pip telepítse a BeautifulSoup4-et
Annak ellenőrzéséhez, hogy a telepítés sikeres volt-e, aktiválja a Python interaktív héjat, és importálja a BeautifulSoup programot. Ha nem jelenik meg hiba, ez azt jelenti, hogy minden rendben ment. Ha nem tudja, hogyan járjon el, írja be a következő parancsokat a termináljába.
$ pythonPython 3.5.2 (alapértelmezett, 2017. szeptember 14., 22:51:06)
[ÖET 5.4.0 20160609] a linuxon
Írja be a "help", a "copyright", a "credit" vagy a "license" szót további információkért.
>>> import bs4
A BeautifulSoup könyvtár használatához html-ben kell átadnia. Ha valódi webhelyekkel dolgozik, akkor a weboldal HTML-fájlját a request könyvtár segítségével szerezheti be. A Request Library telepítése és használata meghaladja a cikk kereteit, azonban megismerkedhet a dokumentációval, amelyet nagyon könnyű használni. Ehhez a cikkhez egyszerűen a html-t fogjuk használni egy python karakterláncban, amelyet hívnánk html.
html = "" "[e-mail védett]
pparkerworks.com
"" "
A beautifulsoup használatához az alábbi kód segítségével importáljuk a kódba:
a bs4-ből a BeautifulSoup importálásaEz bevonná a BeautifulSoup-ot a névtérbe, és használhatjuk a karakterláncunk elemzéséhez.
leves = BeautifulSoup (html, "lxml")Most, leves egy bs4 típusú BeautifulSoup objektum.És elvégezhetjük az összes BeautifulSoup műveletet a levesváltozó.
Vessünk egy pillantást néhány dologra, amit most megtehetünk a BeautifulSoup segítségével.
CSINÁLJÁK, SZÉPEK
Amikor a BeautifulSoup elemzi a html fájlt, akkor az általában nem a legjobb formátumú. A távolság nagyon szörnyű. A címkéket nehéz megtalálni. Itt van egy kép, amely megmutatja, hogy néznének ki, amikor kinyomtatja leves:
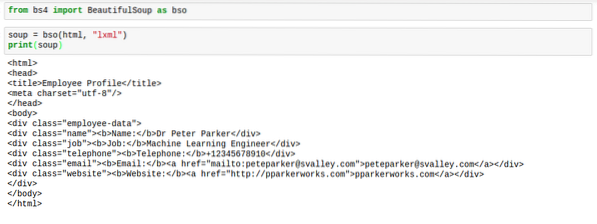
Erre azonban van megoldás. A megoldás biztosítja a html számára a tökéletes távolságot, így a dolgok jól néznek ki. Ezt a megoldást méltán hívják „szépít„.
Igaz, lehet, hogy a legtöbbször nem fogja használni ezt a funkciót; előfordulhat azonban, hogy előfordulhat, hogy nem fér hozzá a webböngésző elem elem eszközéhez. A korlátozott erőforrások idején a prettify módszer nagyon hasznosnak tűnik.
Így használja:
leves.szépít()A jelölés megfelelő távolságban lenne, akárcsak az alábbi képen:
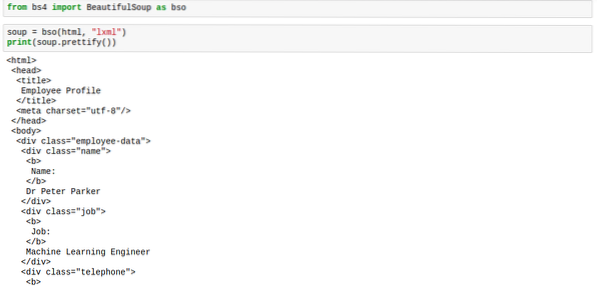
Amikor a prettify metódust alkalmazza a levesre, az eredmény már nem bs4 típusú.BeautifulSoup. Az eredmény most 'unicode' típusú. Ez azt jelenti, hogy nem alkalmazhatsz rajta más BeautifulSoup módszert, azonban magát a levest ez nem érinti, így biztonságban vagyunk.
KEDVENC CÍMKÉNK KERESÉSE
A HTML címkékből áll. Az összes adatot tárolja bennük, és minden rendetlenség közepette ott rejlenek a szükséges adatok. Alapvetően ez azt jelenti, hogy ha megtaláljuk a megfelelő címkéket, megszerezhetjük, amire szükségünk van.
Tehát hogyan találjuk meg a megfelelő címkéket? Kihasználjuk a BeautifulSoup keresési és keresési_all módszerét.
Így működnek:
A megtalálja A method megkeresi a szükséges névvel ellátott első címkét, és egy bs4 típusú objektumot ad vissza.elem.Címke.
A Találd meg mindet metódus viszont megkeresi az összes címkét a szükséges címke nevével, és visszaadja őket a bs4 típusú listaként.elem.ResultSet. A lista összes eleme bs4 típusú.elem.Tag, így indexelést hajthatunk végre a listán, és folytathatjuk a gyönyörű leves felfedezését.
Lássunk néhány kódot. Keressük meg az összes div taget:
leves.keresés („div“)A következő eredményt kapnánk:
A html változó ellenőrzésével észreveheti, hogy ez az első div tag.
leves.find_all („div“)A következő eredményt kapnánk:
[[e-mail védett]
pparkerworks.com
Visszaad egy listát. Ha például a harmadik div taget szeretné, akkor a következő kódot futtatja:
leves.find_all („div“) [2]Ez a következőket adja vissza:
KEDVENC MEGJEGYZÉSEINK MEGÁLLAPÍTÁSA
Most, hogy láttuk, hogyan szerezhetjük be a kedvenc címkéinket, hogyan lehetne megszerezni az attribútumaikat?
Lehet, hogy ezen a ponton gondolkodik: „Mire van szükségünk attribútumokra?„. Nos, sokszor a legtöbb adat, amelyre szükségünk van, e-mail címek és webhelyek lesznek. Ez a fajta adat általában hiperhivatkozással rendelkezik a weboldalakon, a linkek pedig a „href” attribútumban vannak.
Amikor kinyertük a szükséges címkét, a find vagy find_all metódusok használatával attribútumokat kaphatunk alkalmazással vonzza. Ez visszaadná az attribútum szótárát és értékét.
Például az e-mail attribútum megszerzéséhez megkapjuk a címkéket, amelyek körülveszik a szükséges információkat, és tegye a következőket.
leves.find_all („a“) [0].vonzzaAmely a következő eredményt adná:
'href': 'mailto: [e-mail védett]'Ugyanez a helyzet a weboldal attribútummal.
leves.find_all („a“) [1].vonzzaAmely a következő eredményt adná:
'href': 'http: // pparkerworks.com'A visszaadott értékek szótárak, és a kulcsok és értékek megszerzéséhez normál szótári szintaxis alkalmazható.
LÁTUK A SZÜLŐT ÉS A GYEREKEKET
Mindenhol vannak címkék. Néha szeretnénk tudni, hogy mi a gyermekcímke és mi a szülőcímke.
Ha még nem tudja, mi a szülő- és gyermekcímke, akkor ennek a rövid magyarázatnak elegendőnek kell lennie: a szülőcímke a közvetlen külső címke, a gyermek pedig a kérdéses címke közvetlen belső címkéje.
Ha megnézzük html-jünket, a body tag az összes div tag szülőcímkéje. A félkövér tag és a horgonycímke a div tagok gyermekei, ahol alkalmazható, mivel nem minden div tag rendelkezik horgonycímkével.
Így elérhetjük a szülőcímkét a findParent módszer.
leves.keresés ("div").findParent ()Ez visszaadná a törzscímke egészét:
[e-mail védett]
pparkerworks.com
A negyedik div tag gyermek címkéjének megszerzéséhez hívjuk a findGyerekek módszer:
leves.find_all ("div") [4].findGyerekek ()A következőket adja vissza:
[Weboldal:, pparkerworks.com]MI VAN NEKÜNK?
Weboldalak böngészése során nem mindenhol látunk címkéket a képernyőn. Csak a különböző címkék tartalmát látjuk. Mi van, ha egy címke tartalmát akarjuk, anélkül, hogy az összes szögletes zárójel kényelmetlenné tenné az életet? Ez nem nehéz, csak annyit tennénk, hogy felhívnánk get_text módszer a választott címkén, és megkapjuk a szöveget a címkében, és ha a címkében vannak más címkék, akkor megkapja a szöveges értékeket is.
Íme egy példa:
leves.lelet ("test").get_text ()Ez visszaadja a törzscímke összes szövegértékét:
Név: Dr. Peter ParkerMunka: Gépi tanulási mérnök
Telefon: +12345678910
E-mail: [e-mail védett]
Weboldal: pparkerworks.com
KÖVETKEZTETÉS
Ezt kaptuk meg erről a cikkről. Vannak azonban még más érdekességek, amelyeket el lehet készíteni a gyönyörű levessel. Megnézheti a dokumentációt vagy felhasználhatja dir (BeautfulSoup) az interaktív héjon, hogy megtekinthesse a BeautifulSoup objektumon végrehajtható műveletek listáját. Ez mind tőlem ma, amíg újra nem írok.


