Felhívjuk figyelmét, hogy ez nem bevezető lecke. Kérjük, olvassa el a Mi az Apache Kafka és hogyan működik, mielőtt folytatná ezt a leckét, hogy mélyebb betekintést nyerjen.
Témák Kafkában
A Kafka témája olyan, amikor üzenetet küldenek. A téma iránt érdeklődő fogyasztói alkalmazások behúzzák az üzenetet a témába, és bármit megtehetnek az adatokkal. Egy adott időtartamig tetszőleges számú fogyasztói alkalmazás képes ezt az üzenetet akárhányszor megjeleníteni.
Vegyünk egy olyan témát, mint a LinuxHint Ubuntu Blog oldala. Az órákat örökkévalóvá teszik, és tetszőleges számú rajongó olvasó eljöhet és akárhányszor elolvashatja ezeket a leckéket, vagy áttérhet a következő órára. Ezeket az olvasókat a LinuxHint más témái is érdekelhetik.
Téma particionálása
A Kafka-t nehéz alkalmazások kezelésére tervezték, és nagy számú üzenetet állítottak sorba, amelyeket egy téma tartalmaz. A magas hibatűrés biztosítása érdekében az egyes témákat több témapartícióra osztják, és minden témacsoportot külön csomóponton kezelnek. Ha az egyik csomópont lemegy, akkor egy másik csomópont működhet témavezetőként, és kiszolgálhatja a témákat az érdeklődő fogyasztók számára. Így írjuk ugyanazokat az adatokat több topikpartícióra: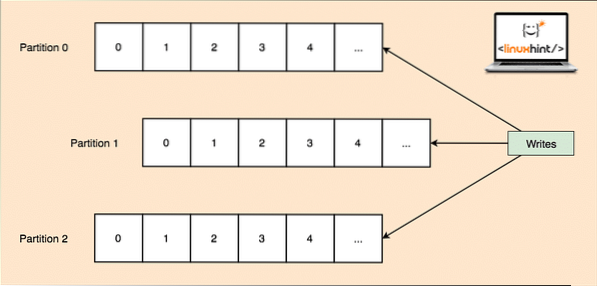
Témapartíciók
Most a fenti kép azt mutatja, hogy ugyanazok az adatok hogyan replikálódnak több partíción. Vizsgáljuk meg, hogy a különböző partíciók hogyan működhetnek vezetőként különböző csomópontokon / partíciókon:
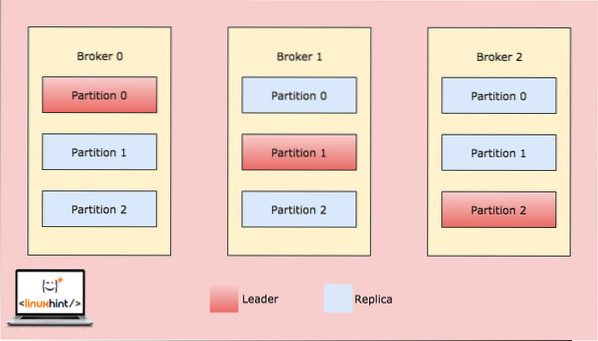
Kafka Broker particionálás
Amikor az ügyfél valamit ír egy témához egy olyan pozícióban, amelynek a Partíció a Broker 0-ban a vezetője, akkor ezeket az adatokat a közvetítők / csomópontok replikálják, így az üzenet biztonságos marad: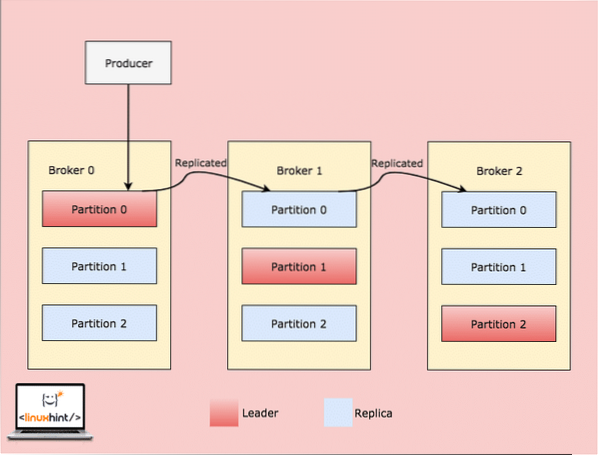
Replikáció a bróker partíciókon
Több partíció, nagyobb áteresztőképesség
Kafka használja Párhuzamosság hogy nagyon nagy áteresztőképességet biztosítson a termelői és fogyasztói alkalmazások számára. Valójában ugyanígy megtartja azt a helyzetét is, hogy erősen hibatűrő rendszer. Értsük meg, hogy a párhuzamosság milyen nagy teljesítményt ér el.
Amikor egy Producer alkalmazás ír egy üzenetet egy partícióra a 0-as brókerben, Kafka párhuzamosan több szálat nyit meg, így az üzenet egyszerre replikálható az összes kiválasztott brókeren. A Fogyasztó oldalon a fogyasztói alkalmazás egyetlen partícióról üzeneteket fogyaszt egy szálon keresztül. Minél több a partíció, annál több fogyasztói szál nyitható meg, hogy mindegyik párhuzamosan is működhessen. Ez azt jelenti, hogy minél nagyobb a partíciók száma egy klaszterben, annál nagyobb a párhuzamosság kihasználása, ami nagyon nagy átviteli rendszert hoz létre.
Több partícióhoz több fájlkezelőre van szükség
Csak azért, mert fentebb tanulmányozta, hogyan növelhetjük a Kafka rendszer teljesítményét a partíciók számának növelésével. De vigyáznunk kell, milyen határ felé haladunk.
A Kafka minden témakör-partíciója a kiszolgálóközvetítő fájlrendszerének könyvtárához van hozzárendelve, ahol fut. A naplókönyvtárban két fájl lesz: egy az indexhez, egy másik pedig a tényleges adatokhoz naplószegmensenként. Jelenleg Kafkában minden bróker megnyit egy fájlkezelőt mind az összes naplószegmens indexéhez, mind az adatfájljához. Ez azt jelenti, hogy ha 10 000 partíció van egy brókeren, akkor ez 20 000 fájlkezelőt fog párhuzamosan futtatni. Bár ez csak a Bróker konfigurációjáról szól. Ha az a rendszer, amelyre a Brókert telepítették, magas konfigurációval rendelkezik, akkor ez aligha lesz kérdés.
Kockázat a partíciók nagy számával
Amint azt a fenti képeken láthattuk, Kafka a fürtön belüli replikációs technikát használja a vezető üzenetének másolására a más Brókerekben található Replica partíciókra. Mind a gyártói, mind a fogyasztói alkalmazások olvasnak és írnak egy partícióra, amely jelenleg a partíció vezetője. Ha egy bróker megbukik, akkor a bróker vezetője nem lesz elérhető. A vezetőről szóló metaadatokat a Zookeeper őrzi. Ezen metaadatok alapján Kafka automatikusan egy másik partícióhoz rendeli a partíció vezetését.
Amikor egy brókert tiszta paranccsal állítanak le, a Kafka-fürt vezérlő csomópontja a leállított bróker vezetőit sorozatosan mozgatja i.e. egyenként. ha azt gondoljuk, hogy az egyetlen vezető elmozdítása 5 milliszekundumba kerül, a vezetők elérhetetlensége nem fogja zavarni a fogyasztókat, mivel az elérhetetlenség nagyon rövid időre szól. De ha figyelembe vesszük, hogy a brókert tisztátalan módon megölik, és ez a bróker 5000 partíciót tartalmaz, és ezek közül 2000 volt a partíció vezetője, akkor ezeknek a partícióknak az új vezetők kijelölése 10 másodpercet vesz igénybe, ami nagyon magas, ha nagyon magas szintű igény szerinti alkalmazások.
Következtetés
Ha magas szintű gondolkodónak tekintjük, akkor egy Kafka-fürt több partíciója a rendszer nagyobb teljesítményéhez vezet. Ezt a hatékonyságot szem előtt tartva figyelembe kell venni a karbantartandó Kafka-fürt konfigurációját, az ehhez a fürthöz rendelendő memóriát, valamint azt, hogy miként kezelhetjük az elérhetőséget és a késést, ha valami nem megfelelő.
További Ubuntu alapú bejegyzések itt és még sok más az Apache kafkáról is.


