A blog kódja és az adatkészlet a következő https: // github linken érhető el.com / shekharpandey89 / k-mean
A K-Means klaszter felügyelet nélküli gépi tanulási algoritmus. Ha összehasonlítjuk a K-Means felügyelet nélküli fürtözési algoritmust a felügyelt algoritmussal, akkor nem szükséges a modellt betanítani a címkézett adatokkal. A K-Means algoritmust arra használják, hogy a különböző objektumokat attribútumuk vagy jellemzőik alapján K számú csoportba sorolják vagy csoportosítsák. Itt K egy egész szám. A K-Means kiszámítja a távolságot (a távolság képletének felhasználásával), majd megtalálja a minimális távolságot az adatpontok és a centroid fürt között az adatok osztályozásához.
Értsük meg a K-Jeleket a 4 objektumot használó kis példával, és mindegyik objektumnak 2 attribútuma van.
| ObjectsName | Attribútum_X | Attribútum_Y |
|---|---|---|
| M1 | 1 | 1 |
| M2 | 2 | 1 |
| M3 | 4 | 3 |
| M4 | 5 | 4 |
K-numerikus példa megoldásának eszközei:
A fenti numerikus probléma megoldásához a K-Means segítségével a következő lépéseket kell végrehajtanunk:
A K-Means algoritmus nagyon egyszerű. Először tetszőleges számú K-t kell választanunk, majd meg kell választanunk a centrumok vagy a klaszterek középpontját. A centridok kiválasztásához tetszőleges számú objektumot választhatunk az inicializáláshoz (a K értékétől függ).
A K-Means algoritmus alapvető lépései a következők:
- Addig fut, amíg egyetlen objektum sem mozdul el a középpontjából (stabil).
- Először véletlenszerűen választunk néhány centridot.
- Ezután meghatározzuk az egyes objektumok és a centridák távolságát.
- Az objektumok csoportosítása a minimális távolság alapján.
Tehát minden objektumnak két pontja van, mint X és Y, és ezek a gráftéren a következőképpen jelennek meg:
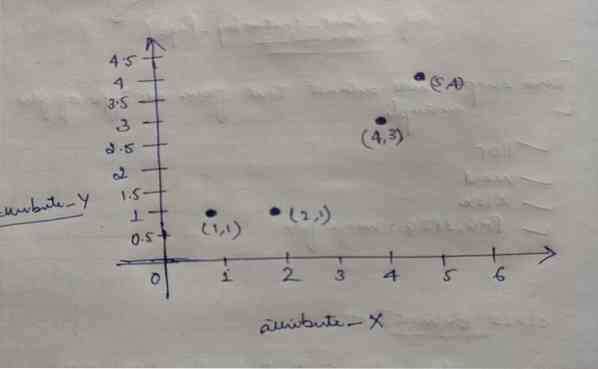
Tehát a K = 2 értékét kezdetben véletlenszerűen választjuk meg a fenti probléma megoldásához.
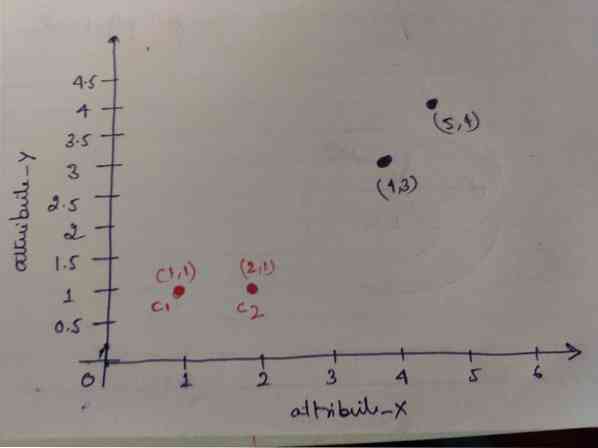
1. lépés: Kezdetben az első két objektumot (1, 1) és (2, 1) választjuk ki a centridánknak. Az alábbi grafikon ugyanazt mutatja. Ezeket a centridákat C1 (1, 1) és C2 (2,1). Itt azt mondhatjuk, hogy C1 a_1 csoport és C2 a_2 csoport.
2. lépés: Most az egyes objektumok adatpontjait az euklideszi távolság képletével kiszámítjuk a centridákra.
A távolság kiszámításához a következő képletet használjuk.

Kiszámoljuk az objektumok és a centridok közötti távolságot, az alábbi képen látható módon.

Tehát minden objektum adatpont távolságát kiszámítottuk a fenti távolság módszerrel, végül megkaptuk a távolság mátrixot az alábbiak szerint:
DM_0 =
| 0 | 1 | 3.61 | 5 | C1 = (1,1) klaszter1 | csoport_1 |
| 1 | 0 | 2.83 | 4.24 | C2 = (2,1) klaszter2 | csoport_2 |
| A | B | C | D | |
|---|---|---|---|---|
| 1 | 2 | 4 | 5 | x |
| 1 | 1 | 3 | 4 | Y |
Most kiszámoltuk az egyes objektumok távolságértékét az egyes centroidokhoz. Például az objektumpontok (1,1) távolsága c1-ig 0 és c2 1.
Mivel a fenti távolságmátrixból megtudhatjuk, hogy az (1, 1) objektum távolsága az 1. klaszterig (c1) 0 és a 2. fürtig (c2) 1. Tehát az egyik objektum közel van magához a cluster1-hez.
Hasonlóképpen, ha ellenőrizzük a (4, 3) objektumot, akkor az 1 fürt távolsága 3.61 és a 2. klaszterhez 2.83. Tehát az objektum (4, 3) a 2. fürtre vált.
Hasonlóképpen, ha megvizsgálja az objektumot (2, 1), akkor az 1. fürt távolsága 1, a 2. fürt pedig 0. Tehát ez az objektum a 2. fürtre vált.
Most a távolságértékük szerint csoportosítjuk a pontokat (objektumcsoportosítás).
G_0 =
| A | B | C | D | |
|---|---|---|---|---|
| 1 | 0 | 0 | 0 | csoport_1 |
| 0 | 1 | 1 | 1 | csoport_2 |
Most a távolságértékük szerint csoportosítjuk a pontokat (objektumcsoportosítás).
Végül a grafikon az alábbiak szerint fog kinézni a fürtözés elvégzése után (G_0).
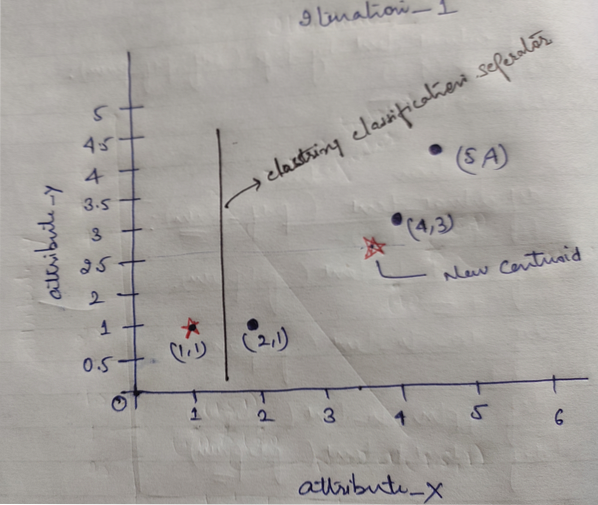
Iteráció_1: Most új centrideket fogunk kiszámolni, mivel a kezdeti csoportok megváltoznak a távolság képlete miatt, amint azt a G_0 mutatja. Tehát a group_1-nak csak egy objektuma van, így értéke továbbra is c1 (1,1), de a group_2-nak 3 objektuma van, tehát az új centroid értéke 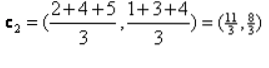
Tehát új c1 (1,1) és c2 (3.66, 2.66)
Most megint ki kell számolnunk az összes új távolságot az új centrumoktól, ahogyan korábban kiszámoltuk.
DM_1 =
| 0 | 1 | 3.61 | 5 | C1 = (1,1) klaszter1 | csoport_1 |
| 3.14 | 2.36 | 0.47 | 1.89 | C2 = (3.66,2.66) klaszter2 | csoport_2 |
| A | B | C | D | |
|---|---|---|---|---|
| 1 | 2 | 4 | 5 | x |
| 1 | 1 | 3 | 4 | Y |
Iteráció_1 (Objektumcsoportosítás): Az új távolságmátrix (DM_1) számításának nevében ennek megfelelően csoportosítjuk. Tehát áthelyezzük az M2 objektumot a_2 csoportról a_1 csoportra, a minimális távolság szabályaként a centridok felé, és az objektum többi része ugyanaz. Tehát az új klaszterezés az alábbiak szerint alakul.
G_1 =
| A | B | C | D | |
|---|---|---|---|---|
| 1 | 1 | 0 | 0 | csoport_1 |
| 0 | 0 | 1 | 1 | csoport_2 |
Most újra ki kell számolnunk az új centrideket, mivel mindkét objektumnak két értéke van.
Szóval, új centridák lesznek 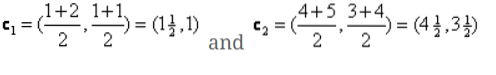
Tehát, miután megkapjuk az új centridákat, a klaszterezés az alábbiak szerint fog kinézni:
c1 = (1.5, 1)
c2 = (4.5, 3.5)
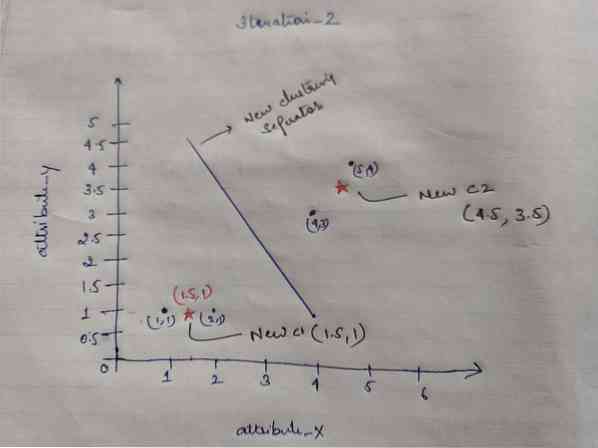
Iteráció_2: Megismételjük azt a lépést, ahol kiszámítjuk az egyes objektumok új távolságát az új számított centrumokhoz. Tehát a számítás után megkapjuk a következő távolságmátrixot az iterációhoz_2.
DM_2 =
| 0.5 | 0.5 | 3.20 | 4.61 | C1 = (1.5, 1) klaszter1 | csoport_1 |
| 4.30 | 3.54 | 0.71 | 0.71 | C2 = (4.5, 3.5) klaszter2 | csoport_2 |
A B C D
| A | B | C | D | |
|---|---|---|---|---|
| 1 | 2 | 4 | 5 | x |
| 1 | 1 | 3 | 4 | Y |
Ismét a csoportosítási feladatokat a minimális távolság alapján végezzük, mint korábban. Tehát ezt követően megkaptuk a fürtöző mátrixot, amely megegyezik a G_1-vel.
G_2 =
| A | B | C | D | |
|---|---|---|---|---|
| 1 | 1 | 0 | 0 | csoport_1 |
| 0 | 0 | 1 | 1 | csoport_2 |
Mint itt, G_2 == G_1, így nincs szükség további ismétlésre, és itt megállhatunk.
A K-Means megvalósítása Python használatával:
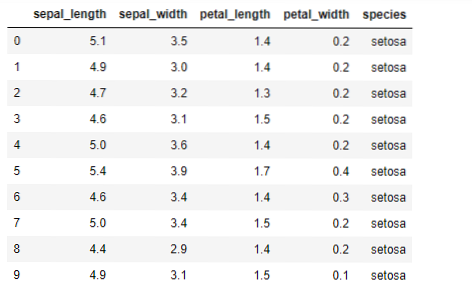
Most a K-mean algoritmust fogjuk megvalósítani a pythonban. A K-eszközök megvalósításához a híres Iris adatkészletet fogjuk használni, amely nyílt forráskódú. Ennek az adatkészletnek három különböző osztálya van. Ennek az adatkészletnek alapvetően négy jellemzője van: Sepal hossza, csészék szélessége, szirom hossza és szirma szélessége. Az utolsó oszlop megadja az adott sor osztályának nevét, mint a setosa.
Az adatkészlet a következőképpen néz ki:
A python k-mean megvalósításához importálnunk kell a szükséges könyvtárakat. Tehát importálunk Pandákat, Numpy-t, Matplotlib-et és a KMeans-ot is a sklearn-ből.az alábbiak szerint:

Az íriszt olvasjuk.csv adatkészlet a read_csv panda módszerével, és a top 10 eredményt jeleníti meg a head módszerrel.
Most csak az adatkészlet azon tulajdonságait olvassuk, amelyekre a modell betanításához szükségünk volt. Tehát az adatkészletek mind a négy jellemzőjét (sepal hossza, sepal szélessége, szirom hossza, szirma szélessége) olvassuk. Ehhez átadtuk a négy indexértéket [0, 1, 2, 3] a panda adatkeretének iloc funkciójába (df), az alábbiak szerint:
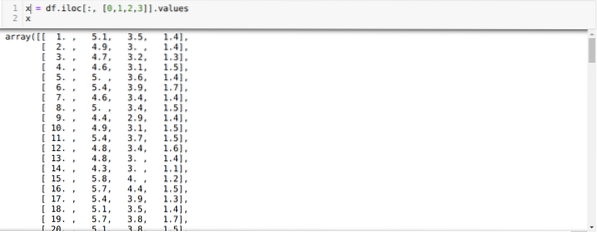
Most véletlenszerűen választjuk meg a klaszterek számát (K = 5). Létrehozzuk a K-átlag osztály objektumát, majd az x adatkészletet illesztjük az edzéshez és az előrejelzéshez az alábbiak szerint:
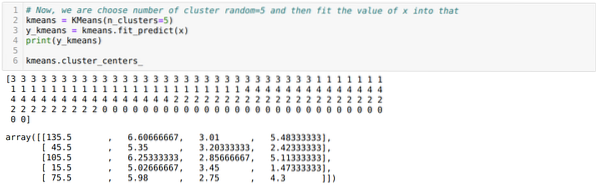
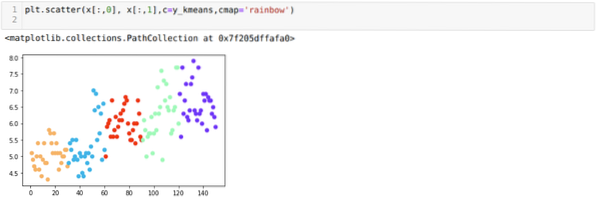
Most a véletlenszerű K = 5 értékkel vizualizáljuk a modellünket. Világosan láthatunk öt klasztert, de úgy tűnik, hogy nem pontos, amint az alább látható.
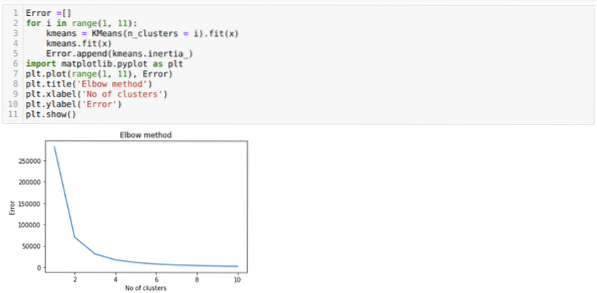
Tehát a következő lépésünk annak kiderítése, hogy a klaszterek száma pontos volt-e vagy sem. Ehhez pedig a Könyök módszert alkalmazzuk. A Könyök módszert használják a fürt optimális számának megismerésére egy adott adatkészlethez. Ezt a módszert fogjuk használni annak kiderítésére, hogy a k = 5 értéke helyes volt-e vagy sem, mivel nem kapunk egyértelmű klaszterezést. Tehát ezután a következő grafikonra lépünk, amely azt mutatja, hogy a K = 5 értéke nem helyes, mert az optimális érték 3 vagy 4 közé esik.
Most újra futtatni fogjuk a fenti kódot a K = 4 klaszterek számával az alábbiak szerint:
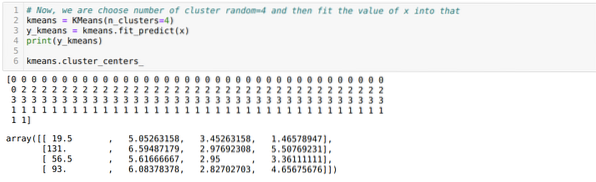
Most meg fogjuk jeleníteni a fenti K = 4 új építésű fürtöt. Az alábbi képernyőn látható, hogy most a fürtözés a k-eszközökön keresztül történik.
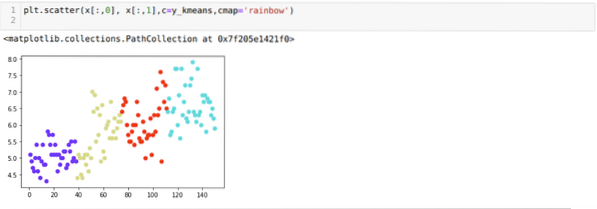
Következtetés
Tehát a K-átlag algoritmust tanulmányoztuk numerikus és python kódban egyaránt. Láttuk azt is, hogyan tudhatjuk meg egy adott adatkészlet fürtjeinek számát. Néha az Elbow módszer nem tudja megadni a megfelelő fürtök számát, ezért ebben az esetben többféle módszert választhatunk.


