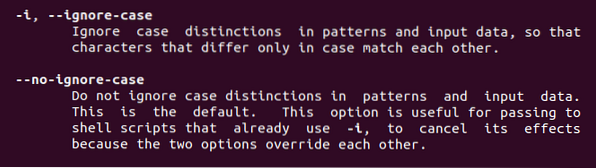
Ebből a parancsból két, a fent leírt tulajdonságot találunk. -Úgy értem, hogy figyelmen kívül hagyom az esetet, bárhol is használják ezt a kulcsszót, az eset vonzalma megszűnik.
Előfeltétel
Ahhoz, hogy a Linux operációs rendszerben teljesítsük a funkció funkcióit, telepítenünk kell egy Linux operációs rendszert. A konfigurálás után megadja a szükséges felhasználói információkat, amelyek segítségével a felhasználó be lesz jelentkezve. Továbbá, ha megadják a felhasználónevet és a jelszót, a felhasználó hozzáférhet az operációs rendszer összes beépített szolgáltatásához. Végül, miután elérte az asztalt, be kell érnie a terminált, mivel a parancsokat rajta kell futtatni.
1. példa:
Ebben a példában meglátjuk, hogy a grep hogyan segít a kis- és nagybetűk érzékenységének elkerülésében. Vegyünk egy fájl nevű fájlt11.txt. A fájl a következő adatokat tartalmazza; amint láthatja, hogy a mangó szó különféle módon van megírva, egyes szavak nagybetűvel, mások kisbetűvel vannak feltüntetve. A cat paranccsal megjelenítjük a fájl adatait.
$ cat fájlok11.txt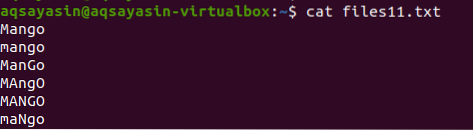
Miután a parancsot az adatok megjelenítésére használtuk, megfigyelhető, hogy az egyetlen szó jelenik meg, amely megfelel a parancsban szereplő betű eseteinek. Minden betű kisbetűvel van ellátva.
$ grep mango fájlok11.txt
Most, hogy megértsük a kis- és nagybetűk érzéketlenségének fogalmát, a „-I” karaktert fogjuk használni a parancsban a kis- és nagybetűk érzékenységének kezelésére azáltal, hogy megadjuk a fájlban található összes adatot, egyezést a parancsban található karakterlánccal.
$ grep -I mangó fájlok11.txt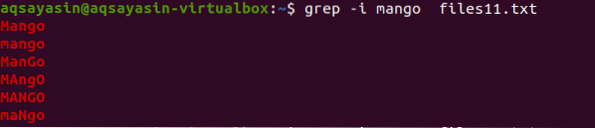
A kimenetből megtudhatja, hogy minden adat, amely megfelel a „mango” szónak, vagy nagybetűs, másrészt kisbetűs szavakkal jelenik meg.
2. példa
Ez a példa az elsőhöz hasonlít, a különbség az, hogy csak egyetlen szót kapunk. Ez a parancs segít a teljes karaktersorozat megszerzésében azáltal, hogy illeszkedik a parancsban megadott szóhoz. Legyen egy fájl fájlunk.txt. példaként az adott mérkőzésnek megfelelő rekordot szeretnénk előhozni.
$ macska filea.txt
Most alkalmazza ugyanazt a parancsot az eset figyelmen kívül hagyásához és a kimenet ábrázolásához. A szakszó úgy jelenik meg, hogy kizárja a kis- és nagybetűket.

3. példa
A grep használatának másik módja az eset figyelmen kívül hagyására az, hogy először egy fájlnevet vezet be, majd később az -I parancsot a grep segítségével alkalmazza a „|” után. operátor. A macskát a „|” jellel együtt használják. Legyen egy file24 nevű fájl.txt. mint például.
$ Macskafájl24.txt | grep -Én „Aqsa”Ezzel a paranccsal az „Aqsa” szót beolvassa nagy- és kisbetűkben egyaránt.

4. példa
Haladunk egy másik példa felé. Itt jelenítjük meg a „my” szót tartalmazó fájl adatait. Itt a keresés könyvtár bevezetésével történik, így a parancs rendezi a szót minden kiterjesztésű fájlban .txt a rendszerben.
$ grep -I my / home / aqsayasin / *.txt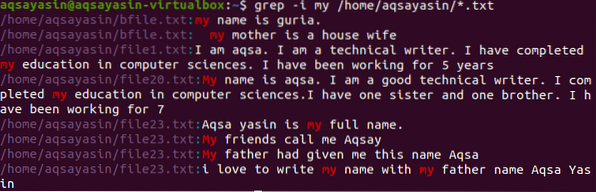
A fenti kép a parancs által kapott kimenetet mutatja. A „szavam” kiemelt, vagyis mindkét esetben. Egyes fájlok kis betűkkel tartalmazzák, míg mások nagybetűvel. A fájlok címe és fájlnevei is megjelennek.
5. példa
Ez a példa arra a könyvtárra alkalmazható, amelyben az összes fájl szerepel. Korlátozások kerülnek alkalmazásra annak a konkrét eredménynek a megjelenítéséhez, amely megfelelt a parancsban definiált szóval. Az „is” szó a rendszerben található összes fájl keresésére szolgál.
$ grep -I / home / aqsayasin / file *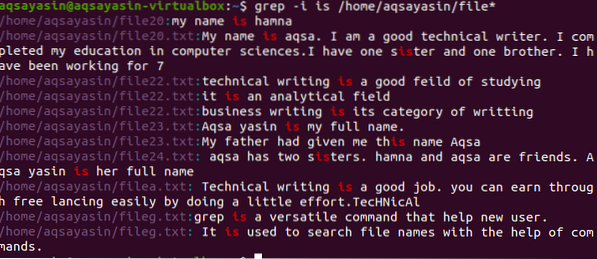
A kimenet egész karakterláncokat tartalmaz, amelyek tartalmazzák az egyező szót. A „van” külön van megírva, vagy egy másik szóban kombinálva van.e. nővér.
6. példa
A következő parancs megmutatja, hogy az -iw hogyan működik együtt a parancsban. Ezen kívül a keresés két szóval történik egyetlen fájlban. A visszavágás és a "|" a fájl két szavának leírására szolgálnak, míg a -w a fájlban található szó pontos egyezésére szolgál.
$ grep -iw 'hamna \ | house' fájl21.txt$ grep 'hamn \ | house' fájl21.txt

-Nem veszem figyelembe a kis- és nagybetűk érzékenységét. A fenti példában láthatjuk, hogy -w jelenléte -I-vel lehetővé teszi, hogy az első parancsban szereplő házat ne vegyük figyelembe, mert a -w lehetővé teszi a pontos egyezést. A második parancsban eltávolítottuk mindkét -iw elemet, ezért mindkét szó megjelenik a karakterláncban való egyezés után.
7. példa
Egynél több szó keresése más módszer alkalmazásával történik. Mindkét szót ugyanabból a fájlból keresik, ezek a szavak „munka” és „kereset”. A kereset a tanulás szóból származik, és vegye figyelembe, hogy minden szó el van választva az -e kulcsszótól.
$ grep -Én -e állás -e keresek filea-t.txt
A fenti kép az egész karakterláncot mutatja egy bekezdésben a parancsban szereplő szavakra vonatkozóan. A fenti példákhoz hasonlóan -hagytam figyelmen kívül a munka és kereset szavak esetleges megkülönböztetését.
8. példa
Ebben a példában két szó keresése a fájl összes fájljában .txt kiterjesztés. Ezt a két szót -e választja el, mivel -e a két út elválasztásának helyes módja. A kapott kimenet mindkét szót megjeleníti a szövegkiterjesztés összes fájljában. A fájl teljes címét megkapja és megjeleníti. -Nem veszem figyelembe a kis- és nagybetűk érzékenységét, és mindkét fájlban jelen leszek mindkét szó.
$ grep -I -e állás -e keresek / home / aqsayasin / *.txt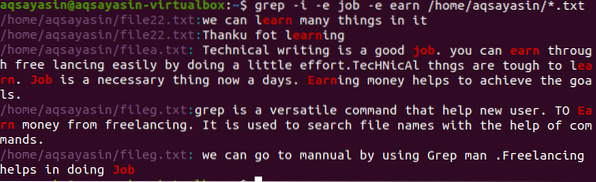
Következtetés
Ebben az útmutatóban a legegyszerűbb példát alkalmaztuk az esetérzékenység fogalmának részletezésére. Megpróbáltunk minden szempontot átnézni a grep-kel kapcsolatos ismeretek bővítése érdekében.


