Ez az áttekintés kissé absztrakt, ezért alapozzuk meg egy valós helyzetben, képzeljük el, hogy több webkiszolgálót kell felügyelnie. Mindegyiküknek van saját weboldala, és a nap minden másodpercében mindegyikben folyamatosan új naplók jönnek létre. Ráadásul számos e-mail szerver van, amelyeket szintén figyelnie kell.
Lehetséges, hogy ezeket az adatokat nyilvántartási és számlázási célokra kell tárolnia, amely egy kötegelt feladat, amely nem igényel azonnali figyelmet. Érdemes elemzéseket futtatnia az adatokról, hogy valós időben hozzon döntéseket, amelyek pontos és azonnali adatbevitelt igényelnek. Hirtelen azon kapja magát, hogy ésszerű módon ésszerűsíteni kell az adatokat a különféle igények kielégítésére. Kafka az absztrakció azon rétegeként működik, amelyhez több forrás különböző adatfolyamokat és adott adatokat tehet közzé fogyasztó feliratkozhat az általa relevánsnak tartott streamekre. Kafka gondoskodik az adatok rendezettségéről. A Kafka belsejét kell megértenünk, mielőtt a Partíciózás és a kulcsok témához térnénk.
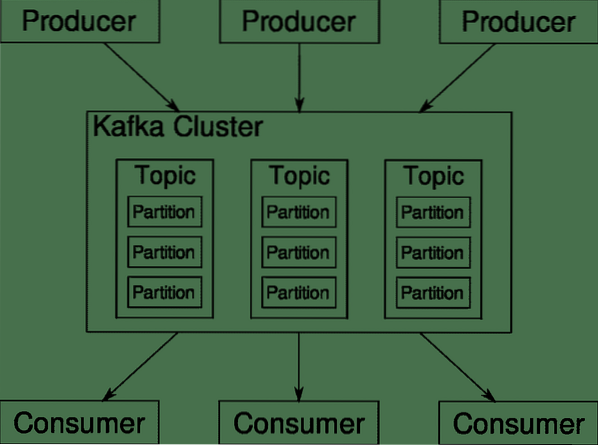
Kafka témák, bróker és partíciók
Kafka Témák olyanok, mint egy adatbázis táblái. Minden téma egy adott típusú, adott forrásból származó adatokból áll. Például a klaszter állapota olyan téma lehet, amely a CPU és a memória kihasználtságáról tartalmaz információkat. Hasonlóképpen, a fürtön át érkező forgalom másik téma lehet.
A Kafka vízszintesen méretezhető. Vagyis a Kafka egyetlen példánya több Kafkából áll brókerek több csomóponton futva mindegyik a másikkal párhuzamosan képes kezelni az adatfolyamokat. Még akkor is, ha néhány csomópont meghibásodik, az adatcsatorna továbbra is működhet. Ezután egy adott témát fel lehet osztani számos témára partíciók. Ez a felosztás az egyik döntő tényező Kafka horizontális skálázhatósága mögött.
Többszörös termelők, egy adott témához tartozó adatforrások írhatnak egyidejűleg az adott témára, mert mindegyikük egy másik partícióra ír, bármely adott pillanatban. Most általában az adatokat véletlenszerűen hozzárendelik egy partícióhoz, hacsak nem adunk hozzá kulcsot.
Felosztás és megrendelés
Csak összefoglalva, a gyártók adatokat írnak egy adott témára. Ez a téma valójában több partícióra van felosztva. És minden partíció függetlenül él a többitől, még egy adott témához is. Ez sok zavart okozhat, amikor az adatok megrendelése számít. Lehet, hogy időrendi sorrendben van szüksége az adataira, de ha több partícióval rendelkezik az adatfolyamhoz, az nem garantálja a tökéletes rendezést.
Témánként csak egy partíciót használhat, de ez meghiúsítja a Kafka elosztott architektúrájának teljes célját. Szükségünk van valamilyen más megoldásra.
Kulcsok a partíciókhoz
Egy gyártó adatai véletlenszerűen kerülnek a partíciókba, amint azt korábban említettük. Az üzenetek az adatok tényleges darabjai. Amit a gyártók csak az üzenetek küldésén kívül tehetnek, az az, hogy hozzáad egy kulcsot, amely hozzá tartozik.
A konkrét kulccsal érkező összes üzenet ugyanahhoz a partícióhoz fog menni. Tehát például egy felhasználó tevékenysége időrendi sorrendben követhető, ha a felhasználó adatait egy kulccsal címkézik, és így mindig egy partícióba kerülnek. Hívjuk ezt a partíciót p0-nak és a felhasználót u0.
A p0 partíció mindig felveszi az u0 kapcsolódó üzeneteket, mert ez a kulcs összeköti őket. De ez nem azt jelenti, hogy a p0 csak ehhez kötődik. U1 és u2 üzeneteket is felvehet, ha erre képes. Hasonlóképpen más partíciók is felhasználhatnak más felhasználók adatait.
Az a pont, hogy egy adott felhasználó adatai nincsenek elosztva a különböző partíciókon, biztosítva az időrendi sorrendet az adott felhasználó számára. Azonban a teljes témája felhasználói adat, továbbra is kihasználhatja az Apache Kafka elosztott architektúráját.
Következtetés
Míg az olyan elosztott rendszerek, mint a Kafka, megoldanak néhány régebbi problémát, például a méretezhetőség hiányát vagy egyetlen hibapontot. Számos olyan problémával járnak, amelyek saját tervezésüknél fogva egyedülállóak. Ezeknek a problémáknak az előrejelzése minden rendszerépítő alapvető feladata. Nem csak, néha valóban költség-haszon elemzést kell készítenie annak megállapítására, hogy az új problémák méltó kompromisszumot jelentenek-e az idősebbektől való megszabaduláshoz. A megrendelés és a szinkronizálás csak a jéghegy csúcsa.
Remélhetőleg az ilyen cikkek és a hivatalos dokumentáció segíthetnek.


