Ebben a cikkben áttekintjük a csoport funkciók szerinti alaphasználatait a panda pythonjában. Az összes parancsot a Pycharm szerkesztőjén hajtják végre.
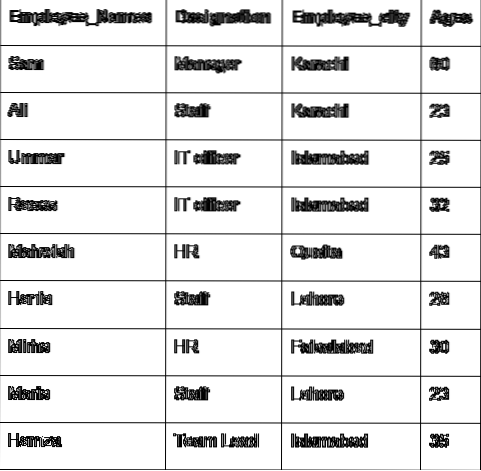
Beszéljük meg a csoport fő koncepcióját a munkavállalói adatok segítségével. Hoztunk létre egy adatkeretet néhány hasznos alkalmazotti adattal (Employee_Names, Megnevezés, Employee_city, Age).
Karakterlánc-összefűzés a funkció szerinti csoportosítással
A groupby függvény segítségével összefűzheti a karakterláncokat. Ugyanazok a rekordok egyetlen cellában összekapcsolhatók a ',' jellel.
Példa
A következő példában az alkalmazottak kijelölése oszlop alapján rendeztük az adatokat, és csatlakoztunk az azonos megnevezésű alkalmazottakhoz. A lambda függvényt alkalmazzák az 'Employees_Name'.
import pandák, mint pddf = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
„Megnevezés”: [„Vezető”, „Személyzet”, „Informatikai tiszt”, „Informatikai tiszt”, „HR”, „Személyzet”, „HR”, „Személyzet”, „Csapatvezető”],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
„Employee_gege”: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
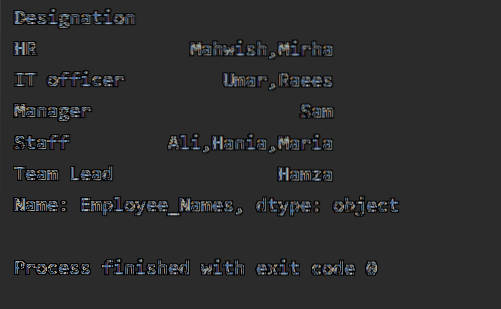
df1 = df.groupby ("Megnevezés") ['Employee_Names'].alkalmazni (lambda Employee_Names: ','.csatlakozás (Employee_Names))
nyomtatás (df1)
A fenti kód végrehajtásakor a következő kimenet jelenik meg:
Az értékek rendezése növekvő sorrendben
Használja a groupby objektumot egy szokásos adatkeretbe a ".to_frame () ', majd az újraindexeléshez használja a reset_index () elemet. Oszlopértékek rendezése a sort_values () meghívásával.
Példa
Ebben a példában az alkalmazott korát növekvő sorrendben rendezzük. A következő kóddarab használatával növekvő sorrendben megkaptuk az 'Employee_Age' szót az 'Employee_Names' néven.
import pandák, mint pddf = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
„Megnevezés”: [„Vezető”, „Személyzet”, „Informatikai tiszt”, „Informatikai tiszt”, „HR”, „Személyzet”, „HR”, „Személyzet”, „Csapatvezető”],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
„Employee_gege”: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
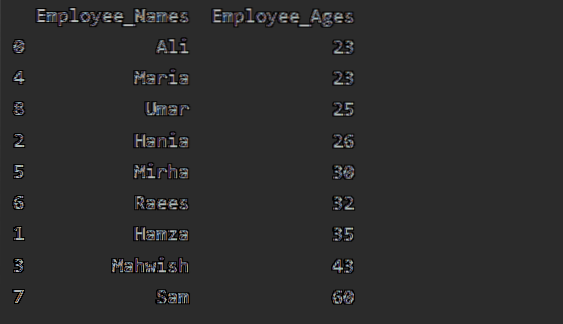
df1 = df.groupby ('Employee_Names') ['Employee_Age'].összeg().bekeretezni().reset_index ().sort_values (by = 'Employee_Age')
nyomtatás (df1)
Aggregátumok használata groupby-val
Számos olyan funkció vagy összesítés áll rendelkezésre, amelyeket alkalmazhat az adatcsoportokra, például a count (), sum (), átlag (), medián (), mode (), std (), min (), max ().
Példa
Ebben a példában a 'count ()' függvényt alkalmaztuk a groupby-val az azonos „Employee_city” -be tartozó alkalmazottak számolásához.
import pandák, mint pddf = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
„Megnevezés”: [„Vezető”, „Személyzet”, „Informatikai tiszt”, „Informatikai tiszt”, „HR”, „Személyzet”, „HR”, „Személyzet”, „Csapatvezető”],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
„Employee_gege”: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
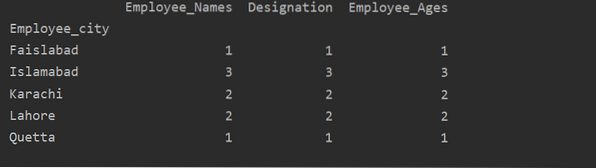
df1 = df.groupby ('Employee_city').számol()
nyomtatás (df1)
Amint a következő kimenetet láthatja, a Megnevezés, az Alkalmazott_nevek és az Alkalmazott_Az oszlopok alatt számolja meg az azonos városhoz tartozó számokat:
Az adatok vizualizálása a groupby használatával
Az 'import matplotlib.pyplot ', az adatokat grafikonokká vizualizálhatja.
Példa
A következő példa itt a groupby utasítás használatával vizualizálja az 'Employee_Age' értéket az 'Employee_Nmaes' kifejezéssel az adott DataFrame-ből.
import pandák, mint pdimport matplotlib.pyplot mint plt
adatkeret = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
„Megnevezés”: [„Vezető”, „Személyzet”, „Informatikai tiszt”, „Informatikai tiszt”, „HR”, „Személyzet”, „HR”, „Személyzet”, „Csapatvezető”],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
„Employee_gege”: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
plt.clf ()
adatkeret.groupby ('Employee_Names').összeg().telek (fajta = 'bar')
plt.előadás()
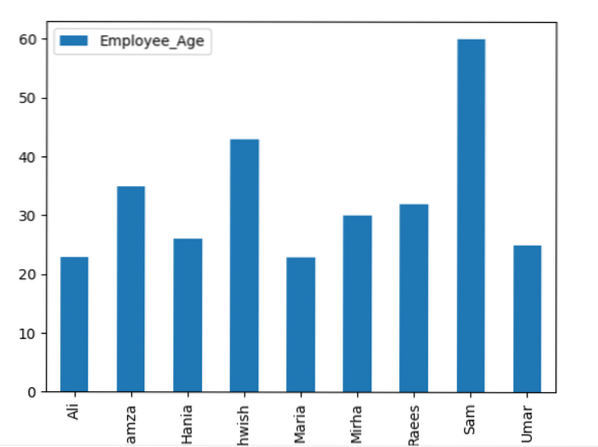
Példa
Ha a halmozott gráfot a groupby segítségével szeretné ábrázolni, fordítsa el a 'stacked = true' elemet, és használja a következő kódot:
import pandák, mint pdimport matplotlib.pyplot mint plt
df = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
„Megnevezés”: [„Vezető”, „Személyzet”, „Informatikai tiszt”, „Informatikai tiszt”, „HR”, „Személyzet”, „HR”, „Személyzet”, „Csapatvezető”],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
„Employee_gege”: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df.groupby (['Employee_city', 'Employee_Names']).méret().halmozás ().plot (kind = 'bar', stacked = True, fontsize = '6')
plt.előadás()
Az alább megadott grafikonon a lerakott alkalmazottak száma, akik ugyanahhoz a városhoz tartoznak.
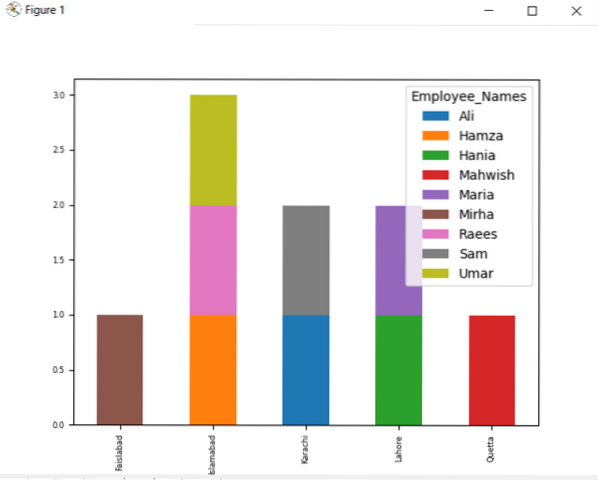
Változtassa meg az oszlop nevét a csoporttal
Az összesített oszlop nevét néhány új módosított névvel is módosíthatja az alábbiak szerint:
import pandák, mint pdimport matplotlib.pyplot mint plt
df = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
„Megnevezés”: [„Vezető”, „Személyzet”, „Informatikai tiszt”, „Informatikai tiszt”, „HR”, „Személyzet”, „HR”, „Személyzet”, „Csapatvezető”],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
„Employee_gege”: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Employee_Names') ['Megnevezés'].összeg().reset_index (név = 'Alkalmazott_megjelölés')
nyomtatás (df1)
A fenti példában a "Megnevezés" név "Employee_Designation" -re változik.
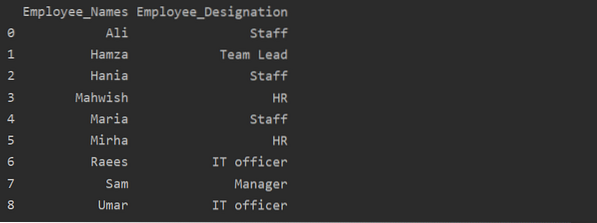
Csoport beolvasása kulcs vagy érték szerint
A groupby utasítás használatával hasonló rekordokat vagy értékeket kaphat az adatkeretről.
Példa
Az alábbi példában a „Megnevezés” alapján csoportos adatokkal rendelkezünk. Ezután a 'Staff' csoportot a .getgroup ('Személyzet').
import pandák, mint pdimport matplotlib.pyplot mint plt
df = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
„Megnevezés”: [„Menedzser”, „Munkatárs”, „Informatikai tiszt”, „Informatikai tiszt”, „HR”, „Munkatárs”, „HR”, „Munkatárs”, „Csapatvezető”],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
„Employee_gege”: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
kivonat_érték = df.groupby („Megnevezés”)
print (kivonat_érték.get_group ('Személyzet'))
A következő eredmény jelenik meg a kimeneti ablakban:

Érték hozzáadása a csoportlistához
Hasonló adatok a groupby utasítás használatával listában is megjeleníthetők. Először csoportosítsa az adatokat egy feltétel alapján. Ezután a függvény alkalmazásával könnyedén felveheti ezt a csoportot a listákba.
Példa
Ebben a példában hasonló rekordokat illesztettünk be a csoportlistába. Az összes alkalmazottat az „Employee_city” alapján csoportokba osztják, majd a „Lambda” függvény alkalmazásával ezt a csoportot lista formájában kapják meg.
import pandák, mint pddf = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
„Megnevezés”: [„Menedzser”, „Munkatárs”, „Informatikai tiszt”, „Informatikai tiszt”, „HR”, „Munkatárs”, „HR”, „Munkatárs”, „Csapatvezető”],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
„Employee_gege”: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Employee_city') ['Employee_Names'].alkalmazni (lambda group_series: group_series.tolist ()).reset_index ()
nyomtatás (df1)
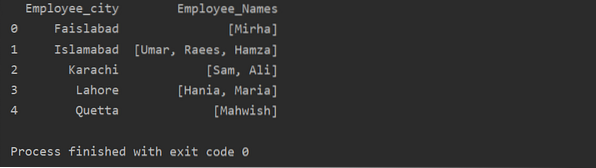
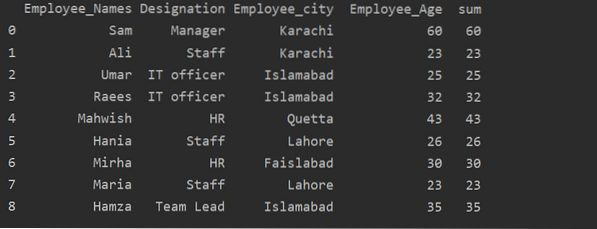
A Transform funkció használata a groupby-val
Az alkalmazottak életkoruk szerint vannak csoportosítva, ezeket az értékeket összeadva, és a 'átalakítás' funkció használatával a táblázat új oszlopot ad hozzá:
import pandák, mint pddf = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
„Megnevezés”: [„Menedzser”, „Munkatárs”, „Informatikai tiszt”, „Informatikai tiszt”, „HR”, „Munkatárs”, „HR”, „Munkatárs”, „Csapatvezető”],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
„Employee_gege”: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df ['összeg'] = df.groupby (['Employee_Names']) ['Employee_Age'].átalakítás ('összeg')
nyomtatás (df)
Következtetés
Ebben a cikkben megvizsgáltuk a groupby állítás különböző felhasználási módjait. Megmutattuk, hogyan oszthatja fel az adatokat csoportokba, és különböző összesítések vagy függvények alkalmazásával könnyedén visszakeresheti ezeket a csoportokat.


