
Az Apache Solr összes gyűjteményét felsorolhatjuk egy REST API segítségével is. Itt van a parancs, amelyet használhatunk:
Az összes gyűjtemény felsorolása
göndörítés http: // localhost: 8983 / solr / admin / gyűjtemények?műveletek = LIST & wt = jsonLássuk a parancs kimenetét:
Két gyűjteményt látunk itt, amelyek a Solr installációnkban léteznek.
Az objektum megszerzése azonosító szerint
Most nézzük meg, hogyan szerezhetünk adatokat a Solr gyűjteményből egy adott azonosítóval. Itt van a REST API parancs:
Az objektum megszerzése azonosító szerint
göndörítés http: // localhost: 8983 / solr / linux_hint_collection / get?id = iduyeÍme, amit ezzel a paranccsal kapunk vissza:
Minden adat beolvasása
A legutóbbi REST API-ban egy adott azonosító használatával kérdeztünk adatokat. Ezúttal minden adatot megkapunk a Solr gyűjteményünkben.
Az objektum megszerzése azonosító szerint
curl http: // localhost: 8983 / solr / linux_hint_collection / select?q = *: *Íme, amit ezzel a paranccsal kapunk vissza: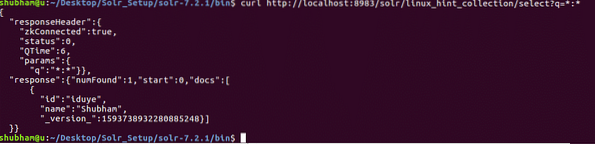
Vegye figyelembe, hogy a '*: *' szót használtuk a lekérdezési paraméterben. Ez meghatározza, hogy a Solr-nak vissza kell adnia a gyűjteményben található összes adatot. Még ha meg is határoztuk, hogy minden adatot vissza kell adni, a Solr megérti, hogy a gyűjteményben nagy mennyiségű adat lehet, és így, csak az első 10 dokumentumot adja vissza.
Az összes adat törlése
Mostanáig minden kipróbált API JSON formátumot használt. Ezúttal megpróbálunk XML lekérdezési formátumot használni. Az XML formátum használata rendkívül hasonló a JSON-hoz, mivel az XML önleíró is.
Próbálkozzunk egy paranccsal a gyűjteményünkben lévő összes adat törléséhez.
Az összes adat törlése
curl "http: // localhost: 8983 / solr / linux_hint_collection / update?kötelezettség = true "-H" Tartalom-típus: text / xml "--data-bináris" *: * "Íme, amit ezzel a paranccsal kapunk vissza:

Az összes adatot törölje XML lekérdezéssel
Most, ha újra megpróbáljuk megszerezni az összes adatot, látni fogjuk, hogy jelenleg nem állnak rendelkezésre adatok:

Minden adat beolvasása
Teljes objektumszám
A végső CURL parancshoz lássunk egy parancsot, amellyel megtalálhatjuk az indexben lévő objektumok számát. Itt van a parancs ugyanarra:
Teljes objektumszám
curl http: // localhost: 8983 / solr / linux_hint_collection / query?debug = lekérdezés & q = *: *Íme, amit ezzel a paranccsal kapunk vissza:
Számolja az objektumok számát
Következtetés
Ebben a leckében megvizsgáltuk, hogyan használhatjuk az Apache Solr programot és hogyan adhatunk át lekérdezéseket curl használatával JSON és XML formátumban egyaránt. Azt is láttuk, hogy a Solr admin panel ugyanúgy hasznos, mint az összes általunk vizsgált curl parancs.


