A teljes szöveges keresés fogalmának megértéséhez a LIKE kulcsszóval vissza kell emlékeznie a mintakeresési ismeretekre. Tehát tegyük fel, hogy egy "személy" tábla az "teszt" adatbázisban a következő rekordokkal szerepel.
>> SELECT * FROM személy;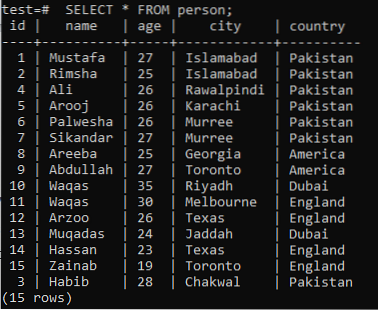
Tegyük fel, hogy be akarja tölteni ennek a táblának a rekordjait, ahol a „name” oszlop bármelyikében „i” karakter szerepel. Próbálja ki az alábbi SELECT lekérdezést, miközben használja a LIKE záradékot a parancsértelmezőben. Az alábbi kimenetből láthatja, hogy a 'név' oszlopban csak 5 rekord van az adott 'i' karakterhez.
>> KIVÁLASZTÁS * FROM személytől, HOL NEVE LIKE '% i%';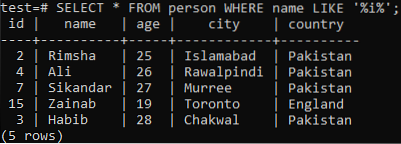
A Tvsector használata:
Időnként nem hasznos a LIKE kulcsszó használata a gyors mintakereséshez, bár a szó ott van. Lehet, hogy fontolgatná a standard kifejezések használatát, és bár ez egy megvalósítható alternatíva, a reguláris kifejezések egyaránt erősek és lassúak. Ha egy szövegben teljes szavakra van eljárási vektor, ezeknek a szavaknak a népi leírása sokkal hatékonyabb módszer a probléma kezelésére. A teljes szöveges keresés és a tsvector adattípus fogalmát erre hozták létre. Két módszer létezik a PostgreSQL-ben, amelyek pontosan azt teszik, amit szeretnénk:
- To_tvsector: A tokenek listájának elkészítésére szolgál (ts a „szöveges keresést” jelenti).
- To_tsquery: Meghatározott kifejezések vagy kifejezések előfordulásának keresésére szolgál a vektorban.
01. példa:
Kezdjük egy vektor létrehozásának egyszerű ábrájával. Tegyük fel, hogy vektort akarsz készíteni a húrhoz: „Néhány embernek megfelelő ecseteléssel göndör barna haja van.”. Tehát írnia kell egy to_tvsector () függvényt ezzel a mondattal együtt a SELECT lekérdezés zárójelébe, az alábbiak szerint. Az alábbi kimenetből láthatja, hogy referenciák (fájlpozíciók) vektort eredményezne az egyes tokeneknél, és ott is, ahol szándékosan figyelmen kívül hagyják a kevés kontextusú kifejezéseket, például a cikkeket (a) és a kötőszókat (és, vagy).
>> SELECT to_tsvector ('Egyeseknek göndör barna haja van a megfelelő fogmosás révén');
02. példa:
Tegyük fel, hogy van két dokumentum, amelyekben mindkettő tartalmaz néhány adatot. Ezen adatok tárolásához most egy valódi példát fogunk használni a tokenek létrehozására. Tegyük fel, hogy létrehozott egy „Data” táblázatot az adatbázis „tesztjében”, benne néhány oszloppal, az alábbi TABLE létrehozása. Ne felejtsen el létrehozni egy „token” nevű TVSECTOR típusú oszlopot. Az alábbi kimenetből megnézheti a létrehozott táblázatot.
>> CREATE TABLE Data (ID SOROZATI ELSŐDLEGES KULCS, info TEXT, token TSVECTOR);
Most eldönthetjük, hogy hozzáadjuk-e a táblázat mindkét dokumentumának általános adatait. Tehát próbálkozzon az alábbi INSERT paranccsal a parancssori héjában. Végül mindkét dokumentum rekordjait sikeresen hozzáadták az „Data” táblához.
>> INSERT INTO Data (info) ÉRTÉKEK ('Két hibával soha nem lehet egy embert helyrehozni.'), (' Ő tud futballozni.'), (' Játszhatok ebben szerepet?'), ("Az ember belsejében lévő fájdalmat nem lehet megérteni"), ("Hozzon őszibarackot az életébe);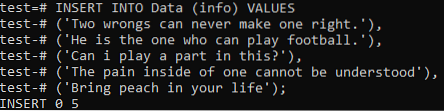
Most meg kell telepítenie mindkét dokumentum token oszlopát az adott vektorral. Végül egy egyszerű UPDATE lekérdezés kitölti a tokenek oszlopát a megfelelő vektorral az egyes fájlokhoz. Tehát az alábbi lekérdezést kell végrehajtania a parancs-shellben. A kimenet azt mutatja, hogy a frissítés végre elkészült.
>> UPDATE Data f1 SET token = to_tsvector (f1.info) FROM Data f2;
Most, hogy mindez megvan a helyén, térjünk vissza a „lehet-e” szkenneléssel kapcsolatos ábránkra. Az AND operátorral való to_squery lekérdezéshez, amint azt korábban említettük, nincs különbség a fájlok helye között a fájlokban, amint az az alábbi kimeneten látható.
>> SELECT ID, info FROM Data WHERE token @@ to_tsquery ('lehet & egy');
44. példa:
Az egymás melletti szavak megtalálásához ugyanazt a lekérdezést próbáljuk meg a '<->' operátor. A változás az alábbi kimenetben jelenik meg.
>> SELECT ID, info FROM Data WHERE token @@ to_tsquery ('lehet <-> egy');
Itt van egy példa arra, hogy nincs közvetlen szó a másik mellett.
>> SELECT ID, info FROM Data WHERE token @@ to_tsquery ('egy <-> fájdalom');
05. példa:
Megtaláljuk azokat a szavakat, amelyek nincsenek közvetlenül egymás mellett, ha a távolságoperátorban egy számot használunk a távolság referenciaként. A 'hoz' és az 'élet közelsége 4 szó választja el a megjelenített képet.
>> SELECT * FROM Data WHERE token @@ to_tsquery ('bring <4> élet');
A szavak közelségének ellenőrzéséhez közel 5 szóra az alábbiakban csatoltuk.
>> SELECT * FROM Data WHERE token @@ to_tsquery ('helytelen <5> jobb');
Következtetés:
Végül elvégezte a teljes szöveges keresés összes egyszerű és bonyolult példáját a To_tvsector és a to_tsquery operátorok és függvények használatával.


