A panda forgatótáblája használata előtt győződjön meg róla, hogy megérti adatait és kérdéseit, amelyeket megpróbál megoldani a forgatótáblán keresztül. Ezzel a módszerrel hatalmas eredményeket érhet el. Ebben a cikkben részletesen kifejtjük, hogyan lehet pivot táblázatot létrehozni a pandas pythonban.
Adatok olvasása az Excel fájlból
Letöltöttünk egy excel adatbázist az élelmiszerek értékesítéséről. A megvalósítás megkezdése előtt telepítenie kell néhány szükséges csomagot az Excel adatbázis fájlok olvasásához és írásához. Írja be a következő parancsot a pycharm szerkesztő terminál szakaszába:
pip telepítse az xlwt openpyxl xlsxwriter xlrd fájlt
Most olvassa el az adatokat az Excel lapról. Importálja a szükséges panda könyvtárakat, és változtassa meg az adatbázis elérési útját. Ezután a következő kód futtatásával adatokat lehet lekérni a fájlból.
import pandák, mint pdimportálja a numpy-t np-ként
dtfrm = pd.read_excel ('C: / Felhasználók / DELL / Asztal / foodsalesdata.xlsx ')
nyomtatás (dtfrm)
Itt az adatokat az élelmiszer-értékesítés excel adatbázisából olvassák le, és továbbítják az adatkeret változóba.
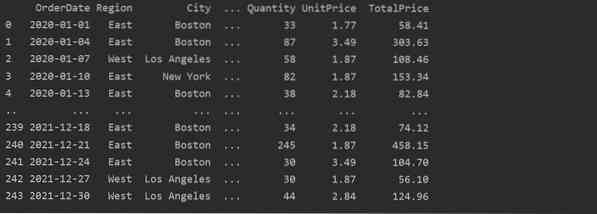
Hozzon létre Pivot-táblázatot a Pandas Python használatával
Az alábbiakban létrehoztunk egy egyszerű forgatótáblát az élelmiszer-értékesítési adatbázis felhasználásával. Két paraméter szükséges a kimutató tábla létrehozásához. Az első olyan adat, amelyet átadtunk az adatkeretnek, a másik pedig egy index.
Kimutatható adatok egy indexen
Az index egy olyan pivot tábla jellemzője, amely lehetővé teszi az adatok igények szerinti csoportosítását. Itt a „Product” -ot vettük indexként egy alapvető pivot-tábla létrehozásához.
import pandák, mint pdimportálja a numpy-t np-ként
adatkeret = pd.read_excel ('C: / Felhasználók / DELL / Asztal / foodsalesdata.xlsx ')
pivot_tble = pd.pivot_table (adatkeret, index = ["Termék"])
nyomtatás (pivot_tble)
Az alábbi eredmény a fenti forráskód futtatása után jelenik meg:
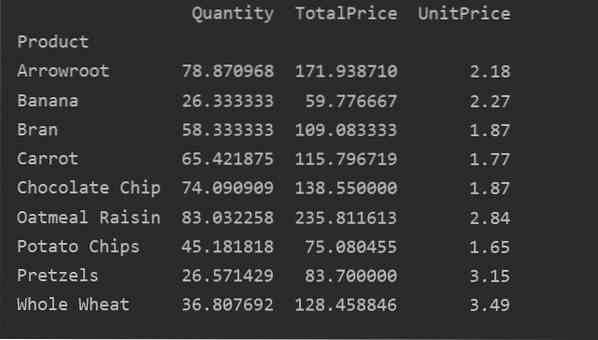
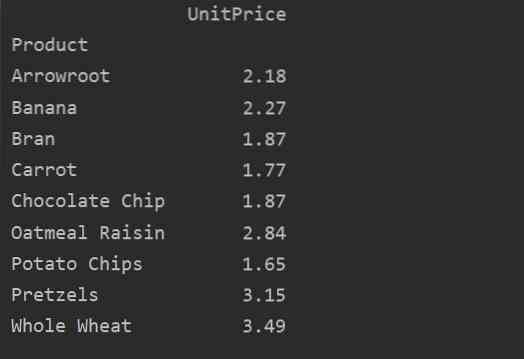
Pontosan definiálja az oszlopokat
Az adatok további elemzéséhez határozza meg kifejezetten az oszlopneveket az indexszel. Például az egyes termékek egyetlen UnitPrice-ját szeretnénk megjeleníteni az eredményben. Ehhez vegye fel az értékek paraméterét a kimutató táblázatba. A következő kód ugyanazt az eredményt adja:
import pandák, mint pdimportálja a numpy-t np-ként
adatkeret = pd.read_excel ('C: / Felhasználók / DELL / Asztal / foodsalesdata.xlsx ')
pivot_tble = pd.pivot_table (adatkeret, index = „Termék”, értékek = „Egységár”)
nyomtatás (pivot_tble)
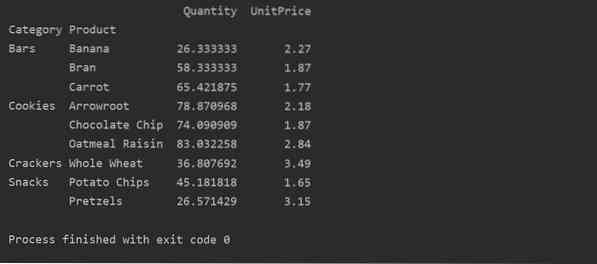
Pivot Data with Multi-Index
Az adatok indexként több tulajdonság alapján csoportosíthatók. A többindexes megközelítés használatával konkrétabb eredményeket kaphat az adatok elemzéséhez. Például a termékek különböző kategóriákba tartoznak. Tehát az egyes termékek „Termék” és „Kategória” indexét az elérhető „Mennyiség” és „Egységár” értékkel jelenítheti meg az alábbiak szerint:
import pandák, mint pdimportálja a numpy-t np-ként
adatkeret = pd.read_excel ('C: / Felhasználók / DELL / Asztal / foodsalesdata.xlsx ')
pivot_tble = pd.pivot_table (adatkeret, index = ["Kategória", "Termék"], értékek = ["Egységár", "Mennyiség"])
nyomtatás (pivot_tble)
Összesítési függvény alkalmazása a kimutatás táblában
Egy pivot táblában az aggfunc különböző tulajdonságértékekre alkalmazható. Az eredményül kapott táblázat a jellemző adatok összefoglalása. Az összesítő függvény a pivot_table csoport adataira vonatkozik. Az összesített függvény alapértelmezés szerint np.átlagos(). De a felhasználói igények alapján a különböző adatfunkciókhoz különböző összesítő függvények alkalmazhatók.
Példa:
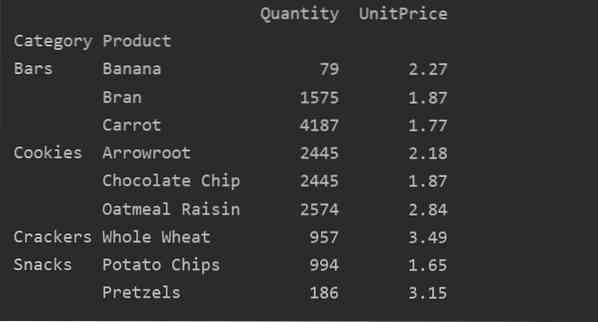
Ebben a példában összesített függvényeket alkalmaztunk. Az np.A sum () függvényt használjuk a 'Mennyiség' és az np paraméterekhez.mean () függvény az 'UnitPrice' szolgáltatáshoz.
import pandák, mint pdimportálja a numpy-t np-ként
adatkeret = pd.read_excel ('C: / Felhasználók / DELL / Asztal / foodsalesdata.xlsx ')
pivot_tble = pd.pivot_table (adatkeret, index = ["Kategória", "Termék"], aggfunc = 'Mennyiség': np.összeg, „UnitPrice”: np.átlagos)
nyomtatás (pivot_tble)
Miután az összesítési függvényt különböző funkciókra alkalmazta, a következő kimenetet kapja:
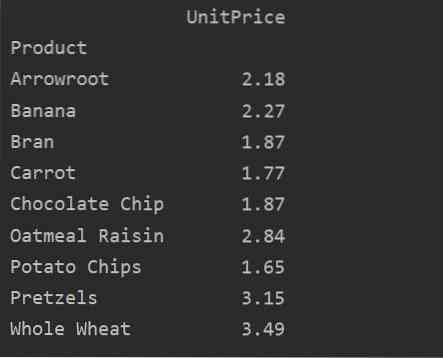
Az értékparaméter segítségével összesített függvényt is alkalmazhat egy adott szolgáltatáshoz. Ha nem adja meg a szolgáltatás értékét, akkor az összesíti az adatbázis számjellemzőit. A megadott forráskód követésével alkalmazhatja az összesítő függvényt egy adott szolgáltatáshoz:
import pandák, mint pdimportálja a numpy-t np-ként
adatkeret = pd.read_excel ('C: / Felhasználók / DELL / Asztal / foodsalesdata.xlsx ')
pivot_tble = pd.pivot_table (adatkeret, index = ['Termék'], értékek = ['Egységár'], aggfunc = np.átlagos)
nyomtatás (pivot_tble)
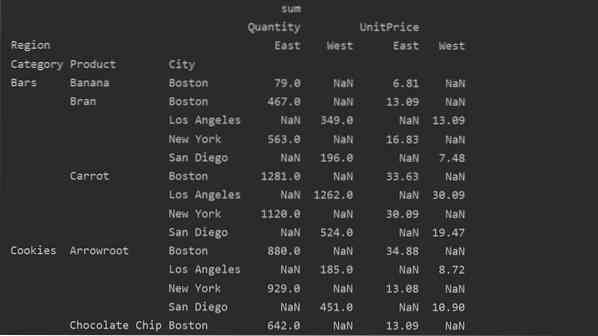
Különböző értékek vs. Oszlopok a kimutató táblázatban
Az értékek és az oszlopok a pivot_table fő zavaró pontja. Fontos megjegyezni, hogy az oszlopok nem kötelező mezők, amelyek a kapott táblázat értékeit vízszintesen a tetején jelenítik meg. Az aggfunc összesítési függvény a felsorolt értékek mezőjére vonatkozik.
import pandák, mint pdimportálja a numpy-t np-ként
adatkeret = pd.read_excel ('C: / Felhasználók / DELL / Asztal / foodsalesdata.xlsx ')
pivot_tble = pd.pivot_table (adatkeret, index = ['Kategória', 'Termék', 'Város'], értékek = ['Egységár', 'Mennyiség'],
oszlop = ['Régió'], aggfunc = [np.összeg])
nyomtatás (pivot_tble)
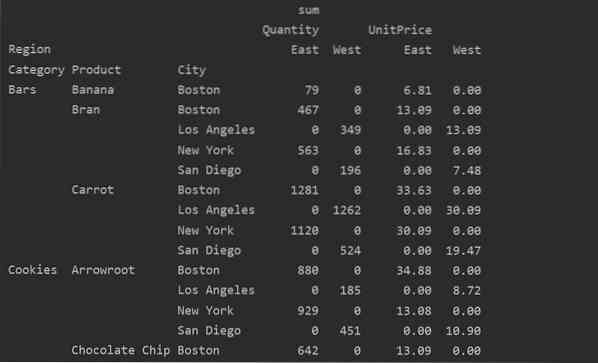
Hiányzó adatok kezelése a kimutató táblázatban
A Pivot táblázat hiányzó értékeit a 'kitöltési_érték' Paraméter. Ez lehetővé teszi, hogy kicserélje a NaN értékeket valamilyen új értékre, amelyet kitöltésre ad meg.
Például az összes null értéket eltávolítottuk a fenti eredménytáblázatból a következő kód futtatásával, és a NaN értékeket 0-ra cseréltük az egész eredménytáblában.
import pandák, mint pdimportálja a numpy-t np-ként
adatkeret = pd.read_excel ('C: / Felhasználók / DELL / Asztal / foodsalesdata.xlsx ')
pivot_tble = pd.pivot_table (adatkeret, index = ['Kategória', 'Termék', 'Város'], értékek = ['Egységár', 'Mennyiség'],
oszlop = ['Régió'], aggfunc = [np.összeg], kitöltési_érték = 0)
nyomtatás (pivot_tble)
Szűrés a kimutató táblázatban
Az eredmény létrehozása után alkalmazhatja a szűrőt a szokásos adatkeret funkció használatával. Vegyünk egy példát. Szűrje azokat a termékeket, amelyek UnitPrice értéke 60 alatt van. Megjeleníti azokat a termékeket, amelyek ára kevesebb, mint 60.
import pandák, mint pdimportálja a numpy-t np-ként
adatkeret = pd.read_excel ('C: / Felhasználók / DELL / Asztal / foodsalesdata.xlsx ', index_col = 0)
pivot_tble = pd.pivot_table (adatkeret, index = "Termék", értékek = "Egységár", aggfunc = "Összeg")
low_price = pivot_tble [pivot_tble ['UnitPrice'] < 60]
nyomtatás (alacsony ár)

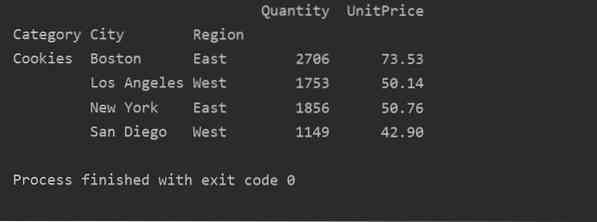
Más lekérdezési módszer használatával szűrheti az eredményeket. Például szűrtük a sütikategóriát a következő jellemzők alapján:
import pandák, mint pdimportálja a numpy-t np-ként
adatkeret = pd.read_excel ('C: / Felhasználók / DELL / Asztal / foodsalesdata.xlsx ', index_col = 0)
pivot_tble = pd.pivot_table (adatkeret, index = ["Kategória", "Város", "Régió"], értékek = ["Egységár", "Mennyiség"], aggfunc = np.összeg)
pt = forgatható_tábla.lekérdezés ('Kategória == ["Cookie-k"]')
nyomtatás (pt)
Kimenet:
Vizualizálja a kimutatási táblázat adatait
A pivot tábla adatainak megjelenítéséhez kövesse az alábbi módszert:
import pandák, mint pdimportálja a numpy-t np-ként
import matplotlib.pyplot mint plt
adatkeret = pd.read_excel ('C: / Felhasználók / DELL / Asztal / foodsalesdata.xlsx ', index_col = 0)
pivot_tble = pd.pivot_table (adatkeret, index = ["Kategória", "Termék"], értékek = ["Egységár"])
pivot_tble.telek (fajta = 'bár');
plt.előadás()
A fenti megjelenítésben megmutattuk a különböző termékek egységárát, kategóriákkal együtt.

Következtetés
Megvizsgáltuk, hogyan hozhat létre pivot táblázatot az adatkeretről a Pandas python használatával. Az elforduló tábla lehetővé teszi, hogy mély betekintést nyújtson az adatkészletekbe. Láttuk, hogyan lehet egy egyszerű pivot táblázatot létrehozni többindex segítségével, és hogyan kell alkalmazni a szűrőket a pivot táblákra. Ezenkívül kimutattuk a pivot tábla adatainak ábrázolását és a hiányzó adatok kitöltését is.


