A NumPy könyvtár lehetővé teszi számunkra, hogy különféle műveleteket hajtsunk végre a gépi tanulásban és az adattudományban gyakran használt adatstruktúrákon, például vektorokon, mátrixokon és tömbökön. Csak a leggyakoribb műveleteket mutatjuk meg a NumPy-vel, amelyeket sok Machine Learning csővezetékben használnak. Végül, kérjük, vegye figyelembe, hogy a NumPy csak egy módja a műveletek végrehajtásának, így az általunk bemutatott matematikai műveletek állnak ennek a leckének a középpontjában, és nem maga a NumPy csomag. Kezdjük el.
Mi az a vektor?
A Google szerint a Vektor olyan mennyiség, amelynek iránya és nagysága egyaránt van, különösen, ha meghatározzuk az egyik térpontot a térhez képest.
A vektorok nagyon fontosak a gépi tanulásban, mivel nem csak leírják a nagyságrendet, hanem a funkciók irányát is. Hozhatunk létre egy vektort a NumPy-ben a következő kódrészlettel:
importálja a numpy-t np-kéntsor_vektor = np.tömb ([1,2,3])
nyomtatás (sorvektor)
A fenti kódrészletben létrehoztunk egy sorvektort. Hozhatunk létre oszlopvektort is:
importálja a numpy-t np-kéntcol_vector = np.tömb ([[1], [2], [3]])
nyomtatás (col_vector)
Mátrix készítése
A mátrix egyszerűen kétdimenziós tömbként értelmezhető. Készíthetünk egy mátrixot a NumPy-vel egy többdimenziós tömb létrehozásával:
mátrix = np.tömb ([[1, 2, 3], [4, 5, 6], [7, 8, 9]])nyomtatás (mátrix)
Bár a mátrix pontosan hasonlít a többdimenziós tömbhöz, a mátrix adatszerkezete nem ajánlott két okból:
- A tömb a standard, amikor a NumPy csomagról van szó
- A NumPy műveletek többsége tömböt ad vissza, nem pedig mátrixot
Ritka mátrix használata
Emlékeztetni kell arra, hogy egy ritka mátrix az, amelyben a legtöbb elem nulla. Az adatfeldolgozás és a gépi tanulás általános forgatókönyve az a mátrixok feldolgozása, amelyekben az elemek többsége nulla. Vegyünk például egy mátrixot, amelynek sorai a Youtube minden videóját leírják, az oszlopok pedig minden regisztrált felhasználót képviselnek. Minden érték azt jelzi, hogy a felhasználó megtekintett-e videót vagy sem. Természetesen ebben a mátrixban az értékek többsége nulla lesz. A előny ritka mátrixszal az, hogy nem tárolja a nulla értékeket. Ez hatalmas számítási előnyt és tárolási optimalizálást is eredményez.
Készítsünk itt egy szikra mátrixot:
scipy importból ritkáneredeti_mátrix = np.tömb ([[1, 0, 3], [0, 0, 6], [7, 0, 0]])
ritkás_mátrix = ritka.csr_matrix (original_matrix)
nyomtatás (ritka_mátrix)
A kód működésének megértéséhez itt nézzük meg a kimenetet:
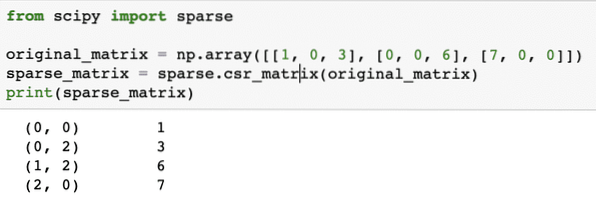
A fenti kódban egy NumPy függvényt használtunk a Tömörített ritka sor mátrix, ahol a nem nulla elemeket a nulla alapú indexek segítségével ábrázoljuk. Különféle ritka mátrixok léteznek, például:
- Tömörített ritka oszlop
- Listák listája
- Kulcsszótár
Itt nem merülünk el más ritka mátrixokban, de tudjuk, hogy mindegyikük felhasználása specifikus, és senkit sem lehet „legjobbnak” nevezni.
Műveletek alkalmazása minden vektorelemre
Gyakori forgatókönyv, amikor több vektorelemre közös műveletet kell alkalmaznunk. Ezt úgy tehetjük meg, hogy definiálunk egy lambdát, majd ezt vektorizáljuk. Lássunk néhány kódrészletet ugyanarról:
mátrix = np.sor([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
mul_5 = lambda x: x * 5
vectorized_mul_5 = np.vektorizálás (mul_5)
vectorized_mul_5 (mátrix)
A kód működésének megértéséhez itt nézzük meg a kimenetet:

A fenti kódrészletben a NumPy könyvtár részét képező vectorize függvényt alkalmaztuk, hogy az egyszerű lambda definíciót olyan funkcióvá alakítsuk, amely képes feldolgozni a vektor minden elemét. Fontos megjegyezni, hogy a vektorizálás az csak egy hurok az elemek fölött és nincs hatása a program teljesítményére. A NumPy is engedélyezi műsorszórás, ami azt jelenti, hogy a fenti összetett kód helyett egyszerűen megtehettük volna:
mátrix * 5És az eredmény pontosan ugyanaz lett volna. Először az összetett részt szerettem volna bemutatni, különben kihagyta volna a szakaszt!
Átlag, szórás és szórás
A NumPy segítségével könnyen elvégezhető a vektorok leíró statisztikájához kapcsolódó műveletek. A vektor átlaga a következőképpen számítható:
np.átlag (mátrix)A vektor varianciája a következőképpen számítható:
np.var (mátrix)A vektor szórása a következőképpen számítható:
np.std (mátrix)A fenti parancsok kimenete az adott mátrixon itt található:

Mátrix átültetése
Az átültetés nagyon gyakori művelet, amelyről akkor hallani fog, ha mátrixok vesznek körül. Az átültetés csak egy módja a mátrix oszlop- és sorértékeinek cseréjének. Felhívjuk figyelmét, hogy a a vektor nem transzponálható mivel a vektor csak értékek gyűjteménye, anélkül, hogy ezeket az értékeket sorokba és oszlopokba sorolnák. Felhívjuk figyelmét, hogy egy sorvektor oszlopvektorrá konvertálása nem transzponálódik (a lineáris algebra definíciói alapján, amely kívül esik a lecke körén).
Egyelőre csak egy mátrix átültetésével találunk békét. Nagyon egyszerű hozzáférni a mátrix transzponálásához a NumPy segítségével:
mátrix.TA fenti parancs kimenete az adott mátrixon itt található:
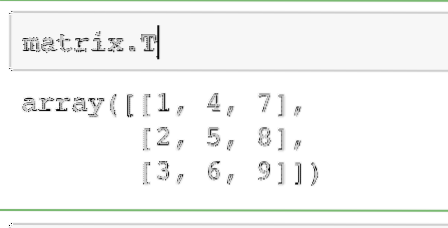
Ugyanaz a művelet hajtható végre egy sorvektoron annak oszlopvektorrá konvertálásához.
Egy mátrix lapítása
Átalakíthatunk egy mátrixot egydimenziós tömbgé, ha elemeit lineárisan szeretnénk feldolgozni. Ezt a következő kódrészlettel lehet megtenni:
mátrix.lelapul()A fenti parancs kimenete az adott mátrixon itt található:

Vegye figyelembe, hogy a lapított mátrix egydimenziós tömb, egyszerűen lineáris.
Sajátértékek és sajátvektorok kiszámítása
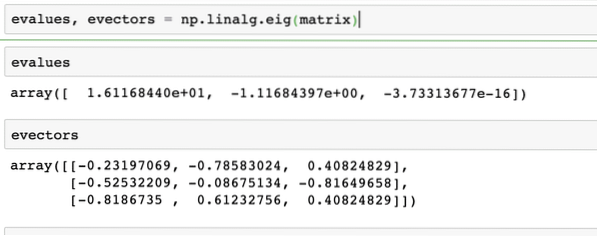
A sajátvektorokat nagyon gyakran használják a Machine Learning csomagokban. Tehát, ha egy lineáris transzformációs függvényt mátrixként mutatunk be, akkor X, az Eigenvektorok azok a vektorok, amelyek csak a vektor méretarányában változnak, de iránya nem. Mondhatjuk, hogy:
Xv = γvItt X a négyzetmátrix, γ pedig a sajátértékeket. A v tartalmazza a sajátvektorokat is. A NumPy segítségével könnyen kiszámítható a sajátértékek és a sajátvektorok. Itt van a kódrészlet, ahol ugyanazt mutatjuk be:
evalues, evectors = np.linalg.eig (mátrix)A fenti parancs kimenete az adott mátrixon itt található:
A vektorok ponttermékei
A vektorok ponttermékei 2 vektor szorzásának egyik módja. Erről mesél hogy a vektorok mekkora része azonos irányú, ellentétben a kereszttermékkel, amely az ellenkezőjét mondja meg, hogy a vektorok milyen kevéssé vannak ugyanabban az irányban (ortogonálisnak nevezik). Kiszámíthatjuk két vektor dot szorzatát a kódrészletben megadottak szerint:
a = np.tömb ([3, 5, 6])b = np.tömb ([23, 15, 1])
np.pont (a, b)
A fenti parancs kimenete az adott tömbökön itt található:

Mátrixok összeadása, kivonása és szorzása
Több mátrix hozzáadása és kivonása a mátrixokban meglehetősen egyszerű művelet. Kétféle módon lehet ezt megtenni. Nézzük meg a kódrészletet ezeknek a műveleteknek a végrehajtásához. Ennek az egyszerűségnek a megtartása érdekében kétszer ugyanazt a mátrixot fogjuk használni:
np.add (mátrix, mátrix)Ezután két mátrixot lehet levonni a következőképpen:
np.kivonás (mátrix, mátrix)A fenti parancs kimenete az adott mátrixon itt található:
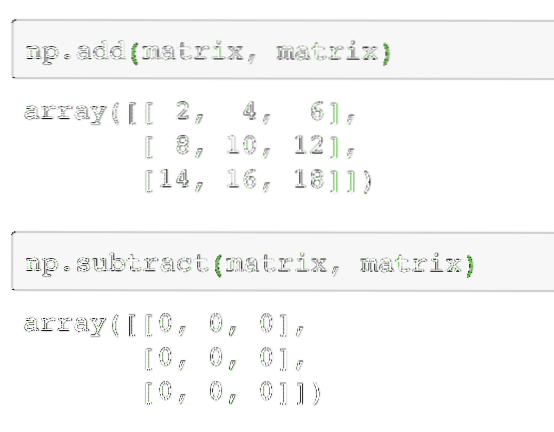
Ahogy az várható volt, a mátrix minden egyes elemét hozzáadjuk / kivonjuk a megfelelő elemmel. A mátrix szorzása hasonló a ponttermék megkereséséhez, mint korábban:
np.pont (mátrix, mátrix)A fenti kód meg fogja találni két mátrix valódi szorzási értékét:
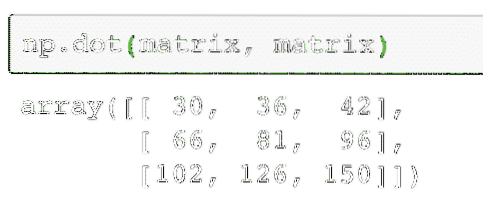
A fenti parancs kimenete az adott mátrixon itt található:

Következtetés
Ebben a leckében sok matematikai műveletet hajtottunk végre a gyakran használt vektorokkal, mátrixokkal és tömbökkel kapcsolatban. Adatfeldolgozás, leíró statisztikák és adattudomány. Ez egy gyors lecke volt, amely csak a legkülönbözőbb fogalmak leggyakoribb és legfontosabb szakaszaira terjedt ki, de ezeknek a műveleteknek nagyon jó ötletet kell adniuk arról, hogy mi minden művelet hajtható végre ezen adatstruktúrák kezelése közben.
Kérjük, ossza meg szabadon visszajelzését a leckéről a Twitteren a @linuxhint és @sbmaggarwal (ez vagyok én!).


