- Mi a Pandas csomag
- Telepítés és az első lépések
- Adatok betöltése CSV-ből a Pandas DataFrame-be
- Mi az a DataFrame és hogyan működik
- DataFrames szeletelése
- Matematikai műveletek a DataFrame felett
Úgy tűnik, hogy sokat kell fedezni. Kezdjük most.
Mi a Python Pandas csomag?
A Pandas honlapja szerint: a pandas egy nyílt forráskódú, BSD-engedéllyel rendelkező könyvtár, amely nagy teljesítményű, könnyen használható adatstruktúrákat és adatelemző eszközöket kínál a Python programozási nyelv számára.
Az egyik legmenőbb dolog a Pandas-ban az, hogy lehetővé teszi adatok elolvasását olyan általános adatformátumokból, mint a CSV, az SQL stb. nagyon egyszerű, ami egyformán használható gyártási szintű alkalmazásokban vagy csak néhány demo alkalmazásban.
Telepítse a Python Pandas alkalmazást
Csak egy megjegyzés a telepítési folyamat megkezdése előtt, ehhez a leckéhez egy virtuális környezetet használunk, amelyet a következő paranccsal készítettünk:
python -m virtualenv pandákforrás pandák / bin / aktiválás
Amint a virtuális környezet aktív, a pandas könyvtárat telepíthetjük a virtuális env-be, hogy a következő módon létrehozott példák végrehajthatók legyenek:
pip install pandákVagy használhatjuk a Condát a csomag telepítéséhez a következő paranccsal:
conda telepíteni pandákatValami ilyesmit látunk, amikor végrehajtjuk a fenti parancsot:
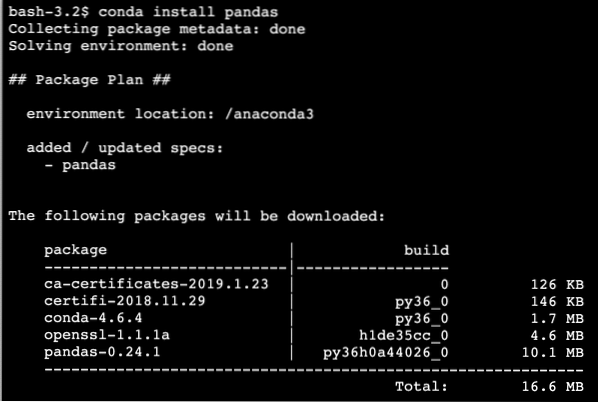
Miután a telepítés befejeződött a Condával, a csomagot Python szkriptjeinkben a következőképpen használhatjuk:
import pandák, mint pdMost kezdjük el használni a Pandákat a szkriptjeinkben.
CSV fájl olvasása Pandas DataFrames segítségével
CSAND fájl olvasása a Pandas segítségével egyszerű. Bemutatás céljából elkészítettünk egy kis CSV fájlt a következő tartalommal:
Név, névjegyzék, belépés dátuma, vészhelyzeti kapcsolatfelvételShubham, 1,20-05-2012,9988776655
Gagan, 2,20-05-2009, 8364517829
Oshima, 3,20-05-2003,5454223344
Vyom, 4,20-05-2009,1223344556
Ankur, 5,20-05-1999,9988776655
Vinod, 6,20-05-1999,9988776655
Vipin, 7,20-05-2002, 9988776655
Ronak, 8,20-05-2007,1223344556
DJ, 9,20-05-2014,9988776655
VJ, 10,20-05-2015, 9988776655
Mentse el ezt a fájlt a Python szkript könyvtárába. Miután a fájl megtalálható, adja hozzá a következő kódrészletet egy Python-fájlhoz:
import pandák, mint pddiákok = pd.read_csv ("diákok.csv ")
diákok.fej()
A fenti kódrészlet futtatása után a következő kimenetet látjuk:
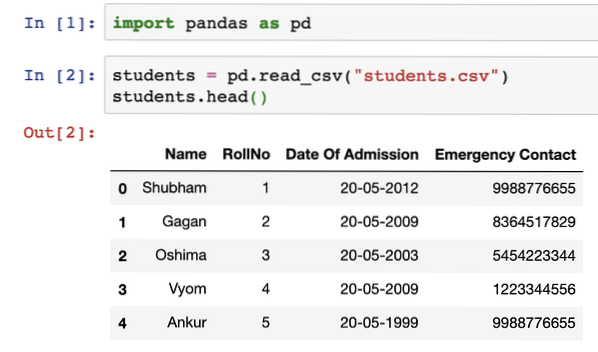
A Pandas fej () függvényével meg lehet mutatni a DataFrame-ben jelen lévő adatok mintáját. Várjon, DataFrame? Sokkal többet fogunk tanulmányozni a DataFrame-ről a következő szakaszban, de csak megértsük, hogy a DataFrame egy n-dimenziós adatstruktúra, amely felhasználható egy adatkészleten keresztüli komplex műveletek tárolására és elemzésére.
Azt is láthatjuk, hogy az aktuális adatok hány sort és oszlopot tartalmaznak:
diákok.alakA fenti kódrészlet futtatása után a következő kimenetet látjuk:

Ne feledje, hogy a pandák a 0-tól kezdődő sorok számát is megszámolják.
Lehetséges, hogy csak egy oszlopot kap a listában a Pandas. Ez megtehető a indexelés Pandákban. Nézzünk meg egy rövid kódrészletet ugyanarról:
student_names = hallgatók ['Név']hallgató_nevek
A fenti kódrészlet futtatása után a következő kimenetet látjuk:
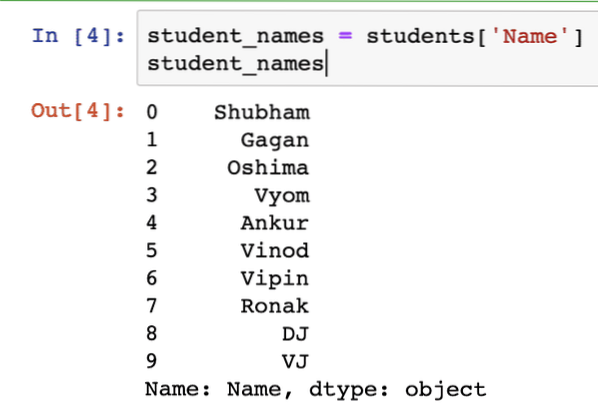
De ez nem úgy néz ki, mint egy lista, ugye? Nos, kifejezetten meg kell hívnunk egy függvényt az objektum listává alakításához:
hallgatónevek = tanulónevek.tolist ()hallgató_nevek
A fenti kódrészlet futtatása után a következő kimenetet látjuk:
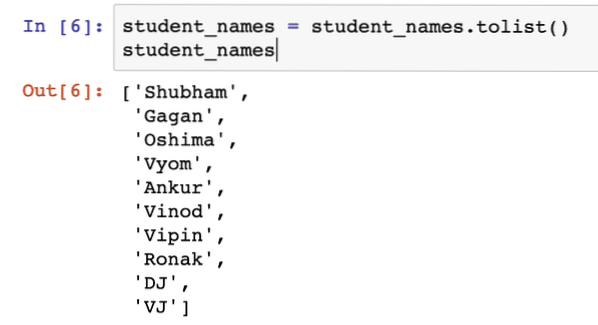
Csak további információkért győződhetünk meg arról, hogy a lista minden eleme egyedi, és csak nem üres elemeket választunk néhány egyszerű ellenőrzés hozzáadásával, például:
student_names = hallgatók ['Név'].dropna ().egyedi().tolist ()Esetünkben a kimenet nem változik, mivel a lista már nem tartalmaz szabálytalanságokat.
Készíthetünk DataFrame-et is nyers adatokkal, és az oszlopneveket továbbadhatjuk velük együtt, amint az a következő kódrészletben látható:
my_data = pd.DataFrame ([
[1, "Chan"],
[2, "Smith"],
[3, "Winslet"]
],
oszlop = ["Helyezés", "Vezetéknév"]
)
adataim
A fenti kódrészlet futtatása után a következő kimenetet látjuk:

DataFrames szeletelése
A DataFrame lebontása csak a kiválasztott sorok és oszlopok kibontása érdekében fontos funkció, hogy a figyelmet az adatok szükséges részeire irányítsuk, amelyeket használnunk kell. Ehhez a Pandas lehetővé teszi számunkra, hogy szükség szerint szeleteljük a DataFrame-et, például:
- iloc [: 4 ,:] - kiválasztja az első 4 sort és az összes oszlopot ezekhez a sorokhoz.
- iloc [:,:] - a teljes DataFrame van kiválasztva
- iloc [5:, 5:] - sorok az 5. pozíciótól és oszlopok az 5. pozíciótól.
- iloc [:, 0] - az első oszlop és az oszlop összes sora.
- iloc [9 ,:] - a 10. sor és az adott oszlop összes oszlopa.
Az előző részben már láthattuk az indexelést és az oszlopok nevével való szeletelést az indexek helyett. Keverhető a szeletelés indexszámokkal és oszlopnevekkel is. Nézzünk meg egy egyszerű kódrészletet:
diákok.loc [: 5, 'Név']A fenti kódrészlet futtatása után a következő kimenetet látjuk:

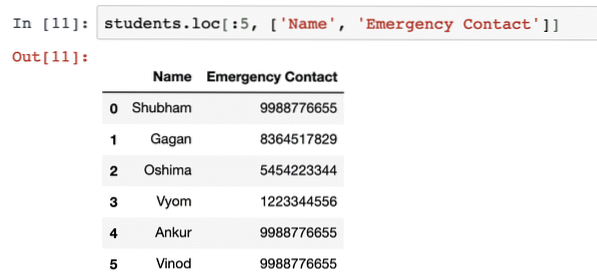
Több oszlop is megadható:
diákok.loc [: 5, ['Név', 'Sürgősségi kapcsolattartó']]A fenti kódrészlet futtatása után a következő kimenetet látjuk:
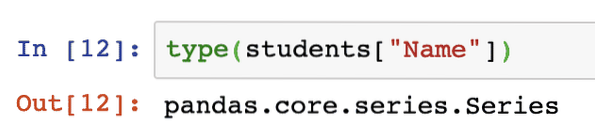
Sorozat adatstruktúrája pandákban
Csakúgy, mint a Pandas (ami egy többdimenziós adatszerkezet), a sorozat egydimenziós adatstruktúra a Pandasban. Ha egy oszlopot lekérünk egy DataFrame-ből, akkor egy sorozattal dolgozunk:
típus (diákok ["név"])A fenti kódrészlet futtatása után a következő kimenetet látjuk:
Saját sorozatunkat is elkészíthetjük, itt van egy kódrészlet ugyanahhoz:
sorozat = pd.Sorozat (['Shubham', 3.7])sorozat
A fenti kódrészlet futtatása után a következő kimenetet látjuk:

Amint az a fenti példából kitűnik, egy sorozat több adattípust is tartalmazhat ugyanahhoz az oszlophoz.
Logikai szűrők a Pandas DataFrame-ben
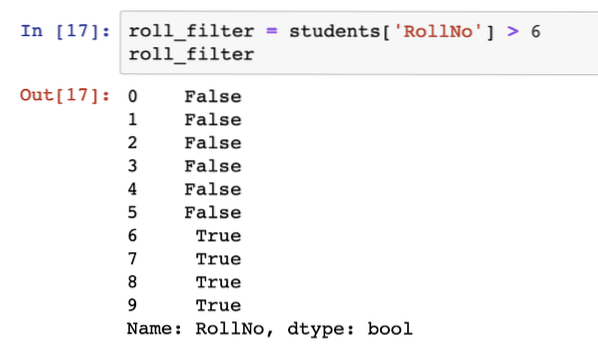
Az egyik jó dolog a Pandas-ban az, hogy hogyan lehet adatokat kinyerni egy DataFrame-ből egy feltétel alapján. Csakúgy, mint a hallgatók kivonása, ha a tekercsek száma nagyobb, mint 6:
roll_filter = hallgatók ['RollNo']> 6roll_filter
A fenti kódrészlet futtatása után a következő kimenetet látjuk:
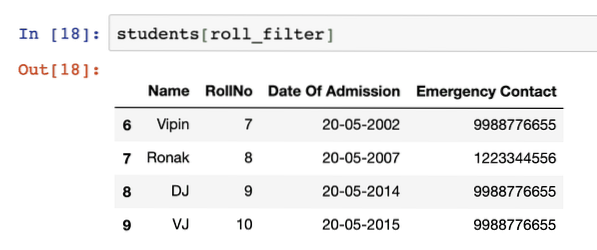
Nos, erre nem számítottunk. Bár a kimenet meglehetősen egyértelmű arról, hogy mely sorok elégítették ki az általunk megadott szűrőt, de még mindig nincsenek pontos sorok, amelyek kielégítették ezt a szűrőt. Kiderült szűrőket használhatunk DataFrame indexként is:
diákok [tekercsszűrő]A fenti kódrészlet futtatása után a következő kimenetet látjuk:
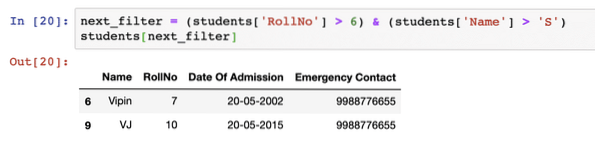
Lehetőség van több feltétel használatára egy szűrőben, hogy az adatok egy tömör szűrőn szűrhetők legyenek, például:
következő_szűrő = (hallgatók ['RollNo']> 6) és (hallgatók ['Név']> 'S')diákok [következő_szűrő]
A fenti kódrészlet futtatása után a következő kimenetet látjuk:
Medián kiszámítása
A DataFrame-ben számos matematikai függvényt is kiszámolhatunk. Jó példát adunk a medián kiszámítására. A medián egy dátumra lesz kiszámítva, nem csak a számokra. Nézzünk meg egy rövid kódrészletet ugyanarról:
dátumok = hallgatók ['Felvételi dátum'].astype ('datetime64 [ns]').kvantilis (.5)dátumokat
A fenti kódrészlet futtatása után a következő kimenetet látjuk:

Ezt úgy értük el, hogy először indexeltük a dátum oszlopot, majd adattípust adtunk az oszlopnak, hogy a Pandas helyesen következtethessen rá, amikor a kvantilis függvényt alkalmazza a medián dátum kiszámításához.
Következtetés
Ebben a leckében megvizsgáltuk a Pandas feldolgozási könyvtárának különböző aspektusait, amelyeket a Python segítségével használhatunk a különböző forrásokból származó adatok gyűjtésére egy DataFrame adatstruktúrába, amely lehetővé teszi számunkra az adatkészlet kifinomult működését. Ez lehetővé teszi számunkra, hogy olyan részhalmazokat kapjunk, amelyeken pillanatnyilag dolgozni akarunk, és számos matematikai műveletet biztosít.
Kérjük, ossza meg visszajelzését a leckéről a Twitteren a @sbmaggarwal és a @LinuxHint oldalakon.


