20 awk példa
Számos segédprogram létezik a Linux operációs rendszerben, amelyek szöveges adatokból vagy fájlokból keresnek és jelentést készítenek. A felhasználó az awk, a grep és a sed parancsok használatával könnyen elvégezhet sokféle keresést, cserét és jelentést generáló feladatot. Az awk nem csak parancs. Ez egy szkriptnyelv, amely mind a terminálból, mind az awk fájlból használható. Támogatja a változót, a feltételes utasítást, a tömböt, a ciklust stb. mint más szkriptnyelvek. Bármely fájl tartalmát soronként olvashatja, és a mezőket vagy oszlopokat egy elválasztó alapján különítheti el. Támogatja a rendszeres kifejezést az adott karakterlánc keresésére a szöveges tartalomban vagy fájlban, és műveleteket hajt végre, ha talál egyezést. Az oktatóanyag 20 hasznos példa felhasználásával mutatja be az awk parancs és szkript használatát.
Tartalom:
- awk printf-vel
- awk osztani a fehér helyet
- awk az elválasztó megváltoztatásához
- awk tabulátorral tagolt adatokkal
- awk csv adatokkal
- awk regex
- awk eset érzéketlen regex
- awk nf (mezők száma) változóval
- awk gensub () függvény
- awk rand () függvénnyel
- awk felhasználó által definiált függvény
- awk, ha
- awk változók
- awk tömbök
- awk hurok
- awk az első oszlop kinyomtatásához
- awk az utolsó oszlop kinyomtatásához
- awk a grep-kel
- awk a bash script fájllal
- awk sed
Az awk használata a printf-vel
printf () függvény bármely kimenet formázására szolgál a legtöbb programozási nyelven. Ez a funkció együtt használható awk parancs különféle formázott kimenetek generálásához. Az awk parancs főleg bármilyen szöveges fájlhoz használatos. Hozzon létre egy szöveges fájlt munkavállaló.txt az alább megadott tartalommal, ahol a mezőket tabulátorral kell elválasztani ('\ t').
munkavállaló.txt
1001 John sena 400001002 Jafar Iqbal 60000
1003 Meher Nigar 30000
1004 Jonny Liver 70000
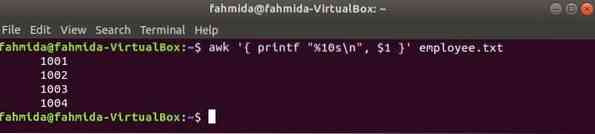
A következő awk parancs olvassa le az adatokat munkavállaló.txt fájlt soronként, és a formázás után nyomtassa ki az első fájlt. Itt, "% 10s \ n”Azt jelenti, hogy a kimenet 10 karakter hosszú lesz. Ha a kimenet értéke kevesebb, mint 10 karakter, akkor a szóközök hozzáadódnak az érték elejéhez.
$ awk 'printf "% 10s \ n", $ 1' alkalmazott.txtKimenet:
Lépjen a Tartalom elemre
awk osztani a fehér helyet
Az alapértelmezett szó- vagy mezőelválasztó a szöveg felosztásához a szóköz. Az awk parancs a szövegértéket többféle módon is beveheti bevitelként. A bevitt szöveg átkerül visszhang parancsot a következő példában. A szöveg, 'Szeretek programozni'alapértelmezett elválasztóval lesz felosztva, tér, és a harmadik szót kinyomtatják.
$ echo 'szeretem programozni' | awk 'print $ 3'Kimenet:

Lépjen a Tartalom elemre
awk az elválasztó megváltoztatásához
Az awk paranccsal bármely fájl tartalmának elválasztója megváltoztatható. Tegyük fel, hogy van egy nevű szövegfájlja telefon.txt a következő tartalommal, ahol a ':' a fájl tartalmának mezőelválasztóként használatos.
telefon.txt
+123: 334: 889: 778+880: 1855: 456: 907
+9: 7777: 38644: 808
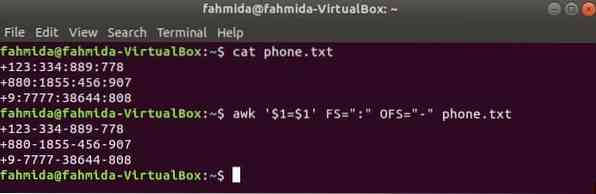
Futtassa a következő awk parancsot az elválasztó megváltoztatásához, ":" által '-' a fájl tartalmához, telefon.txt.
$ macska telefon.txt$ awk '$ 1 = $ 1' FS = ":" OFS = "-" telefon.txt
Kimenet:
Lépjen a Tartalom elemre
tabulátorral tagolt adatokkal awk
Az awk parancs sok beépített változóval rendelkezik, amelyeket a szöveg különböző módon történő olvasására használnak. Közülük kettő FS és OFS. FS a beviteli mező elválasztó és OFS kimeneti mező elválasztó változók. Ezeknek a változóknak a felhasználását ebben a szakaszban mutatjuk be. Hozzon létre egy fülre elválasztott fájl neve bemenet.txt a következő tartalommal tesztelni a FS és OFS változók.
Bemenet.txt
Ügyféloldali szkriptnyelvSzerveroldali parancsfájlnyelv
Adatbázis-kiszolgáló
Web szerver
Az FS változó használata füllel
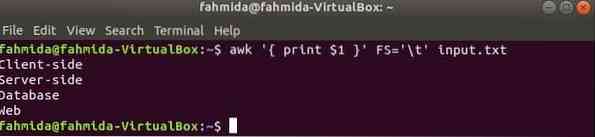
A következő parancs felosztja az egyes sorokat bemenet.txt fájlt a fül alapján ('\ t'), és kinyomtatja az egyes sorok első mezőjét.
$ awk 'print $ 1' FS = '\ t' bemenet.txtKimenet:
Az OFS változó használata tabulátorral
A következő awk parancs kinyomtatja a 9th és 5th mezők 'ls -l' parancs kimenet tabulátorral az oszlop címének kinyomtatása után “Név”És„Méret”. Itt, OFS változó a kimenet tabulátorral történő formázására szolgál.
$ ls -l$ ls -l | awk -v OFS = '\ t' 'BEGIN printf "% s \ t% s \ n", "Név", "Méret" print $ 9, $ 5'
Kimenet:

Lépjen a Tartalom elemre
awk CSV adatokkal
Bármely CSV fájl tartalma többféleképpen elemezhető az awk paranccsal. Hozzon létre egy CSV fájlt, amelynek neve:vevő.csv'A következő tartalommal az awk parancs alkalmazásához.
vevő.txt
Id, Név, e-mail, telefon1, Sophia, [e-mail védett], (862) 478-7263
2, Amelia, [e-mail védett], (530) 764-8000
3, Emma, [e-mail védett], (542) 986-2390
A CSV fájl egyetlen mezőjének olvasása
„-F” opció az awk paranccsal használható az elválasztó beállítására a fájl egyes sorainak felosztásához. A következő awk parancs kinyomtatja a név területe a vásárló.csv fájl.
$ macska ügyfél.csv$ awk -F "," 'print $ 2' ügyfél.csv
Kimenet: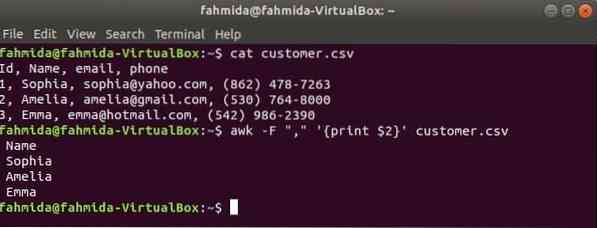
Több mező olvasása más szöveggel kombinálva
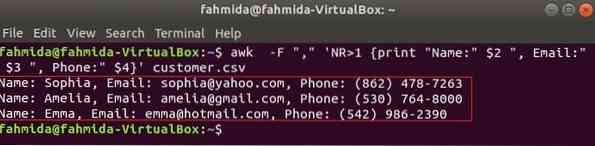
A következő parancs kinyomtatja a vevő.csv a címszöveg ötvözésével, Név, e-mail és telefon. A. Első sora vevő.csv fájl tartalmazza az egyes mezők címét. NR változó tartalmazza a fájl sorszámát, amikor az awk parancs elemzi a fájlt. Ebben a példában, az NR változó a fájl első sorának kihagyására szolgál. A kimeneten a 2 jelenik megnd, 3rd és 4th az összes sor mezői, kivéve az első sort.
$ awk -F "," 'NR> 1 print "Név:" $ 2 ", E-mail:" $ 3 ", Telefon:" $ 4' ügyfél.csvKimenet:
CSV fájl olvasása awk szkript segítségével
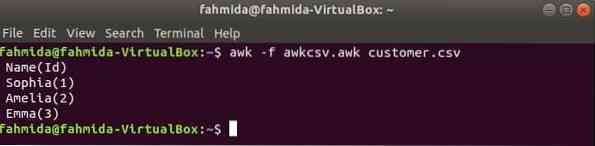
Az awk parancsfájl az awk fájl futtatásával futtatható. Az awk fájl létrehozásának és a fájl futtatásának módja ebben a példában látható. Hozzon létre egy nevű fájlt awkcsv.awk a következő kóddal. KEZDŐDIK kulcsszó a szkriptben az awk parancs tájékoztatására szolgál a. parancsfájl végrehajtásához KEZDŐDIK először más feladatok végrehajtása előtt. Itt mezőelválasztó (FS) a hasítóhatároló és a 2 meghatározására szolgálnd és 1utca a mezők a printf () függvényben használt formátumnak megfelelően kerülnek kinyomtatásra.
awkcsv.awkKEZDÉS FS = "," printf "% 5s (% s) \ n", $ 2, $ 1
Fuss awkcsv.awk fájl tartalmával a vásárló.csv fájlt a következő paranccsal.
$ awk -f awkcsv.awk ügyfél.csvKimenet:
Lépjen a Tartalom elemre
awk regex
A reguláris kifejezés egy minta, amelyet a szöveg bármely karakterláncában keresnek. Különböző típusú bonyolult keresési és helyettesítési feladatok nagyon egyszerűen elvégezhetők a reguláris kifejezés használatával. Az awk paranccsal ellátott reguláris kifejezés néhány egyszerű használatát ebben a szakaszban mutatjuk be.
Megfelelő karakterkészletA következő parancs egyezik a szóval Bolond vagy bolond vagy Menő a beviteli karakterlánccal, és nyomtassa ki, ha a szó megtalálható. Itt, Baba nem fog egyezni és nem nyomtat.
$ printf "Bolond \ nCool \ nDoll \ nbool" | awk '/ [FbC] ool /'Kimenet:

Karakterlánc keresése a sor elején
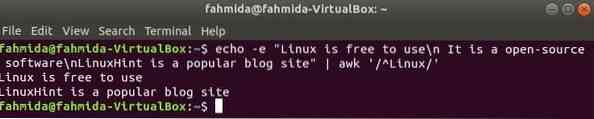
'^' szimbólumot használunk a reguláris kifejezésben, hogy bármilyen sort keressünk a sor elején. "Linux ' szót a következő példában a szöveg minden sorának elején meg kell keresni. Itt két sor kezdődik a szöveggel, - Linux'és ez a két sor megjelenik a kimenetben.
$ echo -e "A Linux szabadon használható \ n Ez egy nyílt forráskódú szoftver \ nLinuxHint azegy népszerű blogoldal "| awk '/ ^ Linux /'
Kimenet:
Karakterlánc keresése a sor végén
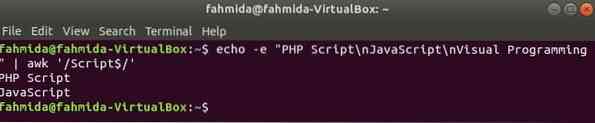
'$' szimbólumot használunk a reguláris kifejezésben, hogy a szöveg minden sorának végén bármilyen mintát keressünk. "Forgatókönyv'szóra a következő példában keresünk. Itt két sor tartalmazza a szót, Forgatókönyv a sor végén.
$ echo -e "PHP szkript \ nJavaScript \ nVizuális programozás" | awk '/ Script $ /'Kimenet:
Keresés az adott karakterkészlet kihagyásával
'^' szimbólum a szöveg kezdetét jelzi, ha bármilyen karakterláncminta előtt használják ('/ ^… /') vagy bármely által deklarált karakterkészlet előtt ^ […]. Ha a '^' szimbólumot használunk a harmadik zárójelben, [^…] akkor a zárójelben megadott karakterkészlet elmarad a kereséskor. A következő parancs keres minden olyan szót, amely nem kezdődik „F” de a következővel végződik:ool". Menő és bool a minta és a szöveges adatok szerint kerül kinyomtatásra.
$ printf "Bolond \ nCool \ nDoll \ nbool" | awk '/ [^ F] ool /'Kimenet:

Lépjen a Tartalom elemre
awk eset érzéketlen regex
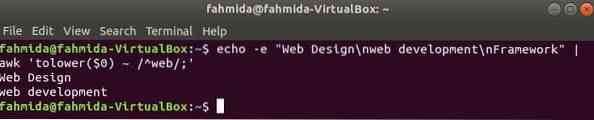
Alapértelmezés szerint a reguláris kifejezés kis- és nagybetűk közötti keresést végez, ha bármilyen mintát keres a karakterláncban. A kis- és nagybetűk közötti keresés az awk paranccsal végezhető el a reguláris kifejezéssel. A következő példában, tolni () függvény a kis- és nagybetűk érzéketlen keresésére szolgál. Itt a beviteli szöveg minden egyes sorának első szavát a kisbetűvé alakítja tolni () függvény és illeszkedik a reguláris kifejezés mintájához. felső () függvény is használható erre a célra, ebben az esetben a mintát nagybetűvel kell meghatározni. A következő példában meghatározott szöveg tartalmazza a kereső szót, 'web'két sorban, amelyeket kimenetként nyomtatnak.
$ echo -e "Webdesign \ nwebfejlesztés \ nKeret" | awk 'tolower ($ 0) ~ / ^ web /;'Kimenet:
Lépjen a Tartalom elemre
awk NF (mezők száma) változóval
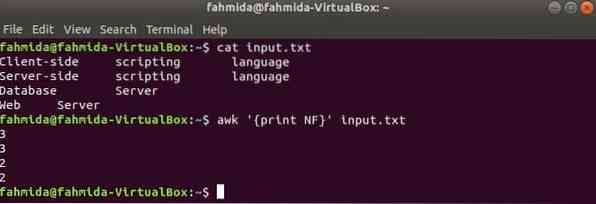
NF az awk parancs beépített változója, amelyet a beviteli szöveg minden sorában lévő mezők teljes számának számlálására használnak. Hozzon létre bármilyen szöveges fájlt több sorral és több szóval. a bemenet.txt fájlt használunk itt, amelyet az előző példában hoztak létre.
Az NF használata a parancssorból
Itt az első paranccsal a bemenet.txt A fájl és a második paranccsal a mezõk számát jeleníthetjük meg a fájl minden sorában NF változó.
$ cat bevitel.txt$ awk 'print NF' bemenet.txt
Kimenet:
Az NF használata az awk fájlban
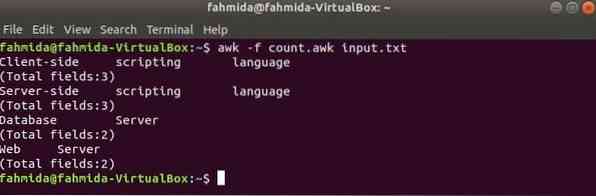
Hozzon létre egy nevű awk fájlt számol.awk az alább megadott szkript. Amikor ez a szkript bármilyen szöveges adattal végrehajtódik, akkor minden sor tartalma a teljes mezőkkel kimenetként lesz kinyomtatva.
számol.awk
print $ 0print "[Összes mező:" NF "]"
Futtassa a szkriptet a következő paranccsal.
$ awk -f count.awk bemenet.txtKimenet:
Lépjen a Tartalom elemre
awk gensub () függvény
getsub () egy helyettesítő függvény, amelyet a karakterláncok keresésére használnak meghatározott elválasztó vagy reguláris kifejezésminta alapján. Ezt a funkciót a „gawk” csomag, amely alapértelmezés szerint nincs telepítve. A függvény szintaxisa az alábbiakban található. Az első paraméter a reguláris kifejezésmintát vagy kereső elválasztót tartalmazza, a második paraméter a helyettesítő szöveget tartalmazza, a harmadik paraméter a keresés végrehajtásának módját, az utolsó paraméter pedig azt a szöveget tartalmazza, amelyben ezt a függvényt alkalmazni fogják.
Szintaxis:
gensub (regexp, csere, hogyan [, target])A telepítéshez futtassa a következő parancsot gawk csomag használatához getsub () függvény awk paranccsal.
$ sudo apt-get install gawkHozzon létre egy nevű szövegfájltsalesinfo.txta következő tartalommal a példa gyakorlásához. Itt a mezőket fül választja el.
salesinfo.txt
Hétfő 700000800000 kedd
Sze 750000
200000 csütörtök
Péntek 430000
820000 szombat
A következő parancs futtatásával olvassa el a salesinfo.txt fájl és nyomtassa ki az összes eladási összeget. Itt a harmadik paraméter, a „G” jelzi a globális keresést. Ez azt jelenti, hogy a minta a fájl teljes tartalmában keresésre kerül.
$ awk 'x = gensub ("\ t", "", "G", $ 2); printf x "+" VÉGE print 0 'értékesítési információ.txt | bc -lKimenet:

Lépjen a Tartalom elemre
awk rand () függvénnyel
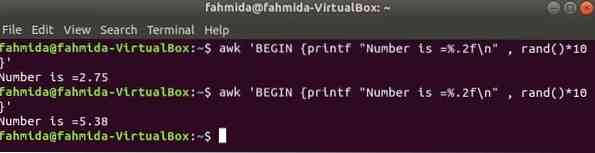
rand () függvény bármely tetszőleges, 0-nál nagyobb és 1-nél kisebb véletlenszám előállításához használható. Tehát mindig 1-nél kisebb tört számot generál. A következő parancs egy töredékes véletlen számot generál, és megszorozza az értéket 10-vel, hogy 1-nél nagyobb számot kapjon. A printf () függvény alkalmazásához a tizedespont után két számjegyből álló törtrész kerül kinyomtatásra. Ha a következő parancsot többször futtatja, akkor minden alkalommal más és más kimenetet kap.
$ awk 'BEGIN printf "A szám =%.2f \ n ", rand () * 10 'Kimenet:
Lépjen a Tartalom elemre
awk felhasználó által definiált függvény
Az előző példákban használt összes funkció beépített függvény. De kijelölhet egy felhasználó által definiált függvényt az awk szkriptben bármely adott feladat elvégzésére. Tegyük fel, hogy egy egyedi függvényt szeretne létrehozni egy téglalap területének kiszámításához. A feladat elvégzéséhez hozzon létre egy 'nevű fájltterület.awk'a következő szkript segítségével. Ebben a példában egy felhasználó által definiált függvény terület() deklarálva van a szkriptben, amely a bemeneti paraméterek alapján kiszámítja a területet, és visszaadja a terület értékét. getline paranccsal itt lehet bemenetet venni a felhasználótól.
terület.awk
# Számítsa ki a területetfunkcióterület (magasság, szélesség)
visszatérési magasság * szélesség
# Elindítja a végrehajtást
BEGIN
print "Adja meg a magasság értékét:"
getline h < "-"
print "Adja meg a szélesség értékét:"
getline w < "-"
"Terület =" terület nyomtatása (h, w)
Futtassa a szkriptet.
$ awk -f terület.awkKimenet:
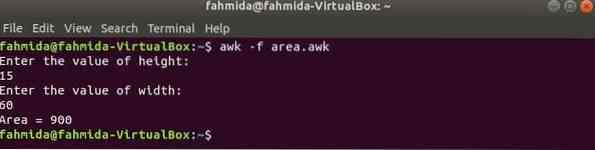
Lépjen a Tartalom elemre
awk ha példa
Az awk támogatja a feltételes utasításokat, mint más szabványos programozási nyelvek. Három típusú if utasítás látható ebben a szakaszban három példa felhasználásával. Hozzon létre egy szöveges fájlt elemeket.txt a következő tartalommal.
elemeket.txt
HDD Samsung 100 USDEgér A4Tech
Nyomtató 200 USD
Egyszerű, ha példa:
a következő parancs elolvassa a elemeket.txt fájlt, és ellenőrizze a 3rd mező értéke minden sorban. Ha az érték üres, akkor hibaüzenetet nyomtat a sorszámmal.
$ awk 'if ($ 3 == "") print "Az" NR' sorokban hiányzik az ármező.txtKimenet:
if-else példa:
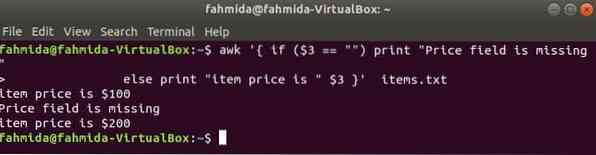
A következő parancs kinyomtatja az árat, ha a 3rd mező létezik a sorban, különben hibaüzenetet nyomtat.
$ awk 'if ($ 3 == "") print "Hiányzik az ármező"else print "a cikk ára" $ 3 "tétel.txt
Kimenet:
if-else-if példa:
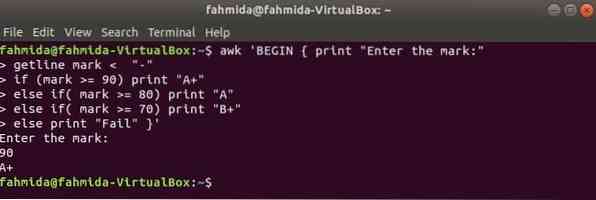
Amikor a következő parancs végrehajtásra kerül a terminálról, akkor a felhasználótól kell bemenetet fogadnia. A bemeneti értéket összehasonlítjuk az egyes if feltételekkel, amíg a feltétel igaz. Ha bármely feltétel igaz lesz, akkor kinyomtatja a megfelelő osztályzatot. Ha a bemeneti érték nem felel meg semmilyen feltételnek, akkor a nyomtatás sikertelen lesz.
$ awk 'BEGIN print "Írja be a jelet:"getline jel < "-"
ha (jelölés> = 90) "A +" nyomtatás
else if (mark> = 80) "A" nyomtatása
else if (mark> = 70) "B +" nyomtatás
máshol kinyomtatja a "Fail" '
Kimenet:
Lépjen a Tartalom elemre
awk változók
Az awk változó deklarációja hasonló a shell változó deklarációjához. Különbség van a változó értékének leolvasásában. '$' szimbólumot használunk a változó nevével a shell változóhoz az érték beolvasására. De az érték leolvasásához nem kell használni a „$” szót az awk változóval.
Egyszerű változó használata:
A következő parancs deklarálja a nevű változót 'webhely' és egy string értéket rendelünk ahhoz a változóhoz. A változó értékét a következő utasítás írja ki.
$ awk 'BEGIN site = "LinuxHint.com "; site nyomtatása 'Kimenet:

Változó használata adatok kinyeréséhez egy fájlból
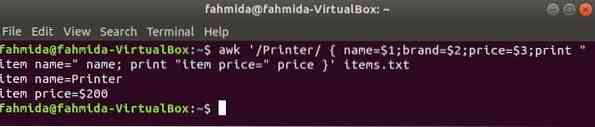
A következő parancs megkeresi a szót 'Nyomtató' az aktában elemeket.txt. Ha a fájl bármely sora kezdődik 'Nyomtató'akkor tárolja a 1utca, 2nd és 3rd mezőket három változóra. név és ár változókat kinyomtatják.
$ awk '/ Nyomtató / név = $ 1; márka = 2 USD; ár = 3 USD; nyomtassa ki az "elem neve =" nevet;"item price =" price "elemek nyomtatása.txt
Kimenet:
Lépjen a Tartalom elemre
awk tömbök
A numerikus és a kapcsolódó tömbök egyaránt használhatók az awk-ban. Az awk tömb változó deklarációja megegyezik más programozási nyelvekkel. A tömbök egyes felhasználásait ebben a szakaszban mutatjuk be.
Asszociatív tömb:
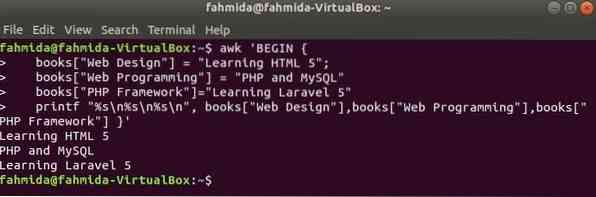
A tömb indexe bármilyen karakterlánc lesz az asszociatív tömb számára. Ebben a példában három elem asszociatív tömbjét deklaráljuk és kinyomtatjuk.
$ awk 'BEGINkönyvek ["Web Design"] = "HTML 5 tanulása";
könyvek ["Web programozás"] = "PHP és MySQL"
könyvek ["PHP Framework"] = "Learning Laravel 5"
printf "% s \ n% s \ n% s \ n", könyvek ["Webdesign"], könyvek ["Webprogramozás"],
könyvek ["PHP keretrendszer"] '
Kimenet:
Numerikus tömb:
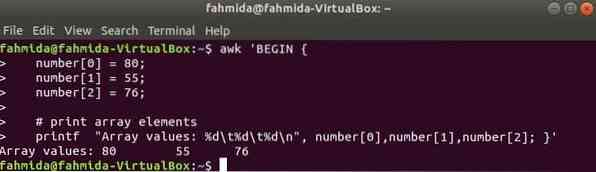
Három elem numerikus tömbjét deklaráljuk és kinyomtatjuk az elválasztó fül segítségével.
$ awk 'BEGINszám [0] = 80;
szám [1] = 55;
szám [2] = 76;
# tömbelemek nyomtatása
printf "Tömbértékek:% d \ t% d \ t% d \ n", szám [0], szám [1], szám [2]; '
Kimenet:
Lépjen a Tartalom elemre
awk hurok
Három típusú hurkot támogat az awk. Ezeknek a hurkoknak a felhasználását három példa segítségével mutatjuk be.
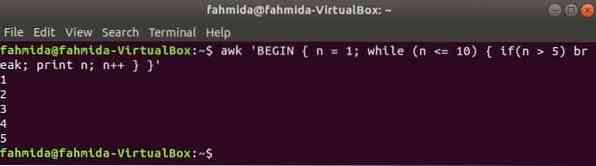
While hurok:
míg a következő parancsban használt ciklus ötször fog ismétlődni, és kilép a ciklusból a break utasításhoz.
$ Awk 'BEGIN n = 1; míg (n <= 10) if(n > 5) törés; nyomtatás n; n ++ 'Kimenet:
Hurok esetén:
A következő awk parancsban használt ciklus esetén az összeg 1-től 10-ig lesz kiszámolva, és kiírja az értéket.
$ awk 'BEGIN összeg = 0; mert (n = 1; n <= 10; n++) sum=sum+n; print sum 'Kimenet:

Do-while hurok:
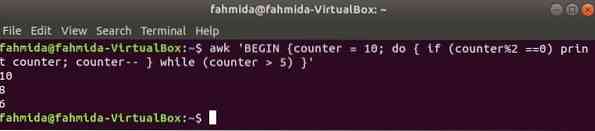
A következő parancs do-while ciklusa kinyomtatja az összes páros számot 10-től 5-ig.
$ awk 'BEGIN számláló = 10; do if (számláló% 2 == 0) számláló nyomtatása; számláló--míg (számláló> 5) '
Kimenet:
Lépjen a Tartalom elemre
awk az első oszlop kinyomtatásához
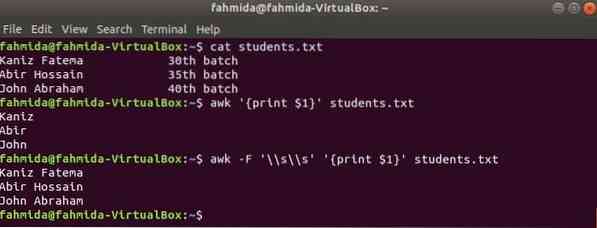
Bármely fájl első oszlopa kinyomtatható az $ 1 változó használatával az awk fájlban. De ha az első oszlop értéke több szót tartalmaz, akkor csak az első oszlop első szava nyomtatódik ki. Egy meghatározott határoló használatával az első oszlop megfelelően kinyomtatható. Hozzon létre egy szöveges fájlt diákok.txt a következő tartalommal. Itt az első oszlop két szó szövegét tartalmazza.
Diákok.txt
Kaniz Fatema 30th tételAbir Hossain 35th tétel
Ábrahám János 40th tétel
Futtassa az awk parancsot elválasztó nélkül. Az első oszlop első részét kinyomtatják.
$ awk 'print $ 1' diákok.txtFuttassa az awk parancsot a következő elválasztóval. Az első oszlop teljes részét kinyomtatják.
$ awk -F '\\ s \\ s' 'print $ 1' diákok.txtKimenet:
Lépjen a Tartalom elemre
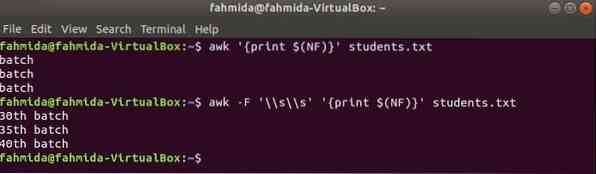
awk az utolsó oszlop kinyomtatásához
$ (NF) változó bármely fájl utolsó oszlopának kinyomtatására használható. A következő awk parancsok kinyomtatják az utolsó oszlop utolsó és teljes részét A diákok.txt fájl.
$ awk 'print $ (NF)' diákok.txt$ awk -F '\\ s \\ s' 'print $ (NF)' diákok.txt
Kimenet:
Lépjen a Tartalom elemre
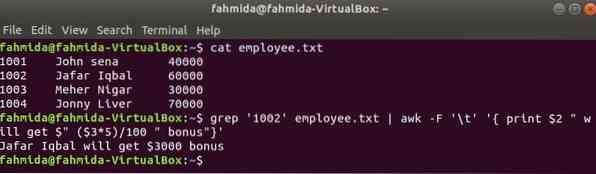
awk a grep-kel
A grep egy másik hasznos parancs a Linux számára, hogy bármilyen szabályos kifejezés alapján fájlban keressen tartalmat. Az awk és a grep parancsok együttes használatát a következő példa mutatja. grep a parancs a munkavállalói azonosító információinak keresésére szolgál, '1002' tól től az alkalmazott.txt fájl. A grep parancs kimenetét bemeneti adatokként elküldjük az awk-nak. 5% -os bónuszt számolnak és nyomtatnak a munkavállaló azonosítója fizetése alapján. "1002 ” awk paranccsal.
$ macska alkalmazott.txt$ grep '1002' alkalmazott.txt | awk -F '\ t' 'print $ 2 "$" ($ 3 * 5) / 100 "bónuszt"' kap
Kimenet:
Lépjen a Tartalom elemre
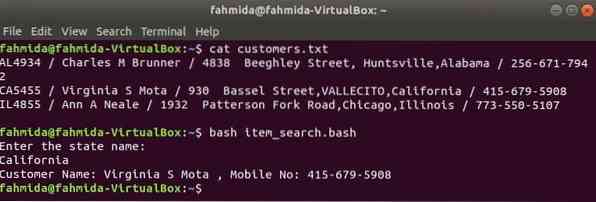
awk BASH fájllal
A többi Linux parancshoz hasonlóan az awk parancs is használható BASH szkriptben. Hozzon létre egy szöveges fájlt ügyfelek.txt a következő tartalommal. A fájl minden sora négy mezőben tartalmaz információkat. Ezek az ügyfél azonosítója, neve, címe és mobilszáma, amelyek elválasztva egymástól '/".
ügyfelek.txt
AL4934 / Charles M Brunner / 4838 Beeghley Street, Huntsville, Alabama / 256-671-7942CA5455 / Virginia S Mota / 930 Bassel Street, VALLECITO, Kalifornia / 415-679-5908
IL4855 / Ann A Neale / 1932 Patterson Fork Road, Chicago, Illinois / 773-550-5107
Hozzon létre egy bash fájlt item_search.bash a következő forgatókönyvvel. Ennek a szkriptnek megfelelően az állapotértéket a felhasználó veszi át és keresi meg a vásárlók.txt fájl által grep parancsot, és bemenetként átadta az awk parancsnak. Awk parancs beolvas 2nd és 4th az egyes sorok mezői. Ha a bemeneti érték megegyezik bármelyik állapotértékkel ügyfelek.txt fájlt, akkor kinyomtatja az ügyfélét név és mobil szám, különben kinyomtatja a következő üzenetet:Nem található ügyfél”.
item_search.bash
#!/ bin / bashecho "Írja be az állam nevét:"
olvasási állapot
ügyfelek = 'grep "$ state" ügyfelek.txt | awk -F "/" 'print "Ügyfél neve:" $ 2 ",
Mobilszám: "$ 4" "
ha ["$ ügyfelek" != ""]; azután
echo $ ügyfelek
más
visszhang "Nem található ügyfél"
fi
A kimenetek megjelenítéséhez futtassa az alábbi parancsokat.
$ macska ügyfelek.txt$ bash item_search.bash
Kimenet:
Lépjen a Tartalom elemre
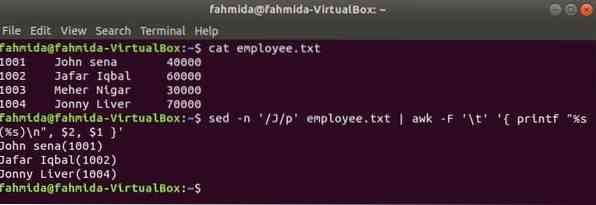
awk sed
A Linux másik hasznos kereső eszköze sed. Ez a parancs bármely fájl szövegének keresésére és cseréjére egyaránt használható. A következő példa az awk parancs használatát mutatja be a sed parancs. Itt a sed parancs megkeresi az összes alkalmazott nevét 'J'és bemenetként átkerül az awk parancsra. Az awk kinyomtatja az alkalmazottat név és ID formázás után.
$ macska alkalmazott.txt$ sed -n '/ J / p' alkalmazott.txt | awk -F '\ t' 'printf "% s (% s) \ n", $ 2, $ 1'
Kimenet:
Lépjen a Tartalom elemre
Következtetés:
Az awk paranccsal különféle típusú jelentéseket hozhat létre táblázatos vagy elválasztott adatok alapján az adatok megfelelő szűrése után. Remélem, az oktatóanyagban bemutatott példák gyakorlása után megtudhatja, hogyan működik az awk parancs.


