Apache Kafka
Magas szintű meghatározáshoz mutassunk be egy rövid definíciót Apache Kafka számára:
Az Apache Kafka egy elosztott, hibatűrő, vízszintesen méretezhető, elkötelezett napló.
Ez néhány magas szintű szó volt Apache Kafkáról. Itt értsük meg részletesen a fogalmakat.
- Megosztott: A Kafka a benne lévő adatokat több szerverre osztja fel, és mindegyik kiszolgáló képes kezelni az ügyfelek kéréseit a benne lévő adatok részarányára vonatkozóan
- Hibatűrő: Kafkának nincs egyetlen kudarcpontja. Egy SPoF rendszerben, például egy MySQL adatbázisban, ha az adatbázist tároló kiszolgáló leáll, az alkalmazás csavarodik. Egy olyan rendszerben, amelyben nincs SPoF, és többszörös csomópontokból áll, még akkor is, ha a rendszer nagy része lemegy, a végfelhasználó számára ugyanaz.
- Vízszintesen méretezhető: Ez a fajta átcsalás arra utal, hogy további gépeket kell hozzáadni a meglévő fürthöz. Ez azt jelenti, hogy az Apache Kafka képes több csomópontot fogadni a fürtjében, és nem biztosít leállási időt a rendszer szükséges frissítéséhez. Nézze meg az alábbi képet, hogy megismerje a fogás típusát:
- Végezze el a Naplót: A lekötési napló egy adatstruktúra, csakúgy, mint egy összekapcsolt lista. Bármely üzenetet hozzáfűzi, és mindig fenntartja azok sorrendjét. Az adatok nem törölhetők erről a naplóról, amíg az adott adatok elérik a megadott időt.
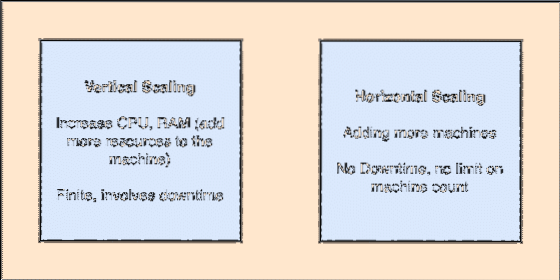
Függőleges és vízszintes siklás
Az Apache Kafka témája olyan, mint egy sor, ahol az üzeneteket tárolják. Ezeket az üzeneteket konfigurálható ideig tárolják, és az üzenetet addig nem törlik, amíg ezt az időt el nem érik, még akkor sem, ha az összes ismert fogyasztó elfogyasztotta.
A Kafka méretezhető, mivel a fogyasztók tárolják, hogy az általuk letöltött üzenet utoljára „ofszet” értékként. Nézzünk meg egy ábrát, hogy ezt jobban megértsük: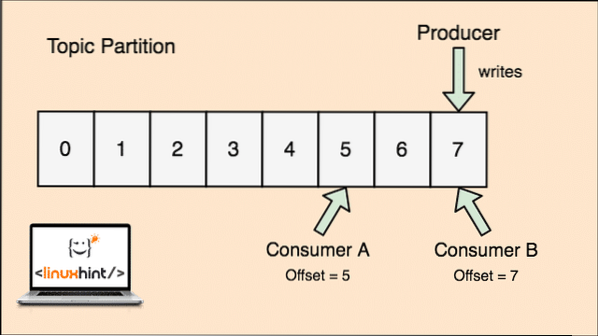
Témafelosztás és fogyasztói kompenzáció Apache Kafkában
Az első lépések az Apache Kafka-val
Az Apache Kafka használatának megkezdéséhez telepíteni kell a gépre. Ehhez olvassa el az Apache Kafka telepítése az Ubuntun című cikket.
Győződjön meg róla, hogy rendelkezik aktív Kafka-telepítéssel, ha szeretné kipróbálni a lecke későbbi példáit.
Hogyan működik?
Kafkával a Termelő az alkalmazások közzéteszik üzenetek amely egy Kafkához érkezik Csomópont és nem közvetlenül a Fogyasztónak. Ebből a Kafka csomópontból az üzeneteket a Fogyasztó alkalmazások.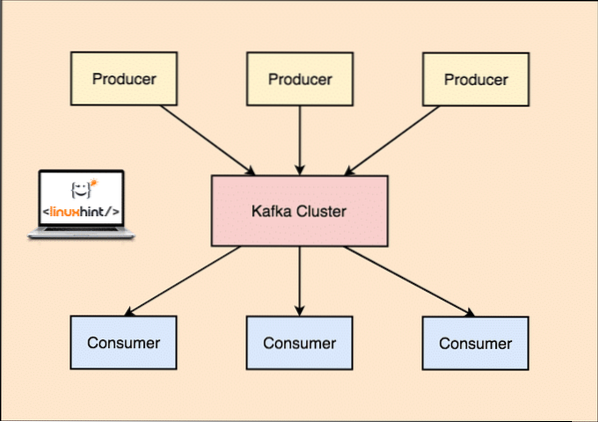
Kafka Producer és Consumer
Mivel egyetlen téma rengeteg adatot képes egyszerre megszerezni, hogy a Kafka vízszintesen skálázható legyen, az egyes témák partíciók és minden partíció a fürt bármely csomópont-gépén élhet. Próbáljuk meg bemutatni:
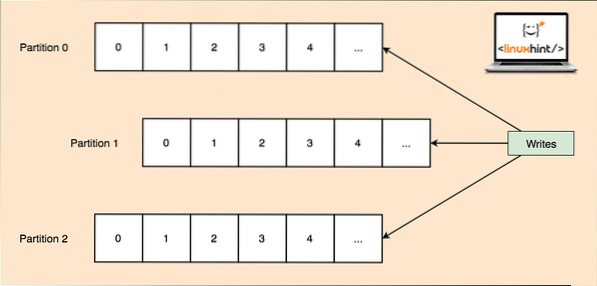
Témapartíciók
A Kafka Broker megint nem tartja nyilván, hogy melyik fogyasztó mennyi adatcsomagot fogyasztott el. Ez a a fogyasztók felelőssége az általa felhasznált adatok nyomon követése.
Kitartás a lemezhez
Kafka továbbra is megőrzi a Producertől lemezre kapott üzenetrekordokat, és nem tartja őket a memóriában. Felmerülhet a kérdés, hogy ez hogyan teszi megvalósíthatóvá és gyorsá a dolgokat? Ennek számos oka volt, ami az üzenetrekordok kezelésének optimális módját teszi:
- Kafka az üzenetrekordok csoportosításának protokollját követi. A gyártók olyan üzeneteket készítenek, amelyeket nagy darabokban tárolnak a lemezen, és a fogyasztók ezeket az üzenetrekordokat nagy lineáris darabokban is felhasználják.
- Az ok, hogy a lemez írása lineáris, az az, hogy ez gyors olvasást tesz lehetővé a nagyon csökkent lineáris lemezolvasási idő miatt.
- A lineáris lemez műveleteket optimalizálja Operációs rendszer valamint a írás után és előreolvasás.
- A modern operációs rendszer a Pagecaching ami azt jelenti, hogy a lemezen tárolt adatok egy részét szabadon elérhető RAM-ban tárolják.
- Mivel a Kafka az egységes áramadatban megőrzi az adatokat a termelőtől a fogyasztóig terjedő teljes áramlásban, felhasználja a nulla másolat optimalizálás folyamat.
Adatok terjesztése és replikálása
Amint fentebb tanulmányoztuk, hogy egy téma partíciókra van felosztva, minden üzenetrekordot replikálnak a fürt több csomópontján, hogy fenntartsák az egyes rekordok sorrendjét és adatait arra az esetre, ha az egyik csomópont meghalna.
Annak ellenére, hogy egy partíciót több csomóponton replikálnak, még mindig van egy partícióvezető csomópont, amelyen keresztül az alkalmazások olvasnak és írnak adatokat a témáról, és a vezető megismétli más csomópontok adatait, amelyeket követői annak a partíciónak.
Ha az üzenetrekord adatai nagyon fontosak egy alkalmazás számára, akkor az üzenetrekord biztonságának garantálása az egyik csomópontban növelhető az replikációs tényező a Klaszter.
Mi az a Zookeeper?
A Zookeeper rendkívül hibatűrő, elosztott kulcsérték-tároló. Az Apache Kafka nagymértékben a Zookeepertől függ, hogy tárolja-e a fürt mechanikáját, például a szívverést, a frissítések / konfigurációk terjesztését stb.).
Lehetővé teszi a Kafka brókerek számára, hogy feliratkozhassanak önmagukra, és tudják, ha bármilyen változás történt a partíció vezetőjével és a csomópont-elosztással kapcsolatban.
A gyártói és fogyasztói alkalmazások közvetlenül kommunikálnak a Zookeeperrel alkalmazás annak megismerésére, hogy melyik csomópont a témakör partícióvezetője, hogy olvasást és írást hajtsanak végre a partícióvezetőtől.
Folyó
Az adatfolyam-processzor a Kafka-fürt egyik fő alkotóeleme, amely folyamatos üzenetrögzítő adatfolyamot vesz a bemeneti témákból, feldolgozza ezeket az adatokat, és adatfolyamot hoz létre a kimeneti témákhoz, amelyek bármi lehetnek, a kukától az adatbázisig.
Teljesen lehetséges az egyszerű feldolgozás közvetlenül a gyártó / fogyasztó API-k segítségével, bár a bonyolult feldolgozáshoz, például az adatfolyamok egyesítéséhez, a Kafka integrált Streams API könyvtárat biztosít, de kérjük, vegye figyelembe, hogy ezt az API-t a saját kódbázisunkban kell használni, és nem ' ne fusson alkuszon. A fogyasztói API-hoz hasonlóan működik, és segít a stream-feldolgozás több alkalmazásra kiterjesztésében.
Mikor kell használni az Apache Kafka-t?
Amint azt a fenti szakaszokban tanulmányoztuk, az Apache Kafka számos olyan üzenetrekord kezelésére használható, amelyek gyakorlatilag végtelen számú témához tartozhatnak rendszereinkben.
Apache Kafka ideális jelölt egy olyan szolgáltatás használatában, amely lehetővé teszi számunkra, hogy az eseményvezérelt architektúrát kövessük alkalmazásainkban. Ennek oka az adatok perzisztenciája, hibatűrő és erősen elosztott architektúra, ahol a kritikus alkalmazások támaszkodhatnak a teljesítményére.
A Kafka skálázható és elosztott architektúrája nagyon egyszerűvé teszi az integrációt a mikroszolgáltatásokkal, és lehetővé teszi az alkalmazás számára, hogy szétválassza magát sok üzleti logikával.
Új téma létrehozása
Készíthetünk teszt témát tesztelés az Apache Kafka szerveren a következő paranccsal:
Téma létrehozása
sudo kafka-témák.sh --create --zookeeper localhost: 2181 - replikációs tényező 1--partíciók 1 - témakör tesztelése
Íme, amit ezzel a paranccsal kapunk vissza: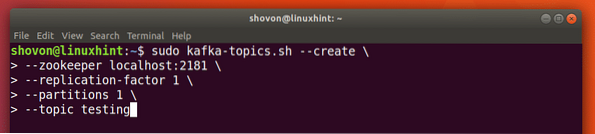
Hozzon létre új Kafka témát
Létrejön egy tesztelési téma, amelyet az említett paranccsal tudunk megerősíteni:
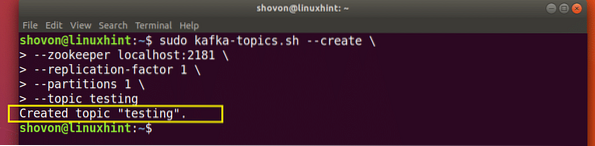
Kafka Téma létrehozásának megerősítése
Üzenetek írása egy témára
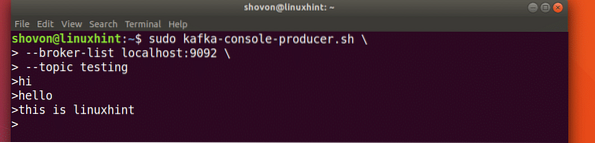
Ahogy korábban tanulmányoztuk, az Apache Kafka egyik API-je az Producer API. Ezt az API-t fogjuk használni egy új üzenet létrehozásához és közzétételéhez az imént létrehozott témában:
Üzenet írása a témához
sudo kafka-console-producer.sh - broker-list localhost: 9092 --téma tesztelésLássuk a parancs kimenetét:
Üzenet közzététele a Kafka témában
Miután megnyomta a gombot, egy új nyíl (>) jelet fogunk látni, ami azt jelenti, hogy most adatokat inoutozhatunk:

Üzenet beírása
Csak írjon be valamit, és nyomja meg az gombot, hogy új sort kezdjen. 3 szöveget írtam be:
Üzenetek olvasása a témáról
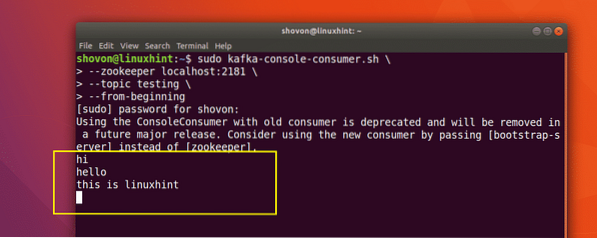
Most, hogy közzétettünk egy üzenetet az általunk létrehozott Kafka-témában, ez az üzenet egy ideig konfigurálható ideig ott lesz. Most elolvashatjuk a Consumer API:
Üzenetek olvasása a témáról
sudo kafka-konzol-fogyasztó.sh - zookeeper localhost: 2181 --téma tesztelése - kezdettől fogva
Íme, amit ezzel a paranccsal kapunk vissza:
Parancs a Kafka-üzenet üzenetének elolvasására
Láthatjuk az üzeneteket vagy sorokat, amelyeket a Producer API segítségével írtunk, az alábbiak szerint:
Ha újabb új üzenetet írunk a Producer API segítségével, akkor az azonnal megjelenik a Fogyasztó oldalon is:
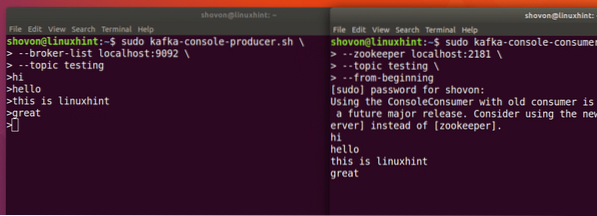
Közzététel és fogyasztás egyszerre
Következtetés
Ebben a leckében megvizsgáltuk, hogyan kezdjük el használni az Apache Kafka alkalmazást, amely kiváló üzenetközvetítő, és speciális adatmegőrzési egységként is működhet.


