Elasticsearch adatbázis
Az Elasticsearch az egyik legnépszerűbb NoSQL adatbázis, amelyet szöveges adatok tárolására és keresésére használnak. A Lucene indexelési technológián alapul, és lehetővé teszi a keresést milliszekundumokban az indexelt adatok alapján.
Az Elasticsearch webhelye alapján itt van a meghatározás:
Az Elasticsearch egy nyílt forráskódú, RESTful kereső és elemző motor, amely egyre több felhasználási eset megoldására képes.
Ez néhány magas szintű szó volt az Elasticsearchről. Itt értsük meg részletesen a fogalmakat.
- Megosztott: Az Elasticsearch a benne lévő adatokat több csomópontra osztja és felhasználja mesterszolga algoritmus belsőleg
- Nyugalmas: Az Elasticsearch támogatja az adatbázis-lekérdezéseket a REST API-k révén. Ez azt jelenti, hogy használhatunk egyszerű HTTP hívásokat, és használhatunk HTTP módszereket, például GET, POST, PUT, DELETE stb. az adatokhoz való hozzáféréshez.
- Keresési és elemzési motor: Az ES támogatja a nagyon elemző lekérdezéseket a rendszerben, amelyek összetett lekérdezésekből és többféle típusból állhatnak, például strukturált, strukturálatlan és földrajzi lekérdezések.
- Vízszintesen méretezhető: Ez a fajta átverés arra utal, hogy több gépet adjon hozzá egy meglévő fürthöz. Ez azt jelenti, hogy az ES képes több csomópontot fogadni a fürtjében, és nem biztosít leállási időt a rendszer szükséges frissítéséhez. Nézze meg az alábbi képet, hogy megértse a méretezési fogalmakat:
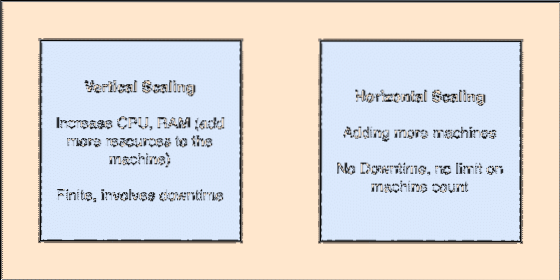
Függőleges és vízszintes siklás
Az Elasticsearch Database használatának megkezdése
Az Elasticsearch használatának megkezdéséhez telepíteni kell a gépre. Ehhez olvassa el az ElasticSearch telepítése az Ubuntun című cikket.
Győződjön meg róla, hogy aktív ElasticSearch telepítéssel rendelkezik, ha szeretné kipróbálni a lecke későbbi példáit.
Elasticsearch: Fogalmak és alkatrészek
Ebben a szakaszban megnézzük, hogy milyen elemek és fogalmak rejlenek az Elasticsearch szívében. Fontos megérteni ezeket a fogalmakat az ES működésének megértéséhez:
- Fürt: A fürt kiszolgáló gépek (csomópontok) gyűjteménye, amely az adatokat tárolja. Az adatok több csomópont között vannak felosztva, hogy megismételhetők legyenek, és az egyetlen kiszolgáló hiba (SPoF) nem történik meg az ES szerverrel. A fürt alapértelmezett neve: rugalmas keresés. A fürt minden csomópontja a fürthöz kapcsolódik egy URL-címmel és a fürt nevével, ezért fontos, hogy ezt a nevet külön és egyértelműen tartsuk.
- Csomópont: A csomópont-gép egy szerver része, és egyetlen gépnek nevezik. Tárolja az adatokat, és indexelési és keresési lehetőségeket biztosít a fürt többi csomópontjával együtt.
A vízszintes méretezés koncepciója miatt gyakorlatilag végtelen számú csomópontot adhatunk hozzá egy ES fürtbe, hogy sokkal több erőt és indexelési képességet kapjunk.
- Index: Az Index egy kissé hasonló jellemzőkkel rendelkező dokumentumgyűjtemény. Az Index nagyjából hasonlít egy SQL-alapú környezetben lévő adatbázishoz.
- típus: A Típust használják az adatok elválasztására ugyanazon index között. Például az Ügyféladatbázisnak / Indexnek több típusa lehet, például user, payment_type stb.
Vegye figyelembe, hogy a típusok elavultak az ES v6 verziótól.0.0-tól kezdve. Itt olvashatja el, miért tették ezt.
- Dokumentum: A dokumentum a legalacsonyabb szintű egység, amely adatokat képvisel. Képzelje el, mint egy JSON objektumot, amely az adatait tartalmazza. Az Indexen belül annyi dokumentumot lehet indexelni.
A keresés típusai az Elasticsearch alkalmazásban
Az Elasticsearch ismert a közel valós idejű keresési képességeiről és az indexelt és keresett adatok típusával biztosított rugalmasságáról. Kezdjük el tanulmányozni, hogyan kell használni a keresést különféle típusú adatokkal.
- Strukturált keresés: Ez a típusú keresés olyan adatokon fut, amelyeknek előre meghatározott formátuma van, például dátumok, idők és számok. Az előre meghatározott formátummal együtt jár a közös műveletek futtatásának rugalmassága, például egy dátumtartomány értékeinek összehasonlítása. Érdekes módon, a szöveges adatok is strukturálhatók. Ez akkor fordulhat elő, ha egy mezőnek fix számú értéke van. Például az adatbázisok neve lehet, MySQL, MongoDB, Elasticsearch, Neo4J stb. Strukturált keresés esetén az általunk futtatott kérdésekre a válasz igen vagy nem.
- Teljes szövegű keresés: Ez a típusú keresés két fontos tényezőtől függ, Relevancia és Elemzés. A Relevance segítségével meghatározzuk, hogy egyes adatok mennyire felelnek meg a lekérdezésnek, azáltal, hogy pontszámot határozunk meg a kapott dokumentumokhoz. Ezt a pontszámot maga az ES adja. Elemzés utal arra, hogy a szöveget normalizált tokenekre bontják, hogy fordított indexet hozzanak létre.
- Multifield Search: Mivel az analitikai lekérdezések száma folyamatosan növekszik az ES-ben tárolt adatokon, általában nem csak egyszerű egyeztetési lekérdezésekkel nézünk szembe. A követelmények növekedtek a több mezőt átfogó lekérdezések futtatásához, és az adatok pontozott rendezett listájával rendelkezik, amelyet maga az adatbázis küldött vissza nekünk. Így az adatok sokkal hatékonyabban jelen lehetnek a végfelhasználó számára.
- Proimity Matching: A lekérdezések ma sokkal többek, mint annak azonosítása, hogy egyes szöveges adatok tartalmaznak-e másik karakterláncot vagy sem. Arról van szó, hogy meg kell teremteni az adatok közötti kapcsolatot, hogy azokat pontozni lehessen, és hozzá lehessen illeszteni az adatok egyeztetésének kontextusához. Például:
- Labda eltalálta Johnt
- John eltalálta a labdát
- John vásárolt egy új labdát, amelyet Jaen kertje ért el
Az egyezési lekérdezés mind a három dokumentumot megtalálja, amikor rákeresnek Labda eltalált. A közelségi keresés megmondhatja, hogy ez a két szó milyen messze jelenik meg ugyanabban a sorban vagy bekezdésben, amely miatt megfeleltek.
- Részleges egyeztetés: Gyakran részleges egyeztetési lekérdezéseket kell futtatnunk. A Részleges egyeztetés lehetővé teszi számunkra, hogy olyan lekérdezéseket futtassunk, amelyek részben egyeznek. Ennek megjelenítéséhez nézzünk meg egy hasonló SQL alapú lekérdezést:
SQL lekérdezések: Részleges egyeztetés
WHERE név, mint "% john%"
ÉS nevezze meg, mint "% red%"
ÉS nevezze meg, mint "% garden%"Bizonyos esetekben csak részleges lekérdezéseket kell futtatnunk, akkor is, ha durva erő technikának tekinthetők.
Integráció a Kibanával
Amikor egy elemző motorról van szó, általában elemzési lekérdezéseket kell futtatnunk egy üzleti intelligencia (BI) tartományban. Ha üzleti elemzőkről vagy adatelemzőkről van szó, akkor nem lenne igazságos azt feltételezni, hogy az emberek tudnak egy programozási nyelvet, amikor meg akarják jeleníteni az ES klaszterben található adatokat. Ezt a problémát Kibana oldja meg. A Kibana annyi előnyt kínál a BI számára, hogy az emberek egy kiváló, testreszabható irányítópulttal valóban vizualizálhatják az adatokat, és inaktív módon láthatják az adatokat. Nézzük meg itt néhány előnyét.
Interaktív diagramok
A Kibana középpontjában az alábbi interaktív diagramok állnak: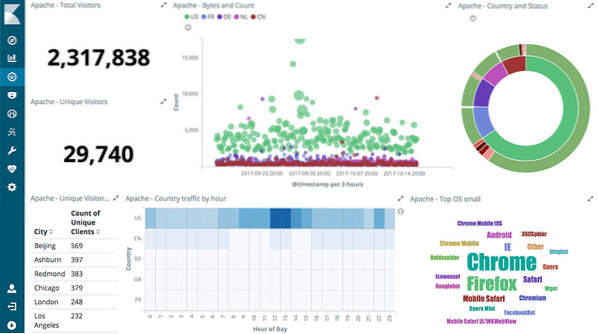
A Kibana különféle típusú diagramokkal támogatott, mint például kördiagramok, napsugarak, hisztogramok és még sok más, amely az ES teljes összesítési képességeit használja fel.
Térképészeti támogatás
A Kibana támogatja a teljes földrajzi összesítést is, amely lehetővé teszi számunkra, hogy földrajzilag feltérképezzük adatainkat. Hát nem klassz?!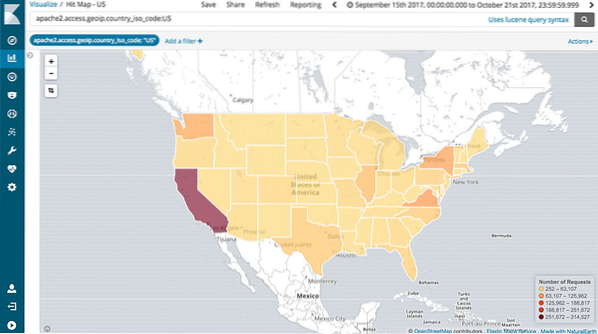
Előre elkészített összesítések és szűrők
Az előre felépített összesítések és szűrők segítségével szó szerint töredezetté teheti, eldobhatja és futtathatja a nagyon optimalizált lekérdezéseket a Kibana Irányítópulton belül. Csak néhány kattintással összesített lekérdezéseket futtathat, és eredményeket mutathat be interaktív diagramok formájában.
Az irányítópultok egyszerű elosztása
A Kibana segítségével az irányítópultokat sokkal szélesebb közönségnek is meg lehet osztani anélkül, hogy a műszerfalon bármilyen változtatást végeznénk a Csak a Műszerfal mód segítségével. Könnyedén beilleszthetünk irányítópultokat belső wikibe vagy weblapjainkba.
A Kibana termékoldalról készített képek.
Az Elasticsearch használata
A példány részleteinek és a fürt információk megtekintéséhez futtassa a következő parancsot: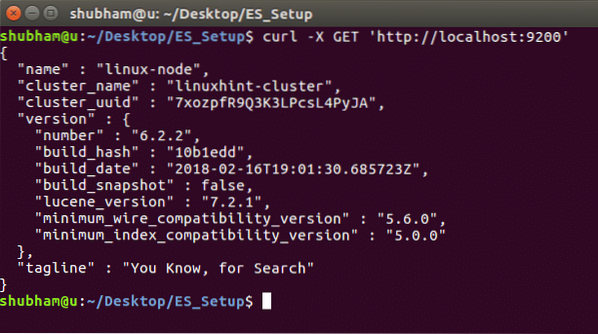
Most megpróbálhatunk beilleszteni néhány adatot az ES-be a következő paranccsal:
Adatok beszúrása
göndör-X POST 'http: // localhost: 9200 / linuxhint / hello / 1' \
-H 'Tartalomtípus: alkalmazás / json' \
-d '"name": "LinuxHint"' \
Íme, amit ezzel a paranccsal kapunk vissza:
Próbáljuk meg most megszerezni az adatokat:
Adatok megszerzése
curl -X GET 'http: // localhost: 9200 / linuxhint / hello / 1'A parancs futtatásakor a következő kimenetet kapjuk:
Következtetés
Ebben a leckében megvizsgáltuk, hogyan kezdhetjük el az ElasticSearch használatát, amely kiváló Analytics motor, és kiváló támogatást nyújt a valós idejű, szabad szöveges kereséshez is.


