Például egy vállalkozás futtathat egy szövegelemző motort, amely feldolgozza a vállalkozásával kapcsolatos tweeteket, megemlítve a cég nevét, helyét, folyamatát és elemezve az adott tweethez kapcsolódó érzelmeket. A helyes cselekvések gyorsabban megtehetők, ha az adott vállalkozás megismeri a negatív tweetek növekvő számát egy adott helyen, hogy megmentse magát egy baklövéstől vagy bármi mástól. Egy másik gyakori példa erre Youtube. A Youtube rendszergazdái és moderátorai megismerik a videó hatását, a videóhoz fűzött megjegyzések vagy a videocsevegési üzenetek típusától függően. Ez sokkal gyorsabban segít megtalálni a nem megfelelő tartalmat a webhelyen, mert most felszámolták a kézi munkát és automatizált intelligens szövegelemző robotokat alkalmaztak.
Ebben a leckében a szövegelemzéssel kapcsolatos fogalmakat tanulmányozzuk az NLTK könyvtár segítségével a Pythonban. Ezen fogalmak közül néhány a következőket foglalja magában:
- Tokenizálás, hogyan lehet egy szövegrészt szavakra, mondatokra bontani
- Kerülje az angol nyelvű megállító szavakat
- Stemming és lemmatization végrehajtása egy szövegdarabon
- Az elemzendő tokenek azonosítása
Az NLP lesz a fő fókuszterület ebben a leckében, mivel hatalmas valós élethelyzetekre alkalmazható, ahol nagy és döntő problémákat képes megoldani. Ha úgy gondolja, hogy ez összetettnek hangzik, akkor igen, de a fogalmak ugyanolyan könnyen érthetők, ha egymás mellé próbálunk példákat. Kezdjük az NLTK telepítésével a gépedre, hogy elkezdhessük.
Az NLTK telepítése
Csak egy megjegyzés, mielőtt elkezdené, használhat virtuális környezetet ehhez a leckéhez, amelyet a következő paranccsal készíthetünk:
python -m virtualenv nltkforrás nltk / bin / activ
Miután a virtuális környezet aktív, telepítheti az NLTK könyvtárat a virtuális env-be, hogy a következő módon létrehozott példák végrehajthatók legyenek:
pip install nltkEbben a leckében felhasználjuk az Anacondát és a Jupytert. Ha telepíteni szeretné a számítógépére, nézze meg a „Hogyan telepítsük az Anaconda Python-ot az Ubuntu 18-ra” című leckét.04 LTS ”, és ossza meg visszajelzését, ha bármilyen problémába ütközik. Az NLTK Anaconda alkalmazással történő telepítéséhez használja a következő parancsot az Anaconda termináljában:
conda install -c anaconda nltkValami ilyesmit látunk, amikor végrehajtjuk a fenti parancsot:
Miután az összes szükséges csomag telepítve és elkészült, elkezdhetjük az NLTK könyvtár használatát a következő importálási utasítással:
import nltkKezdjük az NLTK alapvető példáival, miután telepítettük az előfeltételek csomagjait.
Tokenizálás
A tokenizálással kezdjük, amely a szövegelemzés első lépése. A token a szöveg bármely elemének kisebb része lehet, amelyet elemezni lehet. A tokenizálásnak két típusa végezhető el az NLTK segítségével:
- Mondatjelzés
- Szó tokenizálás
Kitalálhatja, hogy mi történik az egyes tokenizálásokkal, ezért merüljünk el a kód példákban.
Mondatjelzés
Ahogy a név is tükrözi, a mondatjelzők mondatokra bontják a szöveget. Próbálkozzunk egy egyszerű kódrészlettel ugyanahhoz, ahol az Apache Kafka oktatóanyagból kiválasztott szöveget használjuk fel. Mi elvégezzük a szükséges importokat
import nltkaz nltk-ból.tokenize import import_tokenize
Felhívjuk figyelmét, hogy hibával szembesülhet a meghívott nltk hiányzó függősége miatt punkt. A figyelmeztetések elkerülése érdekében közvetlenül a program importja után adja hozzá a következő sort:
nltk.letöltés ('punkt')Számomra a következő eredményt adta:
Ezután felhasználjuk az importált mondatjelzőt:
text = "" "A Kafka témája üzenet küldése. A fogyasztóaz adott téma iránt érdeklődő alkalmazások ebbe az üzenetbe húznak
témát, és bármit megtehet az adatokkal. Egy adott időpontig tetszőleges számú
a fogyasztói alkalmazások tetszőleges számú alkalommal kihúzhatják ezt az üzenetet."" "
mondatok = sent_tokenize (szöveg)
nyomtatás (mondatok)
Valami ilyesmit látunk, amikor a fenti parancsfájlt végrehajtjuk:

Ahogy az várható volt, a szöveget helyesen mondatokba rendezték.
Szó tokenizálás
Ahogy a név is tükrözi, a Word Tokenizer szavakra bontja a szöveget. Próbálkozzunk egy egyszerű kódrészlettel, ugyanazzal a szöveggel, mint az előző példa:
az nltk-ból.tokenize import word_tokenizeszavak = word_tokenize (szöveg)
nyomtatás (szavak)
Valami ilyesmit látunk, amikor a fenti parancsfájlt végrehajtjuk:

Ahogy az várható volt, a szöveget szavakba rendezték megfelelően.
Gyakorisági eloszlását
Most, hogy megtörtük a szöveget, kiszámíthatjuk az egyes szavak gyakoriságát is az általunk használt szövegben. Nagyon egyszerű megtenni az NLTK-val, itt van az általunk használt kódrészlet:
az nltk-ból.valószínűség importálása FreqDistelosztás = FreqDist (szavak)
nyomtatás (terjesztés)
Valami ilyesmit látunk, amikor a fenti parancsfájlt végrehajtjuk:

Ezután megtalálhatjuk a leggyakoribb szavakat a szövegben egy egyszerű függvénnyel, amely elfogadja a megjelenítendő szavak számát:
# A leggyakoribb szavakterjesztés.leggyakoribb (2)
Valami ilyesmit látunk, amikor a fenti parancsfájlt végrehajtjuk:

Végül elkészíthetünk egy frekvenciaeloszlási diagramot, hogy kitisztítsuk a szavakat és azok számát az adott szövegben, és megértsük a szavak eloszlását:

Stopwords
Csakúgy, mint amikor hívással beszélgetünk egy másik személlyel, a hívás során is előfordul némi zaj, ami nem kívánt információ. Ugyanígy a valós világból származó szöveg is zajt tartalmaz, amelyet neveznek Stopwords. A stopszavak nyelvenként változhatnak, de könnyen azonosíthatók. Az angol nyelvű kulcsszavak egy része lehet, van, van, a, stb.
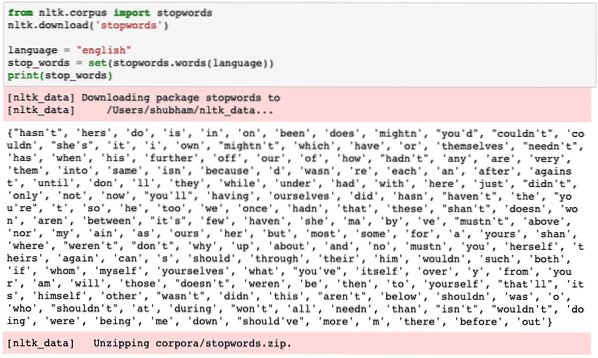
Megtekinthetjük azokat a szavakat, amelyeket az NLTK az angol nyelvben Stopwords-nak tekint, a következő kódrészlettel:
az nltk-ból.corpus import stopwordsnltk.letöltés ('stopwords')
nyelv = "angol"
stop_words = set (stopwords.szavak (nyelv))
nyomtatás (stop_words)
Mivel a stop szavak készlete természetesen nagy lehet, külön adatkészletként kerül tárolásra, amelyet az NLTK segítségével lehet letölteni, amint azt a fentiekben bemutattuk. Valami ilyesmit látunk, amikor a fenti parancsfájlt végrehajtjuk:
Ezeket a megállító szavakat el kell távolítani a szövegből, ha pontos szövegelemzést szeretne végezni a megadott szövegdarabhoz. Távolítsuk el a stop szavakat a szöveges jeleinkből:
filtered_words = []szó szavakkal:
ha a szó nem szerepel a stop_words-ben:
filtered_words.függelék (szó)
filtered_words
Valami ilyesmit látunk, amikor a fenti parancsfájlt végrehajtjuk:

Szó eredetű
A szó töve a szó alapja. Például:
A szűrt szavakból fogunk végezni, amelyekből az utolsó részben eltávolítottuk a leállítási szavakat. Írjunk egy egyszerű kódrészletet, ahol az NLTK sztringjét használjuk a művelet végrehajtására:
az nltk-ból.szár import PorterStemmerps = PorterStemmer ()
stemmed_words = []
szó a filtered_words kifejezésben:
stemmed_words.függelék (ps.szár (szó))
nyomtatás ("Származtatott mondat:", stemmed_words)
Valami ilyesmit látunk, amikor a fenti parancsfájlt végrehajtjuk:

POS címkézés
A szöveges elemzés következő lépése a származtatás után az, hogy azonosítsuk és csoportosítsuk az egyes szavakat értékük szerint, azaz.e. ha a szó mindegyike főnév vagy ige vagy valami más. Ezt a Beszédcímkézés részének nevezzük. Most végezzük el a POS címkézést:
tokenek = nltk.word_tokenize (mondatok [0])nyomtatás (tokenek)
Valami ilyesmit látunk, amikor a fenti parancsfájlt végrehajtjuk:

Most elvégezhetjük a címkézést, amelyhez le kell töltenünk egy másik adatkészletet a helyes címkék azonosításához:
nltk.letöltés ('averaged_perceptron_tagger')nltk.pos_tag (tokenek)
Itt van a címkézés kimenete:
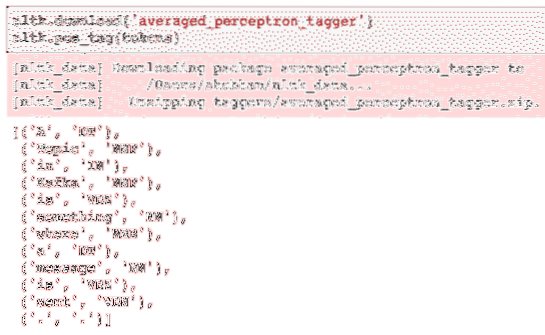
Most, hogy végre azonosítottuk a címkézett szavakat, ez az az adatkészlet, amelyen hangulatelemzést végezhetünk a mondat mögött rejlő érzelmek azonosítására.
Következtetés
Ebben a leckében egy kiváló természetes nyelvi csomagot, az NLTK-t néztünk meg, amely lehetővé teszi számunkra, hogy strukturálatlan szöveges adatokkal dolgozzunk fel minden leállító szót és mélyebb elemzést végezzünk egy éles adatsor előkészítésével a szöveg elemzéséhez olyan könyvtárakkal, mint a sklearn.
Keresse meg az összes ebben a leckében használt forráskódot a Githubon. Kérjük, ossza meg visszajelzését a leckéről a Twitteren a @sbmaggarwal és a @LinuxHint oldalakon.


