A TextBlob használata az iparban
Ahogy hangzik, a TextBlob egy Python csomag, amely egyszerű és összetett szövegelemzési műveleteket hajt végre olyan szöveges adatokon, mint a beszédcímkézés, a főnévi kifejezés kinyerése, az érzelmek elemzése, az osztályozás, a fordítás és egyebek. Bár sokkal több olyan eset van a TextBlob számára, amelyet más blogokban is bemutathatunk, ez a Tweets elemzésével foglalkozik az érzelmeikkel kapcsolatban.
Az elemzési vélemények nagyszerű gyakorlati felhasználást kínálnak számos forgatókönyv esetében:
- Egy földrajzi régió politikai választásai során a tweetek és más közösségi média tevékenységek nyomon követhetők a becsült kilépési szavazások és eredmények készítéséhez a közelgő kormányról
- Különböző vállalatok felhasználhatják a közösségi médiában végzett szöveges elemzést, hogy gyorsan azonosítsák az adott régióban a közösségi médiában keringő negatív gondolatokat a problémák azonosítása és megoldása érdekében
- Egyes termékek még tweeteket is használnak, hogy megbecsüljék az emberek társadalmi aktivitásukból fakadó orvosi tendenciáit, például az általuk készített tweetek típusát, esetleg öngyilkosak stb.
A TextBlob használatának megkezdése
Tudjuk, hogy azért jött ide, hogy megnézzen néhány gyakorlati kódot a TextBlob nevű érzelmi elemzőhöz kapcsolódóan. Éppen ezért ezt a részt rendkívül rövid ideig tartjuk a TextBlob bevezetéséhez az új olvasók számára. Csak egy megjegyzés a megkezdés előtt, hogy használjuk a virtuális környezet erre a leckére, amelyet a következő paranccsal készítettünk
python -m virtualenv textblobforrás textblob / bin / aktiválás
Miután a virtuális környezet aktív, telepíthetjük a TextBlob könyvtárat a virtuális env-be, hogy a következő módon létrehozott példák végrehajthatók legyenek:
pip install -U textblobMiután futtatta a fenti parancsot, ez nem az. A TextBlob-nak hozzáférést kell kapnia néhány képzési adathoz, amelyek a következő paranccsal tölthetők le:
python -m textblob.letöltés_korporákValami ilyesmit fog látni a szükséges adatok letöltésével: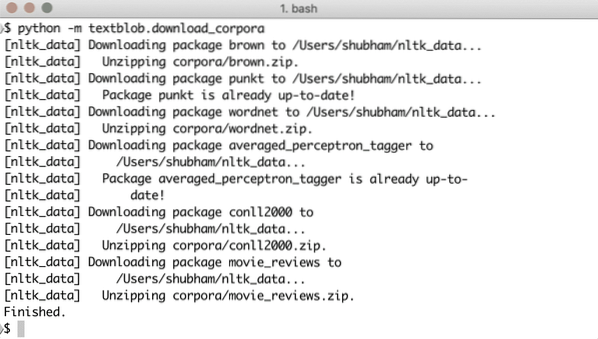
Használhatja az Anaconda-t is ezeknek a példáknak a futtatásához, ami könnyebb. Ha telepíteni szeretné a számítógépére, nézze meg a „Hogyan telepítsük az Anaconda Python-ot az Ubuntu 18-ra” című leckét.04 LTS ”, és ossza meg visszajelzését.
Ha egy nagyon gyors példát szeretne bemutatni a TextBlob számára, íme egy példa közvetlenül a dokumentációjából:
a textblob importálásából TextBlobszöveg = ""
A The Blob címzetes fenyegetése mindig is a legfőbb filmként hatott rám
szörny: telhetetlenül éhes, amőba-szerű tömeg, amely képes behatolni
gyakorlatilag bármilyen biztosíték, amely képes - mint egy elítélt orvos hidegen
leírja - "asszimilálódó hús érintkezéskor.
Átkozottul kell összehasonlítani a zselatinnal végzett snide összehasonlításokat, ez a legtöbb koncepció
a lehetséges következmények pusztító, nem ellentétben a szürke gólya forgatókönyvvel
technológiai teoretikusok javasolták félve
a mesterséges intelligencia tombol.
""
blob = TextBlob (szöveg)
nyomtatás (folt.címkék)
nyomtatás (folt.főnév_mondatok)
foltban mondatra.mondatok:
nyomtatás (mondat.érzés.polaritás)
folt.lefordítani (= = es)
A fenti program futtatásakor a következő címszavakat kapjuk, és végül azokat az érzelmeket, amelyeket a példa szövegében szereplő két mondat demonstrál:
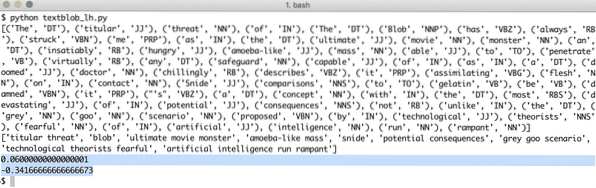
A szavak és érzelmek címkézése segít meghatározni azokat a fő szavakat, amelyek ténylegesen befolyásolják az érzelmek kiszámítását és a mondat polaritását. Ez azért van, mert a szavak jelentése és hangulata a használatuk sorrendjében megváltozik, ezért mindezt dinamikusan kell fenntartani.
Lexikon alapú hangulatelemzés
Bármely érzés egyszerűen meghatározható a mondatban használt szavak szemantikai orientációjának és intenzitásának függvényében. A lexikonon alapuló megközelítés alapján az érzelmek azonosításához egy adott szóban vagy mondatban minden szóhoz egy pontszám társul, amely leírja a szó érzelmét (vagy legalábbis megpróbálja kimutatni). Általában a legtöbb szónak előre definiált szótára van a lexikális pontszámáról, de ha emberről van szó, akkor mindig szarkazmusra van szükség, szóval ezekre a szótárakra nem támaszkodhatunk 100% -ban. A WordStat Sentiment Dictionary több mint 9164 negatív és 4847 pozitív szómintát tartalmaz.
Végül, van egy másik módszer a hangulatelemzés elvégzésére (ezen a leckén kívül), amely egy gépi tanulási technika, de nem használhatunk egy ML algoritmus összes szavát, mivel biztosan szembesülünk a túlillesztéssel. Alkalmazhatjuk az egyik jellemzőválasztó algoritmust, például a Chi Square vagy a Mutual Information, mielőtt betanítanánk az algoritmust. Az ML megközelítés tárgyalását csak erre a szövegre korlátozzuk.
A Twitter API használata
Ha tweeteket szeretne kapni közvetlenül a Twitterről, keresse fel az alkalmazásfejlesztő honlapját itt:
https: // fejlesztő.twitter.com / hu / apps
Regisztrálja jelentkezését az alább megadott űrlap kitöltésével:
Miután megkapta az összes tokent a „Kulcsok és tokenek” lapon:
Használhatjuk a kulcsokat, hogy megszerezzük a szükséges tweetteket a Twitter API-tól, de telepítenünk kell még egy Python csomagot, amely megnehezíti számunkra a Twitter-adatok megszerzését:
pip telepíteni tweepyA fenti csomagot használjuk a Twitter API-val folytatott minden nehéz kommunikáció befejezéséhez. A Tweepy előnye, hogy nem kell sok kódot írnunk, amikor hitelesíteni akarjuk alkalmazásunkat a Twitter-adatokkal való interakció érdekében, és automatikusan be van csomagolva egy nagyon egyszerű API-ba, amelyet a Tweepy csomag tesz elérhetővé. A fenti csomagot a programunkba importálhatjuk:
import tweepyEzek után csak meg kell határoznunk a megfelelő változókat, ahol megtarthatjuk a fejlesztői konzoltól kapott Twitter-kulcsokat:
fogyasztói_kulcs = '[fogyasztói_kulcs]'consumer_key_secret = '[fogyasztói_kulcs_secret]'
access_token = '[access_token]'
access_token_secret = '[access_token_secret]'
Most, hogy meghatároztuk a kód titkait a Twitter számára, készen állunk arra, hogy kapcsolatot teremtsünk a Twitterrel, hogy megkapjuk a tweeteket és megítéljük őket, mármint elemezzem őket. Természetesen a Twitter-hez való kapcsolatot az OAuth és a A Tweepy csomag jól jön a kapcsolat létrehozásához is:
twitter_auth = tweepy.OAuthHandler (fogyasztói_kulcs, fogyasztói_kulcs_titok)Végül szükségünk van a kapcsolatra:
api = tweepy.API (twitter_auth)Az API-példány használatával bármilyen témát megkereshetünk a Twitteren, amelyet átadunk neki. Ez lehet egyetlen szó vagy több szó. Annak ellenére, hogy javasoljuk a lehető legkevesebb szó használatát a pontosság érdekében. Próbáljunk ki egy példát itt:
pm_tweets = api.keresés ("India")A fenti keresés sok tweetet ad nekünk, de korlátozzuk a visszaküldött tweetek számát, hogy a hívás ne kerüljön túl sok időbe, mivel később a TextBlob csomagnak is feldolgoznia kell:
pm_tweets = api.keresés ("India", count = 10)Végül kinyomtathatjuk minden egyes tweet szövegét és a hozzá kapcsolódó érzelmeket:
a tweethez a pm_tweets-ben:nyomtatás (tweet.szöveg)
elemzés = TextBlob (tweet.szöveg)
nyomtatás (elemzés.érzés)
Miután lefuttattuk a fenti szkriptet, elkezdjük kapni az említett lekérdezés utolsó 10 említését, és minden egyes tweetet elemezni fogunk a hangulatérték szempontjából. Itt van a kimenet, amelyet ugyanarról kaptunk:

Ne feledje, hogy streaming hangulatelemző botot is készíthet a TextBlob és a Tweepy programmal. A Tweepy lehetővé teszi a webaljzat-streaming kapcsolat létrehozását a Twitter API-val, és lehetővé teszi a Twitter-adatok valós időben történő streamelését.
Következtetés
Ebben a leckében egy kiváló szövegelemző csomagot néztünk meg, amely lehetővé teszi számunkra a szöveges érzelmek és még sok más elemzését. A TextBlob népszerű, mert lehetővé teszi számunkra, hogy egyszerűen dolgozzunk a szöveges adatokkal anélkül, hogy bármilyen bonyolult API-hívásról lenne szó. A Tweepy-t is integráltuk a Twitter-adatok felhasználása érdekében. Könnyen módosíthatjuk a streaming használati esetet ugyanazzal a csomaggal és nagyon kevés változtatással magában a kódban.
Kérjük, ossza meg szabadon visszajelzését a leckéről a Twitteren a @linuxhint és @sbmaggarwal (ez vagyok én!).


