A Grep-et széles körben alkalmazták a Linux rendszerekben, amikor egyes fájlokon dolgozott, keresett valamilyen konkrét mintát és még sok minden mást. Ezúttal a grep paranccsal jelenítjük meg az egyes fájlokban használt egyező kulcsszó előtti és utáni sorokat. Erre a célra a „-A”, „-B” és a „-C” jelzőt fogjuk használni oktató útmutatónkban. Tehát minden egyes lépést meg kell tennie a jobb megértés érdekében. Győződjön meg róla, hogy Ubuntu 20-at használ.04 Linux rendszer telepítve.
Először meg kell nyitnia a Linux parancssori terminálját, hogy elkezdhessen dolgozni a grep-en. Jelenleg az Ubuntu rendszer Home könyvtárában tartózkodik, közvetlenül a parancssori terminál megnyitása után. Tehát próbálja meg felsorolni az összes fájlt és mappát a Linux rendszerének saját könyvtárában az alábbi ls paranccsal, és az összeset megkapja. Láthatja, hogy van néhány szöveges fájl és néhány mappa benne.
ls
01. példa: '-A' és '-B' használata
A fent bemutatott szövegfájlokból megnézzük ezeket, és megpróbáljuk rájuk alkalmazni a grep parancsot. Nyissuk meg az „egy.txt ”először használja a népszerű„ macska ”parancsot, mint alatta:
$ cat one.txt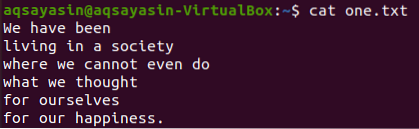
Először néhány konkrét szót találunk ebben a szövegfájlban a grep paranccsal, az alábbiak szerint. Az „egy” szövegfájlban a „mi” szóra keresünk.txt ”a grep utasítás segítségével. A kimenet két sort mutat a szövegfájlból, amelyben „mi” szerepel.
$ grep mi egy.txt
Tehát ebben a példában néhány szövegfájlban az adott szó egyezés előtti és utáni sorokat mutatjuk be. Tehát ugyanazt a szövegfájlt használva „egy.txt ”egyeztettük a„ mi ”szót, miközben az előtte lévő 3 sort az alábbiak szerint jelenítettük meg. A „-B” jelző „előtt”. A kimenet csak 2 sort mutat az adott szó sor előtt, mert a fájlnak nincs több sora egy adott szó sora előtt. Megmutatja azokat a sorokat is, amelyekben ez a szó szerepel.
$ grep -B 3 mi egy.txt
Használjuk ugyanazt a „mi” kulcsszót ebből a fájlból a sor után megjelenő 3 sor megjelenítésére, amelyeken szerepel a „mi” szó. Az „-A” zászló az „After” -t jelzi. A kimenet ismét csak 2 sort mutat, mert nincs több sor a fájlban.
$ grep -A 3 mi egy.txt
Tehát használjunk egy új kulcsszót az egyezéshez, és jelenítsük meg azokat a sorokat vagy sorokat, amelyek előtt és után azok találhatók. Tehát a „lehet” szót alkalmaztuk. A sorszámok ebben az esetben megegyeznek. Az egyeztetett „lehet” szó utáni 3 sor a grep paranccsal jelenik meg alább.
$ grep -A 3 lehet egy.txt
Láthatja a kimenetet az egyező szó sorai előtt, a „can” kulcsszóval. Ezzel szemben csak két sort mutat az egyező szó sora előtt, mert előtte nincs több sor.
$ grep -B 3 tud egyet.txt
02. példa: '-A' és '-B' használata
Vegyünk egy másik szövegfájlt: „kettőt.txt, ”a saját könyvtárból, és jelenítse meg annak tartalmát az alábbi„ cat ”paranccsal.
$ macska kettő.txt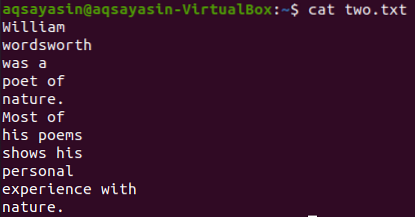
Jelenítsünk meg 5 sort a „Most” szó előtt a „Most” szó előtt.txt ”a grep paranccsal. A kimenet 5 sort mutat, mielőtt a sor egy adott szót tartalmazna.
$ grep -B 5 A legtöbb kettő.txt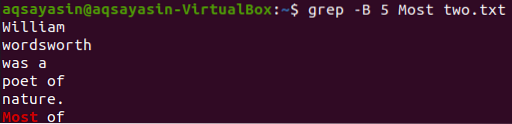
A grep parancs megmutatja az 5 sort a „Most” szó után a „Most” szó után.txt ”az alábbiakban került megadásra.
$ grep -A 5 A legtöbb kettő.txt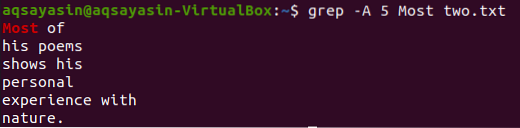
Változtassuk meg a keresendő kulcsszót. Az „of” -t kulcsszóként fogjuk használni, amelyet ezúttal egyeztetni kell. Jelenítse meg a „kettő” szövegfájlból a „of” szó előtti 2 sort.txt ”az alábbi grep paranccsal hajtható végre. A kimenet két sort mutat a „of” kulcsszóhoz, mert kétszer kerül a fájlba. Így a kimenet több mint 2 sort tartalmaz.
$ grep -B 2 kettőből.txt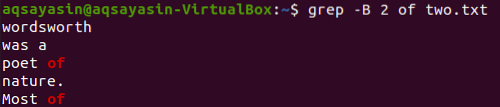
Most a fájl két sorát jeleníti meg: „kettő.txt ”a„ of ”kulcsszót tartalmazó sor után az alábbi paranccsal végezhető el. A kimenet ismét több mint 2 sort jelenít meg.
$ grep -A kettőből 2.txt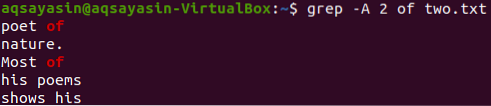
03. példa: '-C' használata
Egy másik jelzőt, a „-C” -et használták az egyező szó előtti és utáni sorok megjelenítésére. Jelenítsük meg a fájl tartalmát: „egy.txt ”a cat paranccsal.
$ cat one.txt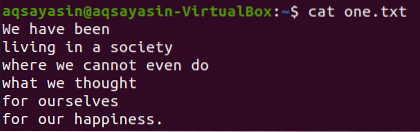
A „társadalom” -t választjuk egyeztetendő kulcsszóként. Az alábbi grep parancs megjeleníti a 2 sor előtti és 2 sort a „társadalom” szót tartalmazó sor előtt. A kimenet egy sort mutat az adott szó sor előtt és 2 sort utána.
$ grep -C 2 társadalom.txt
Lássuk a „kettő fájl tartalmát.txt ”az alábbi macska paranccsal.
$ macska kettő.txt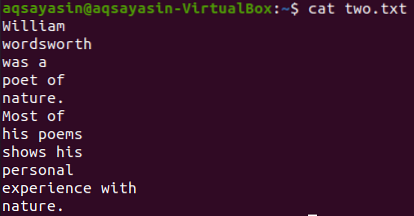
Ezen az ábrán „verseket” használunk kulcsszóként, hogy megfeleljünk. Tehát hajtsa végre az alábbi parancsot. A kimenet két sort mutat az egyező szó előtt és két sort.
$ grep -C 2 vers kettő.txt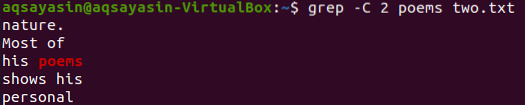
Használjunk még egy kulcsszót a „kettő fájlból.txt ”illesztendő. A „természetet” ezúttal kulcsszóként fogyasztjuk. Tehát próbálkozzon az alábbi paranccsal, miközben a „-C” jelzőt használja a „kettő” fájlból a „természet” kulcsszóval.txt ”. Ezúttal a kimenetnek több mint két sora van a kimenetben. Mivel a fájl többször tartalmazza a „természet” szót, ez az oka annak. Az első helyen álló „természet” kulcsszó előtt két és utána két sor található. Míg a második egyezik ugyanazzal a kulcsszóval, a „természet” előtt két sor van, de nincsenek sorok utána, mert a fájl utolsó sorában található.
$ grep -C 2 vers kettő.txt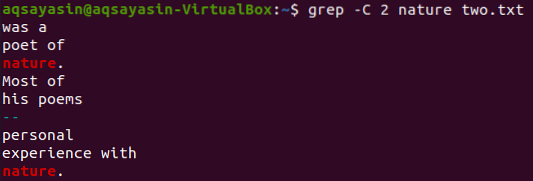
Következtetés
Sikeresen jelenítjük meg a sorokat az adott szó előtt és után a grep utasítás használata közben.


