A TensorFlow óriási felhasználást talált a gépi tanulás területén, pontosan azért, mert a gépi tanulás sok számgörgetést tartalmaz, és általános problémamegoldási technikaként használják. És bár a Python használatával fogunk kölcsönhatásba lépni vele, más nyelvek, például a Go, a Node kezelőfelületei vannak.js és még C #.
A Tensorflow olyan, mint egy fekete doboz, amely elrejti az összes matematikai finomságot, és a fejlesztő csak a megfelelő funkciókat hívja meg egy probléma megoldására. De milyen probléma?
Gépi tanulás (ML)
Tegyük fel, hogy botot tervez sakkozni. A sakk kialakításának, a figurák mozgásának és a játék pontosan meghatározott céljának köszönhetően teljesen olyan programot lehet írni, amely rendkívül jól játszaná a játékot. Valójában az egész emberi fajt felülmúlja sakkban. Pontosan tudná, hogy milyen mozdulatot kell végrehajtania, ha figyelembe vesszük a tábla összes darabjának állapotát.
Egy ilyen program azonban csak sakkozni tud. A játék szabályai belekerülnek a kód logikájába, és a program csak annyit tesz, hogy ezt a logikát szigorúan és pontosabban végrehajtja, mint bármelyik ember képes lenne. Ez nem általános célú algoritmus, amellyel bármilyen játékbotot megtervezhet.
A gépi tanulással a paradigma változik, és az algoritmusok egyre általánosabbá válnak.
Az ötlet egyszerű, egy osztályozási probléma meghatározásával indul. Például automatizálni szeretné a pókfajok azonosításának folyamatát. Az Ön által ismert fajok a különféle osztályok (nem tévesztendõ össze a taxonómiai osztályokkal), és az algoritmus célja egy új ismeretlen kép rendezése ezen osztályok egyikébe.
Itt az ember számára az első lépés a különféle pókok tulajdonságainak meghatározása lenne. Adatot szolgáltatnánk az egyes pókok hosszáról, szélességéről, testtömegéről és színéről, valamint a fajokról, amelyekhez tartoznak:
| Hossz | Szélesség | Tömeg | Szín | Struktúra | Faj |
| 5 | 3 | 12 | Barna | sima | Apa hosszú lábak |
| 10 | 8 | 28 | Barna fekete | szőrös | Tarantellapók |
Ilyen egyedi pókadatok nagy gyűjteményével az algoritmust „betaníthatjuk”, és egy másik hasonló adatkészletet használunk az algoritmus tesztelésére, hogy lássuk, mennyire jó az új információkkal, amelyekkel még soha nem találkozott, de amelyekről már ismerjük a válasz neki.
Az algoritmus randomizált módon indul el. Vagyis minden pókot, annak tulajdonságaitól függetlenül, a faj bármelyikébe sorolhatnánk. Ha 10 különböző faj van az adatkészletünkben, akkor ennek a naiv algoritmusnak a puszta szerencse miatt az idő kb.
De akkor a gépi tanulás aspektusa kezdené eluralkodni. Kezdené egyes tulajdonságokat társítani bizonyos eredményekhez. Például a szőrös pókok valószínűleg tarantulák, és a nagyobb pókok is. Tehát valahányszor megjelenik egy új, nagy és szőrös pók, nagyobb valószínűséggel lesz tarantula. Figyelem, továbbra is valószínűséggel dolgozunk, ez azért van, mert eredendően valószínűségi algoritmussal dolgozunk.
A tanulási rész a valószínűségek megváltoztatásával működik. Kezdetben az algoritmus úgy kezdődik, hogy véletlenszerűen hozzárendel egy „faj” címkét az egyénekhez, véletlenszerű összefüggéseket hozva létre, például „szőrös” és „apa hosszú lábú”. Amikor ilyen összefüggést mutat, és úgy tűnik, hogy a képzési adatkészlet nem ért egyet vele, ez a feltételezés elvetésre kerül.
Hasonlóképpen, ha egy összefüggés több példán keresztül is jól működik, akkor ez minden egyes alkalommal erősödik. Ez a módszer az igazság elé botlásnak rendkívül hatékony, köszönhetően a sok matematikai finomságnak, amelyek kezdőként nem akarnak aggódni.
TensorFlow és saját Flower osztályozójának képzése
A TensorFlow még tovább viszi a gépi tanulás gondolatát. A fenti példában Ön határozta meg azokat a jellemzőket, amelyek megkülönböztetik az egyik pókfajt a másiktól. Szorgalmasan kellett mérnünk az egyes pókokat, és több száz ilyen rekordot kellett létrehoznunk.
De jobban járhatunk, ha csak nyers képadatokat adunk az algoritmushoz, hagyhatjuk, hogy az algoritmus mintákat találjon és megértjen a kép különböző dolgait, például felismerje a képen lévő alakzatokat, majd megértse, mi a különböző felületek textúrája, színe , így tovább és így tovább. Ez a számítógépes látás kezdeti fogalma, és más típusú bemenetekhez is használhatja, például audiojelekhez és a hangfelismerés algoritmusának betanításához. Mindez a „mély tanulás” alatt található, ahol a gépi tanulás annak logikai végletébe kerül.
Ez az általánosított fogalomkészlet aztán specializálódhat, amikor sok virágképpel foglalkozik és kategorizálja őket.
Az alábbi példában Python2-t fogunk használni.7 kezelőfelület a TensorFlow interfészhez, és a pip (nem a pip3) használatával telepítjük a TensorFlow szoftvert. A Python 3 támogatás még mindig kissé hibás.
Saját képosztályozó készítéséhez először a TensorFlow használatával telepítsük csipog:
$ pip install tensorflowEzután klónoznunk kell a tensorflow-for-poet-2 git adattár. Ez két szempontból nagyon jó kiindulópont:
- Egyszerű és könnyen használható
- Ez bizonyos fokig előre kiképzett. Például a virágosztályozó már képzett annak megértésére, hogy milyen textúrát néz és milyen formákat néz, így számítási szempontból kevésbé intenzív.
Szerezzük meg a tárat:
$ git klón https: // github.com / googlecodelabs / tensorflow-for-poet-2$ cd tensorflow-for-poet-2
Ez a munkakönyvtárunk lesz, ezért az összes parancsot innentől kezdve belül kell kiadni.
Továbbra is ki kell képeznünk a virágok felismerésének speciális problémájára vonatkozó algoritmust, ehhez képzési adatokra van szükségünk, tehát vegyük ezt:
$ curl http: // letöltés.tensorflow.org / example_images / flower_photos.tgz| tar xz -C tf_files
A könyvtár… ./tensorflow-for-poet-2 / tf_files rengeteg ilyen képet tartalmaz, megfelelően címkézve és felhasználásra készen. A képek két különböző célra szolgálnak:
- Az ML program képzése
- Az ML program tesztelése
Ellenőrizheti a mappa tartalmát tf_files és itt azt fogja tapasztalni, hogy csak a virágok 5 kategóriájára szűkítünk, nevezetesen százszorszépek, tulipánok, napraforgók, pitypangok és rózsák.
A modell kiképzése
A képzési folyamatot úgy állíthatja be, hogy először a következő állandókat állítja be az összes bemeneti kép átméretezéséhez, és könnyű mobilenet architektúrát használ:
$ IMAGE_SIZE = 224$ ARCHITECTURE = "mobilenet_0.50 _ $ IMAGE_SIZE "
Ezután hívja meg a python parancsfájlt a parancs futtatásával:
$ python -m szkriptek.átképzés \--szűk keresztmetszet = tf_fájlok / szűk keresztmetszetek \
--how_many_training_steps = 500 \
--model_dir = tf_files / models / \
--summaries_dir = tf_files / training_summaries / "$ ARCHITECTURE" \
--output_graph = tf_files / átképzett_graph.pb \
--output_labels = tf_files / átképzett_címkék.txt \
--architektúra = "$ ARCHITECTURE" \
--image_dir = tf_files / flower_photos
Bár sok lehetőség van itt megadva, a legtöbb megadja a bemeneti adatkönyvtárakat és az iteráció számát, valamint azokat a kimeneti fájlokat, ahol az új modell információit tárolják. Ennek közepes laptopon történő futtatása nem lehet hosszabb 20 percnél.
Miután a szkript befejezte mind a képzést, mind a tesztelést, kap egy pontos becslést a képzett modellről, amely esetünkben valamivel magasabb volt, mint 90%.
A betanított modell használata
Most már készen áll arra, hogy ezt a modellt felhasználja a virág minden új képének felismerésére. Ezt a képet fogjuk használni:

A napraforgó arca alig látható, és ez nagy kihívás a modellünk számára:
Ahhoz, hogy ezt a képet a Wikimedia commons-ból szerezze be, használja a wget-et:
$ wget https: // feltöltés.wikimedia.org / wikipedia / commons / 2/28 / Napraforgó_fej_2011_G1.jpg$ mv Napraforgó_fej_2011_G1.jpg tf_files / ismeretlen.jpg
Mentve van ismeretlen.jpg alatt tf_files alkönyvtár.
Most, az igazság pillanatában meglátjuk, mi a véleményünk erről a képről.Ehhez meghívjuk a label_image forgatókönyv:
$ python -m szkriptek.label_image --graph = tf_files / átképzett_graph.pb --image = tf_files / ismeretlen.jpg
Ehhez hasonló kimenetet kapna:
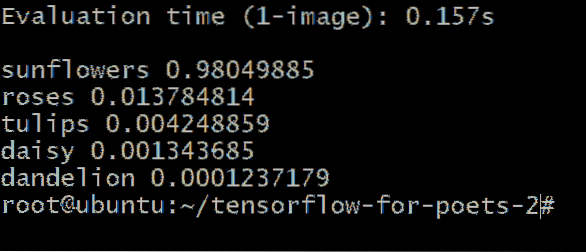
A virágtípus melletti számok annak a valószínűségét jelentik, hogy ismeretlen képünk ebbe a kategóriába tartozik. Például 98.04% biztos abban, hogy a kép napraforgó, és csak 1.37% esély arra, hogy rózsa legyen.
Következtetés
Még a közepes számítási erőforrások mellett is elképesztő pontosságot tapasztalunk a képek azonosításában. Ez egyértelműen bizonyítja a TensorFlow erejét és rugalmasságát.
Innentől kezdve kísérletezhet különféle más bemenetekkel, vagy megpróbálhatja megírni a saját alkalmazását a Python és a TensorFlow segítségével. Ha egy kicsit jobban meg akarja ismerni a gépi tanulás belső működését, itt interaktív módon teheti meg ezt.


