Ez az előző cikk folytatása. Foglalkozunk a lekérdezés finomításával, összetettebb keresési feltételek megfogalmazásával, különböző paraméterekkel, valamint az Apache Solr lekérdező oldal különböző webes űrlapjainak megértésével. Ezenkívül megvitatjuk a keresési eredmények utólagos feldolgozását különböző kimeneti formátumok, például XML, CSV és JSON használatával.
Az Apache Solr lekérdezése
Az Apache Solr webalkalmazásként és szolgáltatásként működik, amely a háttérben fut. Ennek eredményeként bármely ügyfélalkalmazás kommunikálhat a Solrral, lekérdezések küldésével (a cikk középpontjában), a dokumentummag manipulálásával indexelt adatok hozzáadásával, frissítésével és törlésével, valamint az alapadatok optimalizálásával. Két lehetőség van - irányítópulton / webes felületen keresztül, vagy egy API használatával a megfelelő kérés elküldésével.
Gyakori a első lehetőség tesztelés céljából és nem rendszeres hozzáférés céljából. Az alábbi ábra az Apache Solr Administration felhasználói felület irányítópultját mutatja a Firefox böngésző különböző lekérdezési űrlapjaival.
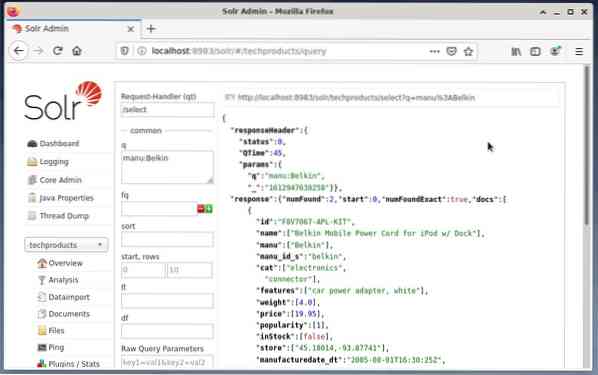
Először válassza a fő választó mező alatti menüből a „Query” menüpontot. Ezután az irányítópult több beviteli mezőt jelenít meg az alábbiak szerint:
- Kérelemkezelő (qt):
Határozza meg, hogy milyen kérést szeretne küldeni a Solr-nak. Választhat az alapértelmezett kérelemkezelők között: „/ select” (lekérdezés indexelt adatok), „/ update” (indexelt adatok frissítése) és „/ delete” (a megadott indexelt adatok eltávolítása), vagy saját maga. - Lekérdezés esemény (q):
Határozza meg a kiválasztandó mezőneveket és értékeket. - Szűrő lekérdezések (fq):
Korlátozza a visszaküldhető dokumentumok felső részét anélkül, hogy befolyásolná a dokumentum pontszámát. - Rendezési sorrend (rendezés):
Határozza meg a lekérdezés eredményeinek növekvő vagy csökkenő rendezési sorrendjét - Kimeneti ablak (kezdet és sorok):
Korlátozza a kimenetet a megadott elemekre - Mezőlista (fl):
A lekérdezés válaszában szereplő információkat egy meghatározott mezőlistára korlátozza. - Kimeneti formátum (tömeg):
Adja meg a kívánt kimeneti formátumot. Az alapértelmezett érték JSON.
A Lekérdezés végrehajtása gombra kattintva futtatja a kívánt kérést. Gyakorlati példákért tekintse meg alább.
Mivel a második lehetőség, kérelmet küldhet egy API segítségével. Ez egy HTTP kérés, amelyet bármely alkalmazás elküldhet az Apache Solr számára. A Solr feldolgozza a kérést, és visszaadja a választ. Ennek egy speciális esete a Java API-n keresztül történő kapcsolódás az Apache Solr-hoz. Ezt kiszervezték egy külön projektnek, a SolrJ [7] nevű Java API-nak, HTTP-kapcsolat nélkül.
Lekérdezés szintaxisa
A lekérdezés szintaxisa a [3] és [5] pontokban található. A különböző paraméternevek közvetlenül megfelelnek a fent ismertetett űrlapok beviteli mezőinek nevével. Az alábbi táblázat felsorolja őket, valamint gyakorlati példákat.
Lekérdezési paraméterek indexe
| Paraméter | Leírás | Példa |
|---|---|---|
| q | Az Apache Solr fő lekérdezési paramétere - a mezők neve és értéke. A hasonlósági pontszámok dokumentálják az ebben a paraméterben szereplő kifejezéseket. | Id: 5 autók: * adilla * *: X5 |
| fq | Szűkítse az eredménykészletet a szűrőnek megfelelő superset dokumentumokra, például a Function Range Query Parser segítségével | modell id, modell |
| Rajt | Az oldal eredményeinek eltolódásai (kezdet). Ennek a paraméternek az alapértelmezett értéke 0. | 5 |
| sorok | Az oldal eredményeinek eltolódásai (vége). Ennek a paraméternek az értéke alapértelmezés szerint 10 | 15 |
| fajta | Megadja a vesszőkkel elválasztott mezők listáját, amelyek alapján a lekérdezés eredményeit rendezni kell | modell asc |
| fl | Megadja az eredményhalmaz összes dokumentumához visszatérítendő mezők listáját | modell id, modell |
| wt | Ez a paraméter a válaszíró típusát jelöli, amelynek eredményét meg akartuk tekinteni. Ennek értéke alapértelmezés szerint JSON. | json xml |
A kereséseket HTTP GET kéréssel hajtják végre, a q paraméterben található lekérdezési karakterlánccal. Az alábbi példák tisztázzák ennek működését. A curl használatával a lekérdezést el lehet küldeni a helyileg telepített Solr-nak.
- Az összes adatkészlet lekérése az alapkocsik göndörítéséből: http: // localhost: 8983 / solr / cars / query?q = *: *
- Az összes adatkészlet lekérése az 5 curl azonosítójú alapkocsikról http: // localhost: 8983 / solr / cars / query?q = id: 5
- Szerezze be a terepi modellt az alapkocsik összes adatkészletéből
1. lehetőség (megszabadult &): göndörítés http: // localhost: 8983 / solr / cars / query?q = id: * \ & fl = modell2. lehetőség (lekérdezés egyetlen kullancsban):
curl 'http: // localhost: 8983 / solr / cars / query?q = id: * & fl = modell ' - Olvassa el az alapkocsik összes adatkészletét ár szerint rendezve csökkenő sorrendben, és adja ki a csak a márkát, modellt és árat tartalmazó mezőket (verzió egyetlen pipában): curl http: // localhost: 8983 / solr / cars / query -d '
q = *: * &
sort = ár leírás &
fl = gyártmány, modell, ár ” - Keresse meg az alapkocsik első öt adatkészletét ár szerint csökkenő sorrendben, és adja meg a márkát, a modellt és az árat (csak egy kullancsban): curl http: // localhost: 8983 / solr / cars / query - d '
q = *: * &
sorok = 5 &
sort = ár leírás &
fl = gyártmány, modell, ár ” - Keresse meg az alapkocsik első öt adatkészletét ár szerint csökkenő sorrendben, és adja meg a márkát, modellt és árat, valamint a relevancia pontszámot (verzió egyetlen kullancsban): curl http: // localhost: 8983 / solr / autók / lekérdezés -d '
q = *: * &
sorok = 5 &
sort = ár leírás &
fl = márka, modell, ár, pontszám ” - Visszaadja az összes tárolt mezőt, valamint a relevancia pontszámot: curl http: // localhost: 8983 / solr / cars / query -d '
q = *: * &
fl = *, pontszám '
Ezenkívül meghatározhatja saját kéréskezelőjét, hogy az opcionális kérési paramétereket elküldje a lekérdező elemzőnek annak érdekében, hogy ellenőrizze, milyen információkat küld vissza.
Lekérdező elemzők
Az Apache Solr úgynevezett lekérdezési elemzőt használ - egy olyan összetevőt, amely a keresési karakterláncot a keresőmotorhoz adott utasításokká alakítja át. A lekérdezés elemzője áll Ön és a keresett dokumentum között.
A Solr különféle elemző típusokkal rendelkezik, amelyek eltérnek a beküldött lekérdezés kezelésétől. A Standard Query Parser jól működik strukturált lekérdezéseknél, de kevésbé toleráns a szintaktikai hibákkal szemben. Ugyanakkor a DisMax és az Extended DisMax Query Parser is optimalized for natural language-like queries. Úgy tervezték, hogy feldolgozzák a felhasználók által bevitt egyszerű kifejezéseket, és különféle súlyozással keressenek egyedi kifejezéseket több mezőben.
Ezenkívül a Solr úgynevezett függvény lekérdezéseket is kínál, amelyek lehetővé teszik egy függvény lekérdezéssel történő kombinálását egy adott relevancia pontszám előállítása érdekében. Ezeket a elemzőket Function Query Parser és Function Range Query Parser neveknek nevezik. Az alábbi példa azt mutatja, hogy ez utóbbi választja ki a „bmw” összes adatsort (az adatmezőben tárolva) a 318 és 323 közötti modellekkel:
göndörítés http: // localhost: 8983 / solr / cars / query -d 'q = gyártmány: bmw &
fq = modell: [318 - 323] "
Az eredmények utófeldolgozása
Az egyik rész a lekérdezések küldése az Apache Solr-nak, de a keresési eredmények utólagos feldolgozása a másiktól. Először választhat a különböző válaszformátumok között - a JSON-tól az XML-ig, a CSV-ig és az egyszerűsített Ruby-formátumig. Egyszerűen adja meg a lekérdezésben a megfelelő wt paramétert. Az alábbi kódpélda ezt szemlélteti az adatkészlet CSV-formátumban történő lekéréséhez az összes elemhez curl-t használva a megszabadult &:
göndörítés http: // localhost: 8983 / solr / cars / query?q = id: 5 \ & wt = csvA kimenet vesszővel elválasztott lista az alábbiak szerint:

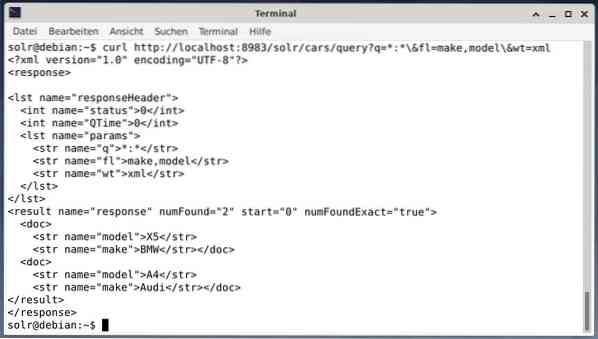
Az eredmény XML adatként történő megkapása, de csak a két kimeneti mező készítése és modellezése, futtassa a következő lekérdezést:
göndörítés http: // localhost: 8983 / solr / cars / query?q = *: * \ & fl = gyártmány, modell \ & wt = xmlA kimenet különbözik, és tartalmazza a válasz fejlécét és a tényleges választ is:
A Wget egyszerűen kinyomtatja a beérkezett adatokat az stdout-ra. Ez lehetővé teszi, hogy a parancsot standard parancssori eszközökkel utólag feldolgozza. Néhányat felsorolva, ez tartalmazza a JSON-hoz tartozó jq [9] -et, XML-hez az xsltproc, xidel, xmlstarlet [10], valamint a CSV-formátumhoz tartozó csvkit [11] -et.
Következtetés
Ez a cikk bemutatja a lekérdezések küldésének különböző módjait az Apache Solr számára, és elmagyarázza, hogyan kell feldolgozni a keresési eredményt. A következő részben megtudhatja, hogyan kell az Apache Solr segítségével keresni a PostgreSQL-ben, egy relációs adatbázis-kezelő rendszerben.
A szerzőkről
Jacqui Kabeta környezetvédő, lelkes kutató, oktató és mentor. Több afrikai országban dolgozott az informatikai iparban és a civil szervezetek környezetében.
Frank Hofmann informatikai fejlesztő, oktató és szerző, és inkább Berlinből, Genfből és Fokvárosból dolgozik. A Debian Csomagkezelő Könyv társszerzője a dpmb oldalon érhető el.org
Linkek és hivatkozások
- [1] Apache Solr, https: // lucén.apache.org / solr /
- [2] Frank Hofmann és Jacqui Kabeta: Bevezetés az Apache Solr-ba. 1. rész, http: // linuxhint.com
- [3] Yonik Seelay: Solr Query Syntax, http: // yonik.com / solr / query-syntax /
- [4] Yonik Seelay: Solr bemutató, http: // yonik.com / solr-tutorial /
- [5] Apache Solr: Adatok lekérdezése, Tutorialspoint, https: // www.tutorialspoint.com / apache_solr / apache_solr_querying_data.htm
- [6] Lucene, https: // lucén.apache.org /
- [7] SolrJ, https: // lucén.apache.org / solr / guide / 8_8 / using-solrj.html
- [8] göndör, https: // göndör.se /
- [9] jq, https: // github.com / stedolan / jq
- [10] xmlstarlet, http: // xmlstar.sourceforge.háló/
- [11] csvkit, https: // csvkit.readthedocs.io / hu / latest /


