Miért van szükség Lucene-re??
A keresés az egyik leggyakoribb művelet, amelyet naponta többször is végrehajtunk. Ez a keresés több weblapon is megtalálható, amelyek léteznek az interneten, vagy egy Zene alkalmazásban, vagy egy kódtárban, vagy ezek kombinációjában. Azt gondolhatja, hogy egy egyszerű relációs adatbázis is támogathatja a keresést. Ez helyes. A MySQL-hez hasonló adatbázisok támogatják a teljes szöveges keresést. De mi a helyzet a webrel vagy a Zene alkalmazással, vagy egy kódtárral, vagy mindezek kombinációjával? Az adatbázis nem tárolhatja ezeket az adatokat az oszlopaiban. Még ha megtörtént is, elfogadhatatlan időbe telik a ekkora keresés futtatása.
A teljes szövegű keresőmotor képes több millió fájlra keresési lekérdezést futtatni egyszerre. Óriási az a sebesség, amellyel ma tárolják az adatokat egy alkalmazásban. A teljes szövegű keresés futtatása ilyen típusú adatmennyiségen nehéz feladat. A szükséges információk ugyanis egyetlen fájlban létezhetnek az interneten tárolt fájlok milliárdjaiból.
Hogyan működik Lucene?
Az a nyilvánvaló kérdés, amelyre eszedbe kellene jutni, az, hogy Lucene milyen gyorsan képes teljes szövegű keresési lekérdezéseket futtatni? A válasz erre természetesen az általa létrehozott indexek segítségével történik. De a klasszikus index létrehozása helyett a Lucene használja Fordított indexek.
A klasszikus indexben minden dokumentumhoz összegyűjtjük a dokumentumban szereplő szavak vagy kifejezések teljes listáját. Invertált indexben az összes dokumentum minden szavára tároljuk, hogy melyik dokumentumban és pozícióban található ez a szó / kifejezés. Ez egy magas színvonalú algoritmus, amely nagyon megkönnyíti a keresést. Tekintsük a klasszikus index létrehozásának alábbi példáját:
Doc1 -> "Ez", "is", "egyszerű", "Lucene", "minta", "klasszikus", "fordított", "index"Doc2 -> "Futás", "Elasticsearch", "Ubuntu", "Frissítés"
Doc3 -> "RabbitMQ", "Lucene", "Kafka", "", "Tavasz", "Csizma"
Ha fordított indexet használunk, akkor olyan indexeink lesznek, mint:
Ez -> (2, 71)Lucene -> (1, 9), (12,87)
Apache -> (12, 91)
Keret -> (32, 11)
A fordított indexeket sokkal könnyebb fenntartani. Tegyük fel, hogy ha meg akarom találni az Apache-t a kifejezésemben, akkor azonnal válaszokat fogok kapni fordított indexekkel, míg a klasszikus keresés teljes dokumentumokon fog futni, amelyeket valószínűleg nem lehetett valós időben futtatni.
Lucene munkafolyamat
Mielőtt a Lucene valóban megkereshetné az adatokat, lépéseket kell végrehajtania. Vizualizáljuk ezeket a lépéseket a jobb megértés érdekében:
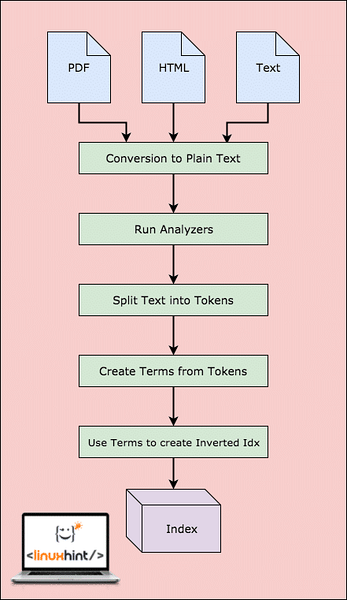
Lucene munkafolyamat
Amint az ábra mutatja, ez történik Lucene-ben:
- A Lucene-nek táplálják a dokumentumokat és más adatforrásokat
- Minden dokumentum esetében a Lucene először ezeket az adatokat egyszerű szöveggé alakítja, majd az Analyzers ezt a forrást egyszerű szöveggé alakítja
- A sima szöveg minden tagjára létrehozzák a fordított indexeket
- Az indexek készen állnak a keresésre
Ezzel a munkafolyammal a Lucene egy nagyon erős teljes szövegű keresőmotor. De Lucene csak ezt teljesíti. Magunknak kell elvégeznünk a munkát. Nézzük meg az Indexelés szükséges összetevőit.
Lucene Components
Ebben a szakaszban leírjuk az indexek létrehozásához használt alapkomponenseket és alapvető Lucene osztályokat:
- Könyvtárak: A Lucene index az adatokat normál fájlrendszeri direktívákban vagy a memóriában tárolja, ha nagyobb teljesítményre van szüksége. Teljesen az alkalmazások választása az adatok tárolása, ahol csak akar, egy adatbázis, a RAM vagy a lemez.
- Dokumentumok: A Lucene motorba betáplált adatokat egyszerű szöveggé kell konvertálni. Ehhez egy dokumentum objektumot készítünk, amely az adatforrást képviseli. Később, amikor futtatunk egy keresési lekérdezést, ennek eredményeként kapunk egy listát azokról a Document objektumokról, amelyek kielégítik az általunk továbbított lekérdezést.
- Mezők: A dokumentumok mezőinek gyűjteményével vannak feltöltve. A Mező egyszerűen egy pár (név, érték) elemeket. Tehát egy új Document objektum létrehozása során meg kell töltenünk azt ilyen párosított adatokkal. Ha egy mezőt fordítottan indexelnek, a mező értéke tokenizált és elérhetővé válik a kereséshez. A Fields használata közben nem fontos a tényleges pár tárolása, hanem csak a fordított indexelés. Így eldönthetjük, hogy mely adatok csak kereshetők és nem fontosak a mentésre. Nézzünk meg egy példát itt:

Terepi indexelés
A fenti táblázatban úgy döntöttünk, hogy egyes mezőket tárolunk, másokat pedig nem tárolunk. A törzsmezőt nem tároljuk, hanem indexeljük. Ez azt jelenti, hogy az e-mail akkor jelenik meg, amikor a törzs tartalmára vonatkozó feltételek egyikének lekérdezése fut.
- Feltételek: A kifejezések egy szót tartalmaznak a szövegből. A kifejezéseket a Fields értékeinek elemzéséből és tokenizálásából vonják ki A kifejezés a legkisebb egység, amelyen a keresés fut.
- Elemzők: Az elemző az indexelés és a keresés legfontosabb része. Az elemző átalakítja a sima szöveget tokenekké és kifejezésekké, hogy azokban keresni lehessen. Nos, nem ez az egyetlen elemző felelőssége. Az elemző Tokenizer-t használ tokenek készítéséhez. Az elemző a következő feladatokat is elvégzi:
- Származás: Az elemző a szót tővé alakítja. Ez azt jelenti, hogy a „virágok” a „virág” törzsszóra változik. Tehát, amikor a „virág” keresésre kerül sor, a dokumentum visszaküldésre kerül.
- Szűrés: Az elemző kiszűri az olyan leállítási szavakat is, mint a 'The', 'is' stb. mivel ezek a szavak nem vonzanak egyetlen futtatandó kérdést sem, és nem eredményesek.
- Normalizálás: Ez a folyamat eltávolítja az ékezeteket és más karakterjelöléseket.
Ez csak a StandardAnalyzer szokásos felelőssége.
Példa alkalmazásra
A sok Maven-archetípus egyikét felhasználjuk egy minta projekt létrehozásához a példánkhoz. A projekt létrehozásához hajtsa végre a következő parancsot egy munkaterületként használt könyvtárban:
mvn archetípus: generál -DgroupId = com.linuxhint.példa -DartifactId = LH-LuceneExample -DarchetypeArtifactId = maven-archetype-quickstart -DinteractiveMode = falseHa először futtatja a maven programot, néhány másodpercbe telik a generálás parancs végrehajtása, mert a mavennek le kell töltenie az összes szükséges plugint és műterméket a generációs feladat elvégzéséhez. Így néz ki a projekt kimenete:
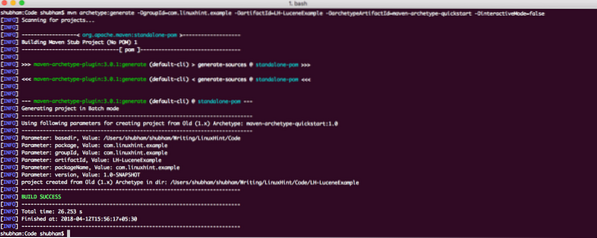
Projekt beállítása
Miután létrehozta a projektet, nyugodtan nyissa meg kedvenc IDE-jében. A következő lépés a megfelelő Maven-függőségek hozzáadása a projekthez. Itt van a pom.xml fájl a megfelelő függőségekkel:
Végül, annak a JAR-nek a megértése érdekében, amely hozzáadódik a projekthez, amikor hozzáadtuk ezt a függőséget, futtathatunk egy egyszerű Maven parancsot, amely lehetővé teszi számunkra, hogy egy teljes függőségfát láthassunk egy projekthez, amikor hozzáadunk néhány függőséget. Itt van egy parancs, amelyet használhatunk:
mvn függőség: faAmikor futtatjuk ezt a parancsot, a következő függőségfát jeleníti meg: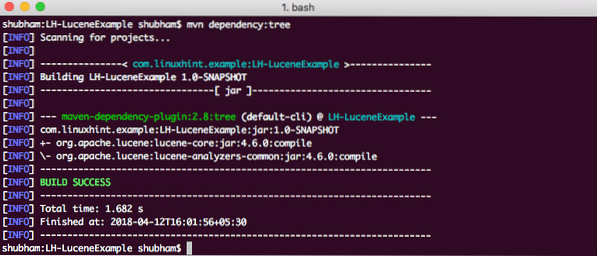
Végül létrehozunk egy SimpleIndexer osztályt, amely fut
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import org.apache.lucén.elemzés.Elemző;
import org.apache.lucén.elemzés.alapértelmezett.StandardAnalyzer;
import org.apache.lucén.dokumentum.Dokumentum;
import org.apache.lucén.dokumentum.StoredField;
import org.apache.lucén.dokumentum.TextField;
import org.apache.lucén.index.IndexWriter;
import org.apache.lucén.index.IndexWriterConfig;
import org.apache.lucén.bolt.FSDirectory;
import org.apache.lucén.haszn.Változat;
nyilvános osztály SimpleIndexer
privát statikus végső String indexDirectory = "/ Felhasználók / shubham / valahol / LH-LuceneExample / Index";
privát statikus végső karakterlánc dirToBeIndexed = "/ Felhasználók / shubham / valahol / LH-LuceneExample / src / main / java / com / linuxhint / example";
public static void main (String [] args) dobja a Kivételt
File indexDir = new File (indexDirectory);
File dataDir = új fájl (dirToBeIndexed);
SimpleIndexer indexelő = új SimpleIndexer ();
int numIndexed = indexelő.index (indexDir, dataDir);
Rendszer.ki.println ("Összes indexelt fájl" + numIndexed);
private int index (File indexDir, File dataDir) dobja az IOException
Analyzer analyzer = new StandardAnalyzer (Version.LUCENE_46);
IndexWriterConfig config = new IndexWriterConfig (verzió.LUCENE_46,
analizátor);
IndexWriter indexWriter = új IndexWriter (FSDirectory.nyitott (indexDir),
konfig);
Fájl [] fájlok = dataDir.listFiles ();
a (f fájl: fájlok)
Rendszer.ki.println ("Indexelési fájl" + f.getCanonicalPath ());
Document doc = új dokumentum ();
doc.add (új TextField ("tartalom", új FileReader (f)));
doc.add (új StoredField ("fájlnév", f.getCanonicalPath ()));
indexWriter.addDocument (doc);
int numIndexed = indexWriter.maxDoc ();
indexWriter.Bezárás();
return numIndexed;
Ebben a kódban éppen létrehoztunk egy Dokumentum példányt, és hozzáadtunk egy új mezőt, amely a Fájl tartalmát képviseli. Itt van a kimenet, amelyet a fájl futtatásakor kapunk:
Indexelő fájl / Felhasználók / shubham / valahol / LH-LuceneExample / src / main / java / com / linuxhint / example / SimpleIndexer.JávaÖsszes indexelt fájl 1
Ezenkívül egy új könyvtár jön létre a projekten belül a következő tartalommal:
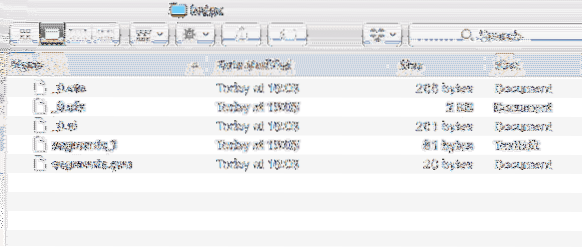
Index adatok
A Lucene-nél további tanulságokból elemezzük, hogy az összes fájl mit hoz létre ebben az Indexben.
Következtetés
Ebben a leckében megnéztük, hogyan működik az Apache Lucene, és készítettünk egy egyszerű példaalkalmazást is, amely Mavenre és java-ra épült.


